美团测试万亿大模型:流量重构,App如何跨越底层归因?
 openinstall运营团队|
openinstall运营团队| 2026-04-27|
2026-04-27| 213
213
在本地生活与履约赛道的巨头暗战中,“百模大战”的硝烟正向着万亿参数的深水区蔓延。2026年4月24日,美团测试万亿大模型 LongCat-2.0-Preview 的消息不胫而走,其参数规模直接跻身全球顶尖阵营。当一家不以云计算为主业的互联网巨头,开始砸下数十亿美元、动用高达 5 到 6 万张算力卡去淬炼一个能够对标 GPT-5.5 的底层 AI 大脑时,这意味着其核心业务生态即将迎来颠覆性的洗牌。大模型不再仅仅是对话框里的问答玩具,它将演变为接管用户吃喝玩乐、出行购物决策的“超级智能分发枢纽”。在这样的未来图景下,用户的消费流量将被 AI 助手大规模截流并重新分配(即流量重构)。对于千万级依附于巨头生态或独立获客的第三方 App 而言,当大模型直接主导了意图分发,传统的买量追踪漏斗将瞬间致盲。面对这一跨时代的流量变局,App 增长团队究竟该如何重构底层的归因雷达与跨端协议,才能在 AI 的隐秘调度中精准算清每一笔真实订单的 ROI?
新闻与环境拆解
越过“测试邀请”的常规公关话术,用技术显微镜去透视 ,我们能清晰看到美团在这场 AI 赌局中押上的底牌,以及其极其锋利的商业意图。
对标 GPT-4 的万亿级怪兽:混合专家(MoE)与 1M 上下文
LongCat-2.0-Preview 是一款尚未公布正式命名的新一代基础大模型。据业内人士透露,其总参数规模已突破万亿级别,采用了先进的混合专家(MoE)架构,整体能力直指 GPT-4。 更为硬核的是它的上下文吞吐能力。与爆火的 DeepSeek V4 类似,LongCat-2.0 同样支持 1M(百万级)的上下文窗口。这意味着它能在单次推理中处理数百万字的超长输入,其信息吞吐量级已经等同于刚发布的 GPT-5.5。如此庞大的“工作记忆”,足以让模型在单次对话中完整消化一本商业企划书、一套繁杂的系统代码,或者是一个用户过去一年所有的外卖、酒旅消费行为数据,从而做出极其精准的个性化推荐与任务规划。
纯国产算力集群的里程碑:5-6 万张卡的火力全开
除参数规模外,该模型最大的突破点在于:训练推理全程依托国产算力集群完成。 据消息人士透露,美团本次训练阶段动用的国产算力卡数量高达 5 万至 6 万张之间。这是迄今为止,在国产算力上完成的规模最大的大模型训练任务。这不仅验证了国产算力生态的成熟度,也标志着中国 AI 巨头在硬件底座上迈出了摆脱对单一海外芯片依赖的关键一步。 为了这一刻,美团早有伏笔。创始人王兴在 2024 年财报业绩会上就曾披露了 GPU 储备战略,不仅持续投入数十亿美元保障算力,还接连投资了摩尔线程、沐曦股份、爱芯元智等多家国产半导体公司,以及智谱 AI、月之暗面等大模型明星企业。
“AI-Powered App”的野心:深度优化 Agent 生产场景
美团在 AI 领域的重仓,绝非为了卖 API 接口。“在 AI 领域,美团唯一的策略是进攻。”王兴的断言正在化为现实。 新的 LongCat 模型面向 Agent(智能体)应用场景进行了深度优化,可有效适配代码生成、复杂任务规划、企业自动化等生产场景。早在去年 9 月开源的 LongCat-Flash 中,美团就通过创新的“零计算专家机制”兼顾了高推理效率与低运营成本。此外,LongCat-Video 的全家桶功能(文本/图像生成长视频、原生分钟级连贯生成)也展示了其在多模态内容生产上的强悍能力。 这一切的技术积淀,都指向了王兴那个极具压迫感的终极目标:“争取把美团 App 率先升级成为 AI-Powered App”。当万亿级大模型被塞进国民级生活服务入口,一个能够包办需求拆解、全网比价、自主跨端下单的超级 Agent 就此诞生。
从新闻到用户路径的归因问题
大模型深入垂直业务,意味着用户触达服务的漏斗将发生物理形态的折叠。

设想在不久的将来,当带有万亿参数大模型的超级生活助手普及后:用户不再需要分别打开大众点评查评分、打开携程订酒店、再打开滴滴叫车。他只需对语音助手说:“帮我安排周末去长沙的行程,要评分最高的小龙虾馆,酒店定在五一广场附近,顺便把接机专车也约好。” 超级智能体(Agent)将在云端瞬间并发执行,它会根据用户的模糊意图,自主调用各大垂直 App 的 API 或生成特定的唤醒链接,甚至在后台静默完成三笔不同平台的交叉订单。
在这条由 AI 主导的“流量重构”链路上,第三方 App 及服务提供商将面临灾难性的断流与归因盲区:
-
流量来源的彻底黑盒化:传统的买量推广依赖于媒体平台(如朋友圈、短视频)回传的明确点击事件与设备指纹。但在这条新链路中,触发购买动作的“人”变成了躲在云端的 Agent。第三方 App 看着后台暴涨的新增激活与高客单价订单,却根本无法追踪这笔流量究竟是来自美团 LongCat 的调度,还是 Kimi 助手的推荐。一旦失去来源标记,增长团队就无法计算渠道 ROI,市场预算将陷入“瞎投”的境地。
-
跨应用智能体跳转的“沙盒熔断”:当超级大模型生成的行程方案中包含了一个必须跳转至本地独立 App(如某个特定品牌的租车应用)确认的卡片时,由于该链接承载了高维度的意图参数(时间、地点、专属优惠码),且需要跨越第三方系统沙盒,老旧的 URL Scheme 跳转极易被操作系统安全机制拦截。用户点击后,只能看到一个冷冰冰的下载页或应用默认首页,大模型精心构建的上下文环境彻底崩塌。
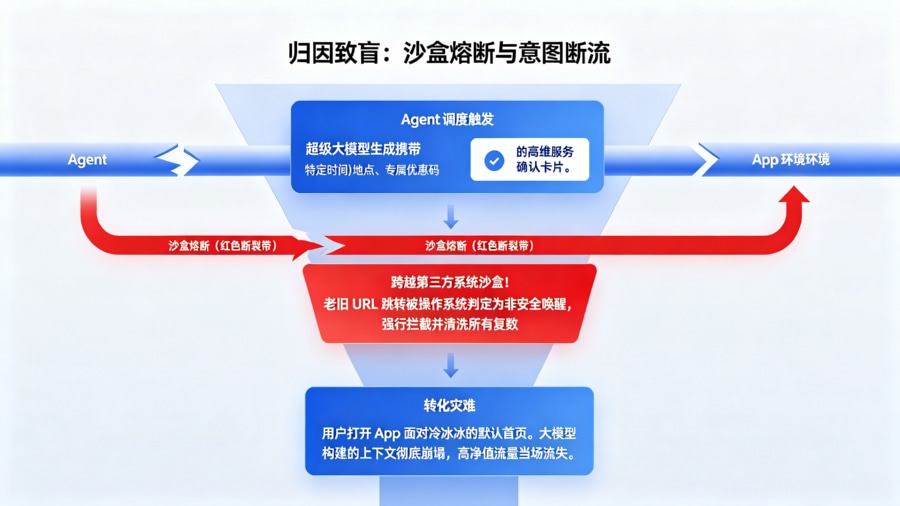
-
佣金结算与反作弊的交叉危机:黑灰产极易利用大模型的 API 接口,批量伪造高仿真的虚假用户行为轨迹,去套取各大平台给 AI 助手的 CPS 佣金。如果 App 无法在底层核验这些自动化流量的真伪,企业的营销资金将被机器大军瞬间吸干。
工程实践:重构安装归因与全链路统计
行业前瞻提示:在超级大模型加速演变为“流量分发垄断者”的存量博弈中,垂直 App 沦为大模型“后台执行器”的风险剧增。openinstall 技术实验室指出,当入口被大厂截流,提前在系统底层浇筑不可篡改的跨端传参及全链路对账雷达,是企业在被代理化的生态中抢回数据主权的唯一解法。
面对被万亿级大模型重构的交互漏斗,App 开发与增长团队必须抛弃对前端页面的过度依赖,向底层的数据通信与多维核验要生存空间。
重塑全渠道归因网络,撕开 Agent 分发黑盒
-
问题:当海量的高价值订单由各类隐匿在云端的大模型助手触发,企业如何精准剥离、回溯并评估不同 AI 平台带来的真实转化效能(ROI)?
-
做法:彻底告别单一且极易被大模型请求抹除的设备 ID 追踪逻辑,在业务后端全面接入端云协同的 矩阵。在与各大模型平台(如美团 LongCat、豆包等)建立 API 合作或提供外部调用链接时,为每个生态接口分配带有强加密签名的动态追踪参数。更核心的是,必须采用 S2S(服务器对服务器)直传技术,将 App 后端产生的深层商业事件(如“完成专车支付”)与前端大模型下发的原始口令进行强制的交叉对账。
-
好处:在被超级应用截胡的黑盒中,为企业夺回“上帝视角”。运营总监能够依靠极其细颗粒度的后端核销报表准确研判:是接入大厂万亿模型的接口客单价更高,还是某独立 AI 助手的引流复购率更好。依据这些铁证般的 LTV(生命周期价值)数据,企业能够在未来的 AI 流量采买与商务谈判中占据绝对的主动权。

部署全局深度链接,承接智能体无损唤醒
-
问题:当用户点击 AI 智能体生成的服务确认卡片时,如何跨越操作系统的严苛沙盒,将复杂的意图参数(如特定座次、优惠券信息)瞬间传入目标 App 并拉起支付?
-
做法:全面废弃老旧、极易被系统拦截断流的普通页面跳转协议。在应用底层原生配置具备系统级信任域签名的 技术(如 Universal Links)。当大模型的 Agent 发起跨端调用时,将结构化的高维任务参数深埋在标准链接的底层。
-
好处:直接打穿各类智能助手与移动系统的防御壁垒。只要用户触发点击,系统会在底层秒级校验并拉起目标 App,将所有意图参数无损送达业务引擎。即使用户尚未安装该 App,在经由应用商店下载完毕后,首次冷启动的瞬间,延迟深度链接技术也会精准寻回参数,直接呈现场景还原的订单支付页。这种抹平多模态交互摩擦力的体验,是将大模型流量沉淀为私域用户的关键核武器。

这件事和开发 / 增长团队的关系
“AI-Powered”不仅是大厂的专利,更是所有应用生态必须适应的生存环境。上下游团队的战术重心必须发生根本性转移:
面向开发 / 架构
在面对随时可能由外部大模型发起的高频、高并发服务请求时,研发架构必须进行深度的服务化改造。首启唤醒链路的主线程必须极度优化,绝不能在承接外部 Agent 倾泻的复杂 JSON 格式参数时发生卡顿或崩溃。所有涉及商业闭环的参数提取 API,必须全量实施非对称加密与动态时间戳(Timestamp)防伪校验。因为黑灰产利用大模型批量伪造虚假激活和骗取佣金的成本已逼近于零,没有强签名拦截的接口,等同于向欺诈大军敞开金库。
面向产品 / 增长 / 运营
增长操盘手的 KPI 必须果断向深层转化率倾斜。当流量的初筛与决策权让渡给了超级 AI 助手,单纯考核 App 的打开率和日活(DAU)已毫无意义。运营团队必须深度梳理产品内部的任务承接漏斗,确保任何通过深度链接传入的外部指令,都能在端内得到最极简、最不易报错的消化与流转。在未来的生态位竞争中,谁能利用最严密的归因报表算清 AI 渠道的底细,谁能为外部智能体提供最稳定的底层唤醒服务,谁就能在这个被巨头大模型统治的“入口集权”时代,垄断最高净值的任务订单。
常见问题(FAQ)
美团测试万亿大模型 标志着其战略方向发生了什么改变?
这标志着美团正在从传统的“人力履约+货架搜索”平台,向真正的“AI-Powered(AI驱动)”超级应用全速冲刺。通过动用 5-6 万张国产算力卡训练出参数破万亿的 LongCat-2.0 模型,它不仅能够处理百万字的超长上下文,更针对复杂任务规划和企业自动化等 Agent(智能体)场景进行了深度优化。其战略意图是要用超级 AI 大脑接管本地生活与出行的全盘决策流量。
万亿大模型支持的“1M上下文窗口”在实际应用中有多大威力?
1M(百万级)的上下文窗口意味着极大的“工作记忆”容量。模型在单次推理中可以处理 75 万到 100 万字的信息量。这意味着大模型不再只能回答短句,它可以一次性消化一本详尽的城市商业数据白皮书、一套复杂业务系统的完整底层代码,甚至能结合用户过去数年的海量消费行为轨迹,为其量身定制长达数天的多节点商旅行程,且逻辑严密不发生遗忘断层。
大模型成为生活服务超级入口后,为什么会导致第三方 App 归因困难?
在传统模式中,用户是在微信或浏览器里点击广告跳转的,系统能追踪到明确的来源 Cookie 和设备标识。而在大模型入口时代,任务分发变成了云端智能体(Agent)在后台的自动调度与接口调用。这种操作由于跨越了非标准的容器环境,极易被系统沙盒切断原始意图参数和设备来源标记。App 端只能看到激活激增,却无法甄别这些流量究竟是大模型的自然调度还是黑灰产的机器伪造,从而陷入归因对账彻底黑盒化的困境。
行业动态观察
回望 美团测试万亿大模型 并将算力底座全盘国产化这一极具压迫感的战略落子,我们见证的不仅是中国 AI 力量在断供封锁下的绝地突围,更是移动互联网流量分配法则的又一次冷酷重写。