谷歌Gemma 4开源引发本地部署热:终端孤岛,App如何保卫归因链路?
 openinstall运营团队|
openinstall运营团队| 2026-04-07|
2026-04-07| 226
226
2026年4月3日,谷歌 DeepMind 正式丢出了一枚重磅炸弹:新一代多模态大模型 Gemma 4 系列全面开源,且罕见地采用了极其商业友好的 Apache 2.0 许可证。在高达 310 亿参数的旗舰版登顶开源榜单第三的同时,真正引发行业地震的,是其专门针对“端侧部署”优化的 E2B(23亿有效参数)和 E4B(45亿有效参数)微型版本。
这两款小模型不仅被极其极致地压缩了内存占用(E2B 可压至 1.5GB 以下),更在谷歌与高通、联发科的底层芯片级优化下,能够完全脱离云端网络,在智能手机、树莓派等边缘设备上进行离线的高级推理、语音识别与 Agent(智能体)任务调度。
当极其聪明的 AI 能够完全在用户的手机本地“闭门造车”时,一个被称为“端侧 AI(On-Device AI)”的时代正式拉开帷幕。但对于广大依赖流量流转与数据追踪的 App 开发者而言,这却是一个令人背脊发凉的信号:如果未来用户的搜索、决策和跨应用调度全部被本地的“系统级 AI”截胡并在沙盒内消化,手机将变成一个个绝对隔离的“数据孤岛”。 当云端失去了对流量轨迹的全局视角,传统的点击跳转和归因追踪将面临彻底失效。App 该如何利用底层的跳转与穿透技术,在端侧 AI 时代保卫自己的拉新漏斗与归因链路?
新闻与环境拆解
要看清 Gemma 4 带来的这场“终端革命”对移动应用生态的深远影响,我们必须拆解端侧 AI 的运行逻辑及其对传统中心化分发模式的颠覆。
端侧 AI:切断云端“上帝视角”的终极利器
在过去的大模型时代(如 ChatGPT 或早期的云端大模型 App),用户的所有意图(打车、订餐、查攻略)都需要将文本或语音上传至云端服务器。云端不仅掌控了算力,更垄断了数据,是所有流量分发的绝对中心。 而 Gemma 4 E2B/E4B 的出现打破了这一格局。它们被直接嵌入到手机的操作系统或本地私有应用中。这意味着,当用户对着手机说“帮我对比一下 A 平台和 B 平台哪家的咖啡更便宜,并直接下单”时,这个复杂的意图拆解和比价过程,完全在手机本地芯片的 NPU(神经网络处理器)上瞬间完成,期间不会向任何云端服务器发送数据请求。 云端的广告平台和统计系统,将彻底失去追踪用户决策前置路径的“上帝视角”。

本地 Agent 接管跨应用调度
Gemma 4 原生支持函数调用(Function Calling),并配套了开源的 Agent 框架(ADK)。这意味着端侧 AI 可以化身为一个无所不能的“超级管家”。 在传统的移动互联网中,App 之间的跳转是由用户手动点击 H5 链接或广告卡片触发的。而在端侧 Agent 的主导下,跳转变成了“AI 替人执行”。比如,本地 AI 在阅读完一篇种草文章后,判断用户有购买意图,便会在后台静默解析内容,然后直接通过系统底层指令去唤起某个电商 App 并传入商品参数。这种非标准的、由机器发起的跨应用唤起,将彻底击穿传统基于 Web URL 的跳转追踪机制。
从新闻到用户路径的归因问题
当手机终端演变成一个个绝对封闭的“AI 孤岛”,端侧 Agent 取代了用户的双眼和手指成为跨应用调度的真正执行者,App 团队在拉新、促活与渠道归因上面临的,将是灾难性的“断链”与“盲盒”。
在传统的云端分发生态中,一个标准的用户转化路径是: 点击信息流广告(云端记录点击流与 IP) -> 跳转应用商店(云端记录下载) -> 激活 App(客户端上报,云端比对归因)。
但在端侧 AI 接管流量后,路径发生了严重变异:
-
流量来源被“本地沙盒”吞噬:当用户的本地 AI 助手(例如基于 Gemma 4 打造的私人助理)在后台根据用户的离线指令,自动向微信发送了一条带有特定参数的分享链接,或者直接唤起了某个 O2O 应用。由于整个决策和发起过程都在本地断网发生,没有任何云端的点击宏(Click Macro)或追踪链接(Tracking Link)介入,目标 App 收到唤醒请求时,根本无法分辨这是用户真实的自主操作,还是某个本地脚本的自动化行为,导致“自然量”和“营销量”的界限被彻底模糊。
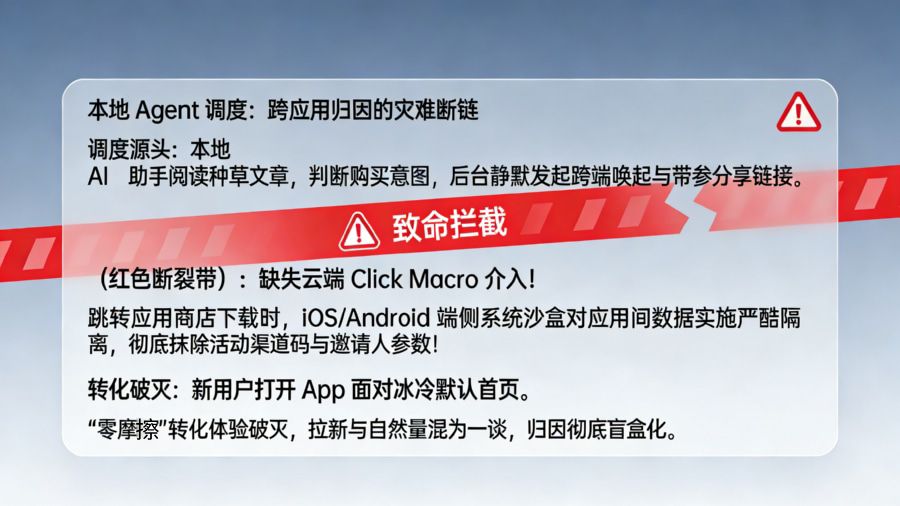
-
跨应用参数传递的“真空地带”:如果是用户好友的本地 Agent 生成了一张极具个性化的拉新海报或短链。当新用户点击这个链接并跳转至应用商店下载时,由于端侧操作系统(尤其是升级了底层隐私防护的 iOS 和 Android 系统)对应用间数据共享的严酷隔离,原本附带在链接中的“邀请人 ID”、“活动渠道码”等业务参数,在经过本地浏览器、系统跳转和商店下载的层层沙盒后,将被彻底抹除。
-
“零摩擦”体验的破灭:当新用户满怀期待地打开刚刚下载的 App,本以为能直接看到那个本地 AI 极力推荐的商品页面,却发现自己面对的依然是一个冰冷、空白的默认首页,甚至被要求手动去寻找活动入口输入邀请码。这种因技术断层导致的糟糕体验,将直接摧毁端侧 AI 带来的精准转化意图。
工程实践:重构安装归因与全链路统计
面对端侧 AI 带来的流量孤岛化与本地调度黑盒,App 的研发与增长团队绝不能坐以待毙。必须深入系统底层,引入成熟的跨环境追踪基建,用强硬的底层穿透技术,把断掉的链路重新缝合起来。
部署深度链接,接管本地 Agent 的无缝唤醒
-
问题:当本地 Agent 试图跨应用拉起你的 App 时,如果你的 App 依然只支持老旧的 Scheme 协议,极易在不同品牌手机的系统级拦截(如各大厂商内置的安全中心)中失效,导致唤醒失败。
-
做法:全面升级并严格配置基于操作系统的底层 技术(如 iOS 的 Universal Links 和 Android 的 App Links)。
-
好处:这种系统级路由协议拥有最高的优先级。无论是由本地 AI 脚本触发,还是在极度封闭的社交软件(如微信、QQ)内点击,系统都会瞬间验证链接的所属权,无视浏览器的跳转阻碍,以毫秒级的速度直接拉起目标 App,并精准直达本地 Agent 指定的那个深层原生页面(如具体的商品 SKU 或预设的 AI 对话流),实现“零摩擦”的跨域执行。

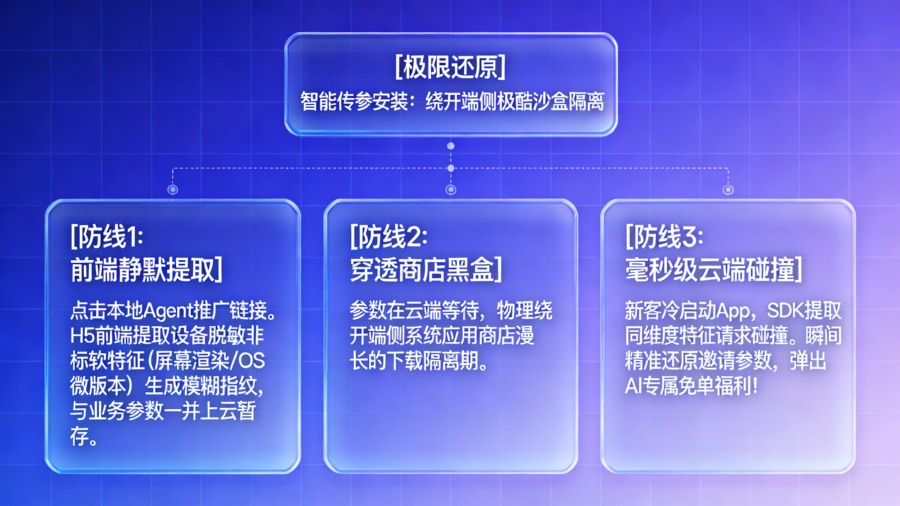
智能传参安装,打破端侧沙盒的参数隔离
-
问题:对于尚未安装 App 的新用户,在经过浏览器、应用商店到最终下载激活的漫长过程中,端侧极度封闭的系统沙盒会无情地抹除所有的渠道标记和邀请参数。
-
做法:采用成熟的端云协同 方案。当本地 Agent 生成的 H5 推广链接在浏览器中被点击时,前端 JS 引擎会静默提取当前设备的脱敏非标特征(如屏幕渲染参数、系统微版本)生成“模糊指纹”,并将该指纹与链接中携带的业务意图参数一起暂存在云端。待用户下载完毕并首次冷启动 App 时,客户端 SDK 立刻提取同维度特征向云端发起碰撞匹配,瞬间还原出被沙盒隔离前暂存的所有参数。
-
好处:这套方案巧妙地绕开了端侧系统的本地数据隔离。新用户首次打开 App 瞬间,系统自动识别其来源,直接弹出“您好友的 AI 助手为您推荐了以下免单福利”的定制化弹窗,完美实现了跨越商店黑盒的场景还原。
重塑全渠道统计,捕捉孤岛中的幽灵流量
-
问题:当流量入口从公域的信息流广告,大量转移到私密且无法被云端监控的“端侧 AI 对话框”或“本地智能体生成海报”中,运营人员如何精准评估不同拉新策略的真实 ROI?
-
做法:摒弃对传统点击流的过度依赖,重构 体系。为每一个由本地 Agent 动态生成的推广触点分配独一无二的渠道短链或 ChannelCode。结合落地页指纹匹配和端侧直传双重机制,对所有被激活的新设备进行极其严密的底层对账。
-
好处:将那些游离在云端监控之外的“本地意图流量”进行显性化收束。通过多维度的聚类分析,开发者能清晰地剥离出哪些新增是由真实的社交裂变带来的,哪些是由高级机器脚本(利用本地大模型能力)伪造的群控作弊量,让每一分跨端营销预算都有据可查,坚决守住风控底线。
这件事和开发 / 增长团队的关系
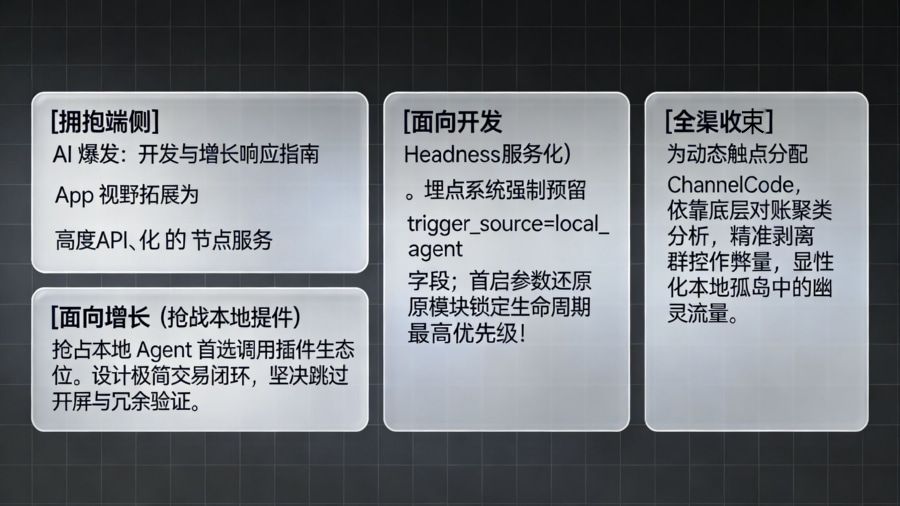
端侧 AI 的爆发,意味着 App 从“云端流量的被动接收者”转变为“本地意图的主动承接者”。各业务线必须迅速建立一套适配本地调度的底层响应机制:
面向开发 / 架构
开发团队必须将 App 的设计视野从“单纯的 GUI(图形用户界面)呈现”拓展为“高度 API 化的节点服务”。在埋点系统和系统接口设计中,必须预留并规范记录来自不同触发源的专属字段(如 trigger_source=local_agent、intent_action=direct_buy)。同时,务必确保“首启参数还原”和“深度链接路由解析”模块处于客户端生命周期的绝对高优先级,保证 App 能够毫秒级无缝衔接由本地 AI 抛来的极其复杂的业务上下文。
面向产品 / 增长 / 运营
增长操盘手需要敏锐地捕捉到“去中心化”的流量分发红利。当各大公域平台的买量成本高企时,未来极具性价比的获客方式,是想办法让你的 App 成为用户本地 Agent 的“首选调用插件”。利用场景还原机制,为这批由 AI 直接引导过来的高意图用户,设计极简的跨端裂变与交易闭环(坚决跳过开屏广告和非必要的验证步骤)。通过精准的全渠道统计,持续追踪不同本地拉新场景下的流量转化质量,精细化打磨增长漏斗。
常见问题(FAQ)
为什么 Gemma 4 这种小模型的端侧运行会导致归因追踪失效?
在传统的追踪模式中,用户的所有交互(点击广告、搜索关键词)都会经过广告商的云端服务器,服务器在云端记录下“设备A在几点几分点击了广告B”。而端侧大模型(如 Gemma 4 E2B)由于其极其轻量化的特性,可以被直接固化在手机系统或本地 App 中离线运行。当它根据本地用户的历史偏好,自动在后台生成一个带有你 App 推广链接的卡片并发送给微信好友时,这个生成和分发过程完全没有云端的参与,导致云端的追踪系统彻底失去了“源头”记录,造成归因断链。
在端侧系统沙盒越来越严格的情况下,传参安装是如何保证精准匹配的?
随着 iOS 隐私政策(如 ATT 框架)和安卓底层机制的收紧,跨应用读取剪贴板或获取硬性设备 ID(如 IMEI)已被彻底封堵。专业的传参安装技术(如 openinstall)早已摒弃了这些违规手段。它采用的是端云协同的“模糊指纹”技术。在 H5 页面端和 App 冷启动端,静默采集设备的屏幕分辨率、系统内核微版本等数十项绝对合规且不涉及用户身份的非标软特征。这些特征在云端进行高维聚类和哈希碰撞,能够在极短的有效时间窗口内,以极高的精度将“点击链接的设备”和“刚刚激活 App 的设备”锁定为同一台,从而在不碰触隐私红线的前提下完成参数的精准还原。
既然本地 Agent 可以模拟用户操作,如何防止黑产利用它来刷拉新奖励?
这正是端侧 AI 时代风控面临的最大挑战。黑产如果将本地大模型接入群控设备,确实可以完美模拟真实用户的浏览、点击甚至聊天行为。因此,传统的“行为特征反作弊”将大量失效。应对之道是启用基于物理规律的 CTIT(点击至激活时间)异常分布监控。 即便 AI 脚本再逼真,它在企图窃取渠道归因时发起的“点击注入劫持”,其点击到激活的时间差往往短得不可思议(通常在 1-3 秒内),这严重违背了真实物理网络下载几十兆 App 所需的下限时间。反作弊系统一旦监测到这种极速时间差的物理违规,便会立刻在服务端触发熔断,拒绝结算拉新奖励。
行业动态观察
,特别是可在手机端完全离线运行的 E2B/E4B 版本的发布,是 AI 发展史上的一个重要分水岭。当强大的智能和推理能力不再是云端机房的专属,而是化整为零,变成了亿万部手机中触手可及的本地算力时,它预示着移动互联网的流量分发范式将被彻底推倒重来。