每天烧 120 万亿 Token:机器流量反噬,App如何防刷量?
 openinstall运营团队|
openinstall运营团队| 2026-04-06|
2026-04-06| 413
413
2026年4月2日,在火山引擎 AI 创新巡展武汉站上,一组堪称“凡尔赛”的数据引爆了科技圈:豆包大模型的日均 Token(词元)调用量已正式突破 120 万亿大关。这个数字在过去短短三个月内翻了一倍,相比 2024 年 5 月刚发布时,更是暴涨了整整 1000 倍。

单日 120 万亿 Token 是什么概念?按目前市场主流的算力成本粗略估算,这意味着每天有价值数千万乃至上亿元的真金白银在 GPU 阵列中熊熊燃烧。当大厂们都在为其高昂的 API 调用流水和“万亿俱乐部”企业客户数量欢呼时,这组天文数字却给移动互联网的另一端——广大 App 的开发者和运营增长团队,投下了一道令人不寒而栗的巨大阴影:这 120 万亿 Token 的背后,代表着海量的 AI 智能体(Agent)和自动化脚本正在全网以远超人类极限的速度狂奔。当这些不知疲倦的机器流量以脉冲式的并发洪峰打向你的 App 注册入口和买量归因接口时,你的反作弊防线能扛得住吗?
新闻与环境拆解
要理解这 120 万亿 Token 对 App 流量生态的毁灭性冲击,我们需要拆解大模型使用场景的底层质变。
从“对话聊天”到“任务执行”的 Token 爆炸
在 ChatGPT 刚问世的“聊天时代”,用户的一问一答通常只会消耗几百到几千个 Token。然而,随着以 OpenClaw 为代表的系统级 Agent(智能体)火爆出圈,Token 的消耗逻辑发生了根本性的逆转。 一个成熟的 Agent 在执行复杂任务(如:“帮我抓取全网竞品的最新拉新活动并自动注册测试账号”)时,它会自主进行意图拆解、规划路径、调用系统浏览器、填写表单、甚至遇到图形验证码时调用视觉模型进行识别并自我纠正重试。这期间的每一个微小动作,都在后台向云端疯狂发送 API 请求。一个任务跑下来,其 Token 消耗量是普通人类对话的几十倍甚至上百倍。
算力涨价潮与黑灰产的“鸟枪换炮”
伴随着巨量 Token 消耗的,是上游算力资源的极度紧缺。近期,智谱、阿里云、百度智能云乃至海外的 AWS,不约而同地宣布了最高达 30% 甚至 100% 的 AI 产品涨价方案。 在这样的背景下,对商业利益嗅觉最敏锐的黑灰产工作室也完成了“鸟枪换炮”的产业升级。他们不再雇佣廉价的“人肉水军”,也不再使用低级的简单脚本,而是全面接入了廉价开源大模型或企业级 Agent 的 API。利用大模型的逻辑推理和多模态视觉能力,黑灰产可以轻易绕过 App 设置的各类复杂滑动验证码、反爬机制和设备特征检测,以极低的边际成本,向那些正在砸钱搞“CPA拉新”、“邀请有奖”的 App 发起极高频的自动化攻击。

从新闻到用户路径的归因问题
当 120 万亿 Token 催生出漫山遍野的“高智商机器大军”时,App 团队在买量漏斗顶端面临的归因与风控形势,已经从“冷兵器时代”直接跨入了“降维打击的核子时代”。
在传统的买量漏斗中(广告展示 -> 点击 -> 下载激活 -> 注册转化),运营人员通常依靠设备 ID(如 IMEI、IDFA)和 IP 地址来剔除重复或恶意的点击。 但现在,当一股由 AI Agent 驱动的“任务流量”涌入时,整个漏斗的可见度彻底变成了盲区:
-
深度伪造的点击与留存:现代黑灰产脚本在 AI 的加持下,不仅能瞬间生成成千上万个伪造的合法设备指纹,还能根据大模型生成的“拟人化剧本”,在 App 内模拟真实的页面停留、上下滑动、甚至产生无意义的聊天和点击交互。传统的基于简单规则的反作弊系统会将这些“高活跃度”的机器认定为优质的真实用户。
-
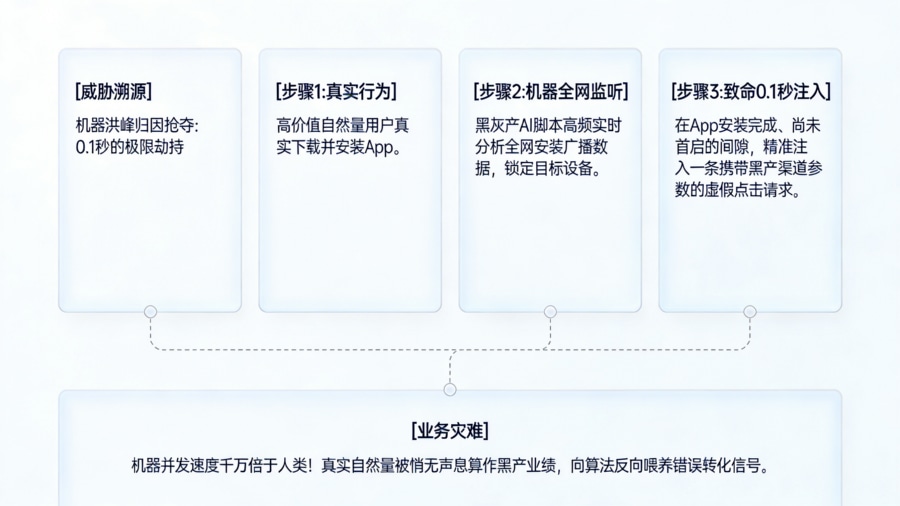
归因抢夺(点击劫持):在自然流量用户真实下载并安装 App 的间隙,黑灰产通过大模型实时分析全网的安装广播数据,并在最后的 0.1 秒内精准注入一条带有自己渠道参数的虚假点击。由于这股“机器流量”的反应速度和并发量是人类的千万倍,广告主花重金买来的真实自然量,就这样被悄无声息地归因到了黑产的头上。
如果 App 的后台依然是个敞口的“管道”,这股裹挟着海量虚假转化指标的机器洪峰,将瞬间洗劫企业的拉新预算池,并向推荐算法反向喂养错误的转化信号,最终导致真正的优质流量渠道被劣币驱逐,App 陷入“花钱越多,死得越快”的死循环。
工程实践:重构安装归因与全链路统计
面对 AI 时代武装到牙齿的机器流量反噬,App 团队必须摒弃在客户端“单点设防”的侥幸心理,从工程底层引入高维度的 体系,用端云结合的技术壁垒死守归因防线。
启用双重匹配机制,构建防伪溯源通道
-
问题:面对 AI 脚本瞬间生成的成千上万个伪造新设备特征,传统的依赖单一落地页参数或客户端硬编码的归因方式极易被破解抓包。
-
做法:在接入成熟的 基建时,必须强制实施 渠道编号(ChannelCode)的双重匹配逻辑: 其一,落地页匹配的模糊指纹升级。当未知的“流量”访问 H5 落地页时,前端引擎除了采集常规的 UA、IP,更要深入采集设备屏幕渲染刷新率、Canvas 绘图特征、WebGL 硬件信息等数百个极难被模拟器或 AI 脚本完美伪造的非标特征,生成“模糊指纹”并上云。当 App 激活时,云端引擎再将这些高维特征进行复杂的交叉碰撞比对。 其二,接口直传匹配的安全验证。对于头部媒体和超级 Agent 的 API 调度引流,坚决要求对方在触发请求时,通过 S2S(服务器到服务器)的底层加密接口直接回传 ChannelCode 与动态时间戳。App 激活时的归因对账,完全在开发者可控的云端黑盒内闭环完成。
-
好处:这种双重校验将风控逻辑强行拉到了大模型也难以轻易触达的硬件物理底层和云端黑盒中。不论机器脚本如何伪造点击和客户端接口,只要它无法在云端通过高维指纹的聚类审查,就统统被判定为无效来源,直接拒之门外。

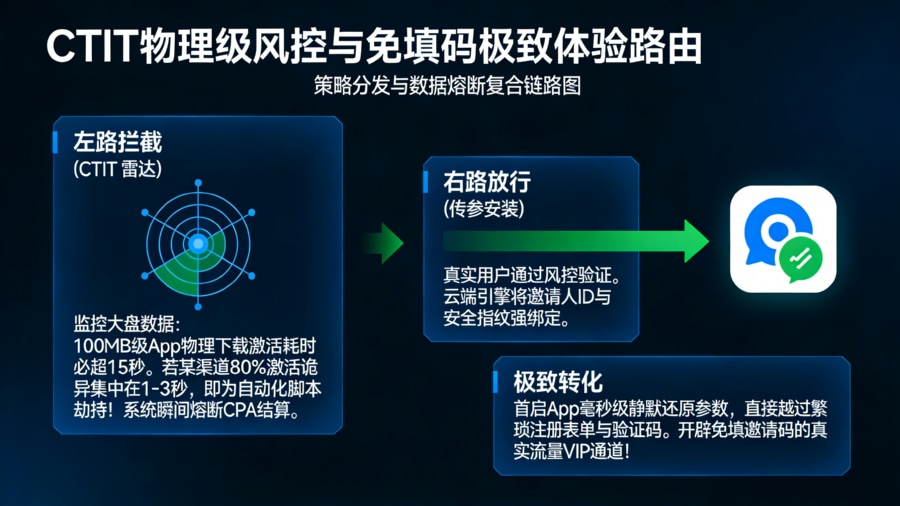
CTIT 物理级风控,斩断自动化归因劫持
-
问题:哪怕 AI 脚本伪装得再像人,它在执行“点击注入”抢夺归因时,也无法违背现实世界的物理网络规律。
-
做法:必须在归因看板中启用 CTIT(Click-to-Install Time,点击至激活时间)分布异常监控。 任何一款几十上百兆的 App,真实用户从点击广告到最终打开 App 激活,必然存在十几秒甚至几分钟的物理下限时间。如果防作弊系统监测到,某一个买量渠道回传的激活数据中,有 80% 以上的时间差都集中在不可思议的 1-3 秒内(或者是平滑得毫无波澜的正态曲线),这绝对是高并发的自动化脚本在后台实施的点击劫持。
-
好处:CTIT 监控犹如一面照妖镜,它不看你脚本写得有多智能,只看你的行为是否符合物理常识。一旦触发极速时间差的熔断阈值,系统将立刻拦截该批次流量的 CPA 结算,保护企业的资金安全。
智能传参安装,保障真实优质流量的极致体验
-
问题:在用严苛的反作弊规则清洗掉海量机器流量后,对于那些历经层层漏斗成功下载 App 的真实人类用户,如何保障他们的体验不再被繁琐的验证码和注册表单折磨?
-
做法:利用 技术。将邀请人的身份 ID、活动场景参数等核心信息,与前述通过了风控校验的安全云端指纹进行强绑定。当真实用户首次冷启动 App 时,客户端 SDK 在毫秒级内从云端静默拉取并还原这些参数。
-
好处:在最严密的防守之下,依然为真实用户开辟了一条“免填邀请码”、直达核心业务场景的 VIP 通道。既防住了机器薅羊毛,又将高价值自然流量的拉新转化率压榨到了极致。
这件事和开发 / 增长团队的关系
面对 120 万亿 Token 带来的机器流量海啸,团队内部必须建立起对流量质量的极度敬畏感:
面向开发 / 架构
必须将反作弊和归因的核心逻辑全面上移至云端。在客户端层面,要大幅减少敏感参数(如明确的 channel_code 或风控判定规则)的明文暴露,改用动态加密的 Token 进行通信。此外,在部署参数还原接口时,需设计高可用性的容灾和指数退避重试策略,防止在遭遇真正的黑产高并发攻击时,因瞬间的数据库读写压力导致自家的归因服务器“内网宕机”。
面向产品 / 增长
负责花钱买量和策划裂变活动的操盘手,必须彻底打破“唯激活数论”的虚假 KPI。面对某些小众渠道或新接入网盟给出的极低 CPA 成本和畸高转化率,必须保持十二分的警惕。强制要求将防刷量系统输出的“CTIT 异常率”和“指纹同质化占比”作为与渠道商对账、结算的刚性扣减条件。同时,将归因漏斗的监控节点向后延伸,把“次日留存”、“首次有效交易(产生实际流水)”作为衡量渠道质量的最终试金石。

常见问题(FAQ)
为什么 AI Agent 的普及会导致 App 面临更严重的作弊流量?
在过去,黑灰产工作室制造虚假流量主要依靠“人力点击农场”或编写死板的自动化脚本。这些脚本一旦遇到 App 前端稍微改动一下 UI 布局,或者加入复杂的图形滑块验证码,就会立刻瘫痪。而现在,接入了诸如 GPT-5.4 或豆包等大模型的 Agent,具备了强大的屏幕视觉理解和逻辑推理能力。它们能像真人一样“看懂”页面、自动破解验证码,甚至能根据上下文生成毫无破绽的用户昵称和聊天记录。这种由高智商 AI 驱动的自动化攻击,成本极低且极难被传统的风控规则识破。
既然机器流量能模拟用户行为,CTIT 监控为什么还能生效?
因为 CTIT 监控抓的不是“模拟操作”,而是物理世界的“时间差悖论”。黑灰产为了窃取真实用户的自然下载量(骗取广告主的拉新佣金),他们最惯用的手法是“安装广播劫持”——即在手机后台监听系统,一旦发现真实用户下载完毕正在安装 App,脚本就瞬间发送一条伪造的广告点击给归因服务器。由于这条假点击是跟着安装动作同步发出的,它距离 App 的最终激活往往只有 1-2 秒的时间差。这在真实的网络下载和解压流程中是绝对做不到的,因此,只要 CTIT 的时间差逼近物理极限,就必定是机器抢发的劫持作弊。
App在接入反作弊SDK时,如何判断它会不会过度采集用户的隐私数据?
在当前的强隐私监管(如苹果 ATT 框架及安卓隐私新规)红线内,专业的全渠道统计与反作弊服务早已摒弃了强制索取 IMEI、MAC 地址、通讯录等敏感硬性隐私的粗暴做法。目前主流且合规的“模糊指纹”技术,主要是在 H5 落地页和 App 冷启动时,通过采集系统微内核版本、屏幕分辨率、硬件渲染特征等不包含个人身份标识的软性脱敏特征,上报云端进行高维聚类比对。这种端云结合的算法匹配,既能精准锁定作弊群控设备,又完全满足应用上架时的合规隐私审核要求。
行业动态观察
当火山引擎骄傲地宣布豆包大模型日均 Token 调用量突破 120 万亿时,它不仅代表着 ,更向全网宣告:一个由海量算法、脚本和智能体主导的自动化交互时代已经全面降临。在算力价格持续上涨、AI 能力无限逼近甚至超越普通人类操作的今天,数字世界里的流量池已经变得浑浊不堪。