




日本AI造假,套壳DeepSeek:买量反作弊该怎么做?
 2026-03-18
|
2026-03-18
|
 202
202
号称“日本最强、国内最大规模”的 Rakuten AI 3.0 大模型在发布不到 12 小时后,便被技术社区扒出其底层架构完全是 DeepSeek V3 的“套壳”换皮版。这场企图用开源项目包装成“自主研发”的闹剧,揭示了数字世界中“伪装与隐匿”的低成本与高欺骗性。将视线转至 App 推广领域,这种“套壳伪装”的黑灰产逻辑同样每天都在真实上演——当买量渠道充斥着通过修改参数、伪装环境的机器设备时,App 增长团队该如何刺破流量的伪装外衣,构建坚固的反作弊风控体系?
新闻与环境拆解
在乐天集团(Rakuten)高调发布的 Rakuten AI 3.0 官方新闻稿中,该模型被包装为拥有约 7000 亿参数、融合了“开源社区精华”的混合专家(MoE)本土巨头。然而,开源社区在 Hugging Face 上的代码配置文件中发现,其核心指标包括总参数量(671B)、激活参数量(37B)与 DeepSeek V3 完全一致。
[插入位置:代码块 1]
为了掩饰套壳行为,乐天团队甚至在初期删除了 DeepSeek 极度宽容的 MIT 开源协议文件,强行将其更换为 Apache 2.0 协议以构建所谓的技术护城河。这种试图抹除底层溯源标记、通过修改上层配置来骗取信任与流量(乃至日本经产省 GENIAC 项目资助)的手法,在 App 买量生态中有一个极其相似的对应物:设备农场与流量黑产。它们通过篡改底层系统参数、伪装 IP 与设备指纹,将廉价的脚本操作“套壳”包装为高价值的真实用户点击与激活,以此套取广告主的巨额推广预算。
从新闻到用户路径的归因问题
在 App 的买量推广链路中,一个真实用户的转化通常经历:曝光 → 点击广告 → 跳转应用商店下载 → 首次打开激活。这原本是一条清晰的转化漏斗。然而,当黑灰产介入后,这条路径变成了一个充满欺诈的数据黑盒。
在利益的驱使下,作弊渠道往往利用群控软件、模拟器或 Xposed 框架等工具,对移动设备进行“深层套壳”。他们可以轻易抹除或伪造 IMEI、MAC 地址、操作系统版本等硬件标识,甚至通过动态 IP 代理池让每一次模拟点击都看起来来自不同的真实地理位置。由于传统的归因系统高度依赖这些静态参数进行去重和溯源,一旦设备完成“套壳换皮”,归因系统就会被误导,将这些由脚本自动触发的虚假安装判定为真实的新增用户。这不仅导致归因漏斗在激活环节发生严重的数据失真,更让增长团队的买量预算直接流向了毫无生命周期的作弊渠道。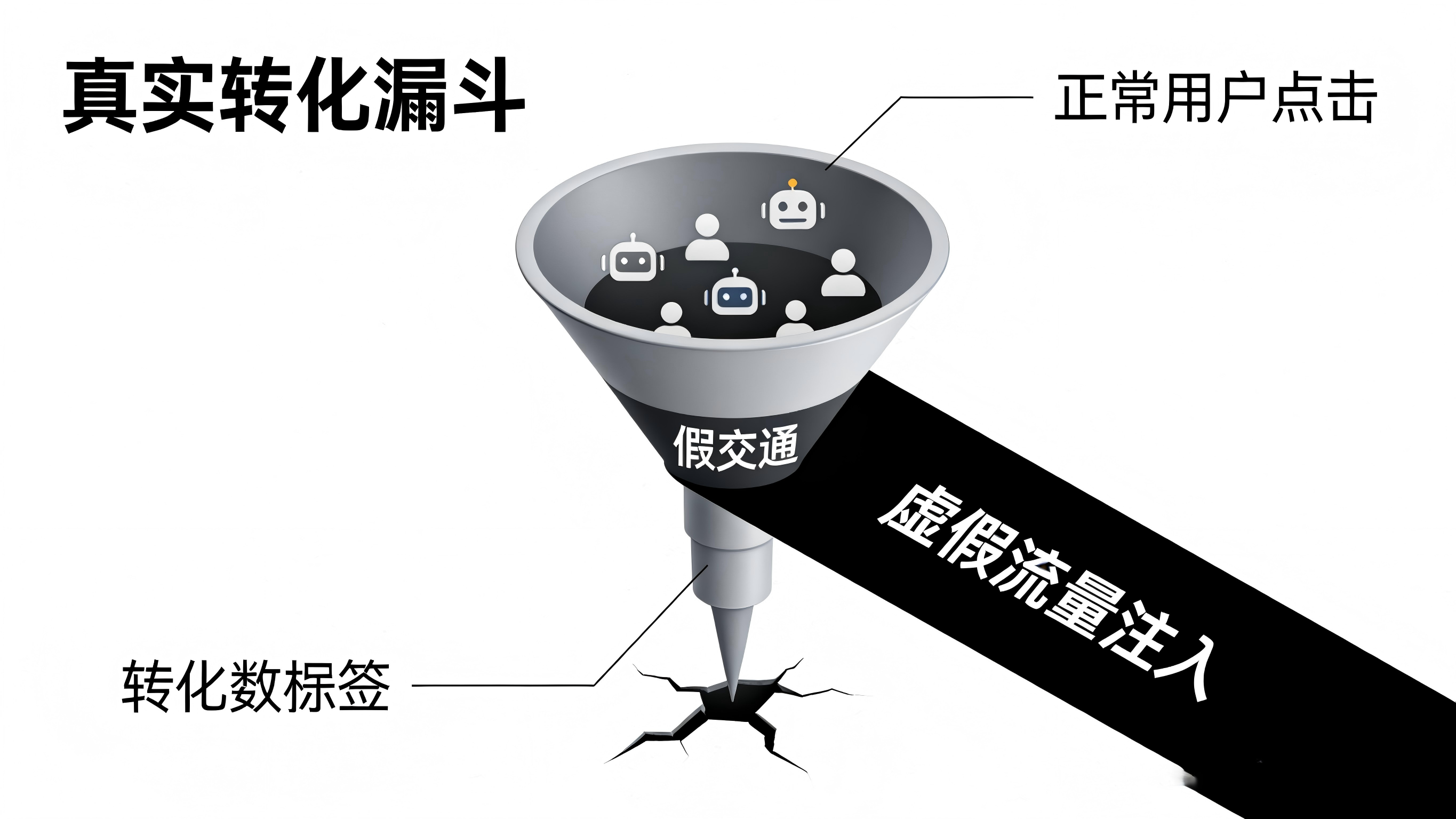
工程实践:重构安装归因与全链路统计
面对精心伪装的作弊流量,业务团队必须摒弃对表面静态参数的依赖,通过多维动态特征与行为逻辑的交叉验证,建立高维度的反作弊壁垒。
基于CTIT时序分析的异常拦截
问题:黑灰产可以修改设备参数进行“套壳”,但往往难以完美模拟人类在点击广告、等待下载、安装完成这一过程中的真实时间消耗。
做法:在归因引擎中引入深度的点击到激活时间差(CTIT)分析模型。通过全渠道统计与底层监测能力,实时计算每一次激活与其对应点击之间的时间间隔。如果某个渠道出现大量秒级激活(如预下载包瞬间唤醒)或过于规律的批量延时激活,系统将自动触发风控熔断。
带来的好处:不依赖易被篡改的设备标识符,直接从物理操作逻辑的维度识破机器脚本的伪装,有效过滤利用劫持或自动化刷量产生的虚假数据。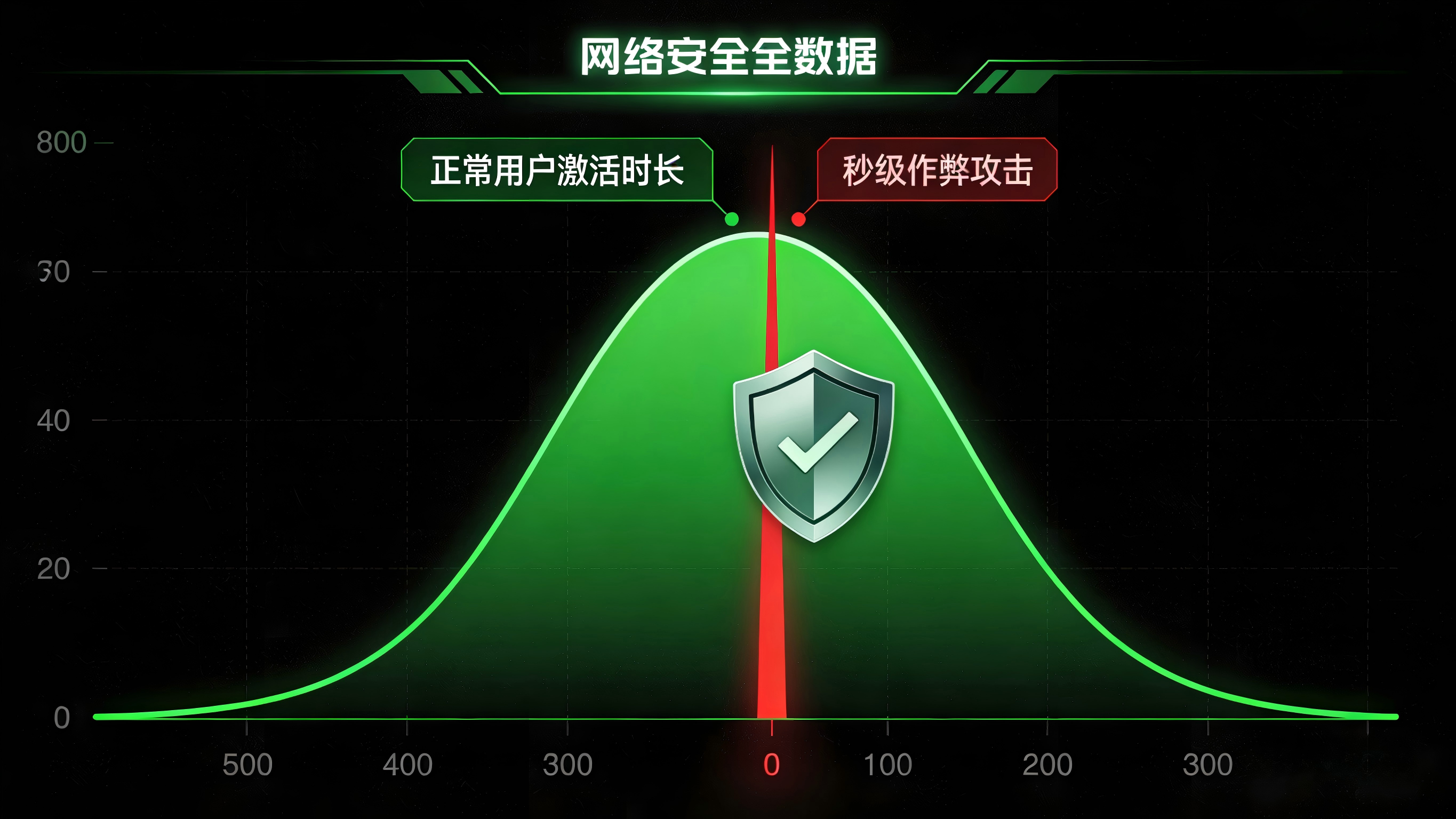
多维动态特征交叉的网络风控
问题:作弊团队利用海量代理 IP 和不断重置的系统沙箱,制造出看似来源分散的“全新设备”,绕过基础的 IP 黑名单策略。
做法:建立立体的反作弊过滤网,不再单一核对 IP 地址,而是结合网络频段、基站跳变、基础环境公开信息的聚集度进行多维交叉校验。对于在极短时间内从同一下级网段涌入的大量高并发请求,结合传感器静止状态等辅助参数进行综合研判,自动将其降级或判定为无效流量。
带来的好处:穿透黑灰产复杂的网络代理与设备伪装层,在流量进入转化漏斗前实现精准清洗,保障后续 ROI 评估的数据纯净度。
这件事和开发 / 增长团队的关系
面向开发与架构团队:在接入第三方统计与归因 SDK 时,研发人员需要明确,防作弊能力不再是业务边缘的点缀,而是底层数据架构的核心基建。开发团队应配合部署具备动态加密防重放机制的接口,防止黑产直接通过抓包伪造激活请求;同时,需预留灵活的风控上报节点,确保客户端环境特征能够安全、完整地送达云端校验。
面向产品与增长团队:运营逻辑需从“追求表象的新增规模”转向“死守真实的转化质量”。增长团队必须习惯在过滤掉水分的真实报表中进行渠道评估。面对某些账面数据异常华丽、获客成本极低但次日留存近乎为零的渠道,要敏锐察觉其“套壳作弊”的本质,果断切断预算,将资金集中投入到能够带来真实后续行为(如注册、付费)的高价值渠道中。
常见问题(FAQ)
为什么传统的设备去重策略对“套壳”作弊失效?
传统的去重策略高度依赖对设备唯一标识符(如 IMEI、IDFA)的精准匹配。而现代黑灰产掌握了底层的抹机技术与参数篡改工具,可以轻易为同一台物理设备生成无数个合法的虚拟身份凭证,这使得基于静态参数的简单比对形同虚设。
开启高强度的风控拦截会误伤真实用户吗?
现代商业级反作弊系统并不依赖单一维度的粗暴拦截,而是采用基于时间序列、网络聚集度与动态环境特征的交叉验证模型。在实际工程落地中,这种综合性研判能够极其精准地锁定不符合人类物理规律的机器并发行为,对正常点击下载的真实用户几乎是无感且零误伤的。
发现买量渠道存在作弊嫌疑后,第一时间该如何应对?
一旦通过数据报表或 CTIT 分布发现渠道异常,应立即在后台调整该渠道的风控过滤等级,并利用全链路数据向下追溯这些用户的后续转化指标(如付费率)。在确认无真实商业价值后,需迅速停止该渠道的投放,并提取相关的异常 IP 与特征样本加入专属黑名单库,以防其“换皮”后再次潜入。
行业动态观察
从乐天 AI 模型套壳 DeepSeek 遭到技术社区的无情揭露,到移动端防作弊技术的持续迭代,行业正在释放一个明确的信号:在这个技术开源与工具高度发达的时代,企图通过简单伪装和信息差来套取红利的模式已经举步维艰。无论是在大模型的国际竞赛中,还是在 App 激烈的流量博弈场上,虚假的表象终将被数据底层的真实逻辑所戳穿。
对于所有参与数字经济的 App 开发者而言,放弃对虚假繁荣的执念,搭建真正透视流量本质的归因基建,才是长期主义的唯一解。在这个由数据驱动增长的存量时代,只有用最严谨的反作弊体系撕开作弊流量的伪装外衣,企业才能在每一次买量投放中守住利润,实现真正的良性增长。







 闽公网安备35058302351151号
闽公网安备35058302351151号








