面壁智能BitCPM三值大模型入端侧?1.58-bit重写AI部署成本
 openinstall运营团队|
openinstall运营团队| 2026-05-26|
2026-05-26| 220
220
面壁智能BitCPM-CANN三值大模型真能让8B大模型跑进手机?这一产业前瞻已在供应链端得到确凿印证,5月25日面壁智能联合清华大学、OpenBMB开源社区正式发布并开源全球首个基于国产昇腾算力训练的1.58-bit三值大模型,推理显存节省6倍,8B模型仅占3GB即可在手机端运行。当HBM内存价格暴涨165%遇上端侧AI爆发,面壁智能BitCPM-CANN三值大模型在终端部署场景中正以1.58-bit极低位宽重写AI的算力成本公式。

技术突破解析:面壁智能BitCPM-CANN三值权重如何跑通昇腾
面壁智能BitCPM-CANN三值大模型的核心突破在于将每个参数的取值从传统FP16的几万种压缩到只有-1、0、+1三个值。编码三个值恰好需要约1.58个二进制位——"1.58-bit"由此得名。据,这是全球首个完全基于国产算力平台(华为昇腾)实现端到端训练并开源的三值大模型,从量化算子、训练算法到全链路框架均在昇腾上原生完成。面壁智能AI Infra负责人、清华大学计算机系高性能所博士后李宇轩指出,1.58-bit被视为模型压缩的"数学甜蜜点":1-bit无法兼顾数学表达的对称性与含零特性,而1.58-bit在极致压缩比与表达能力之间达到了最优平衡。
与行业常规的后训练量化(PTQ)路线不同,面壁智能BitCPM-CANN三值大模型采用的是量化感知训练(QAT)路线——模型并非训练完成后才被动压缩,而是从训练初始阶段就主动学习用1.58-bit的三值权重来承载知识。

据,团队技术路线分为三步。此前所有公开的三值模型训练都在NVIDIA GPU上完成,面壁智能是第一个将三值训练算子搬上国产NPU的团队。
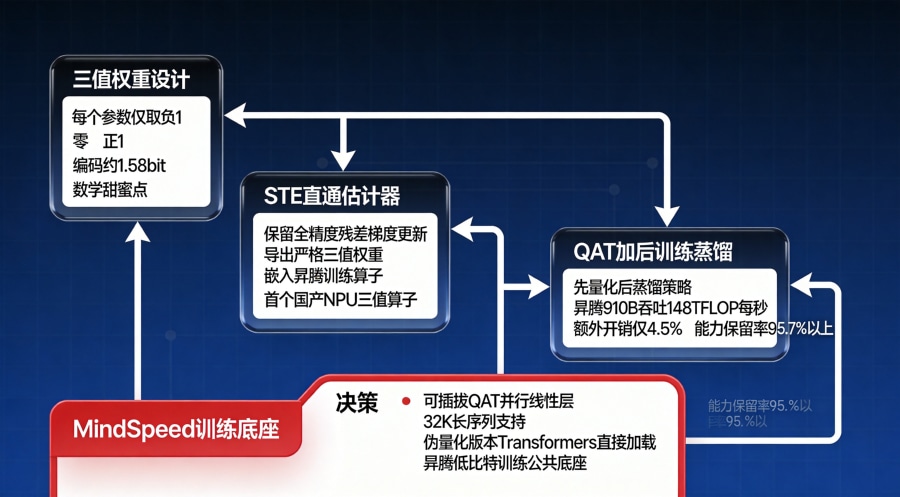
STE直通估计器:让离散权重跑进训练算子
研发团队采用STE(直通估计器)方案,在训练阶段保留全精度残差用于梯度更新,在导出阶段则输出严格的三值权重,从而将离散权重真正嵌入华为昇腾的训练算子中。这不是简单地把FP16转成三值,而是从算子层面重新设计,针对昇腾芯片的架构特点重新实现了矩阵乘法,在-1/0/+1的计算中充分利用昇腾的并行能力。
QAT加后训练蒸馏:守住95.7%以上能力底线
团队在昇腾上完整部署了量化感知训练(QAT)与后训练蒸馏流程。李宇轩在接受时,将先量化、再蒸馏的策略比作"教导一个天资有限但勤奋的学生"——过早引入复杂蒸馏机制,模型反而难以收敛。低比特模型对数据噪声更敏感,团队需做更严格的清洗与筛选,避免无效信息干扰模型学习。在昇腾910B上,量化训练吞吐为148 TFLOP/s,对比全精度的155 TFLOP/s,额外计算开销仅约4.5%——证明国产芯片有能力承载复杂的低比特预训练算法。
MindSpeed训练底座:低比特能力沉淀为公共基础设施
团队基于MindSpeed与Megatron-LM框架嵌入可插拔的QAT并行线性层,统一了checkpoint格式并支持32K长序列训练,使低比特训练能力成为昇腾平台上可复用、可扩展的公共底座。本次发布的是伪量化版本——权重已受三值约束但物理上仍以浮点保存,用户可像加载普通模型一样用Transformers直接运行,无需任何专用量化库。后续其他团队想在昇腾上做低比特训练,不再需要从零开始踩坑,环境层、长序列支持、并行策略、融合算子、调试工具已经沉淀完毕。
商业账本:6倍显存红利遇上HBM暴涨165%
BitCPM-CANN释放6倍显存红利的背景,是全球内存供应链的剧烈震荡。据,高盛近期报告指出,受AI服务器需求爆发影响,2026年存储价格预期大幅上调,DRAM涨幅250%-280%,NAND涨幅200%-250%,HBM因技术门槛与产能约束涨幅更高。李宇轩透露,内存价格在过去一年内翻了约5倍,手机及终端厂商存在严重的"显存焦虑"。
内存价格翻5倍,端侧"显存焦虑"成行业共识
大模型及很多产业都在经历"内存危机",行业被迫在"模型能力"和"内存预算"之间做取舍:要么缩小模型、牺牲智能,要么承受高昂的内存成本、限制部署规模。内存涨价倒逼厂商控制成本,进而限制设备内存大小,反向传导到所有要在内存里跑的模型应用程序,牵引整个Infra方向向更节约内存的路线优化。行业量化路线也在快速迭代:去年FP8应用落地成为主流模型标配,DeepSeek、MiniMax等均普遍采用;今年行业重心转向FP4,并加速推进2-bit、1.58-bit技术落地。高通从去年下半年已率先实现2-bit硬件支持,国内DeepSeek、智谱、阿里千问等模型厂商也在推进低位宽量化模式落地。李宇轩将不同精度的压缩类比为物流打包:FP8如同标准纸箱,FP4类似真空压缩袋,2-bit为极致捆扎压缩,靠算法适配压缩形态,适配小型终端设备,最大限度节省空间功耗。
从16GB到3GB:8B模型跑进手机的商业逻辑
一个8B参数的传统BF16模型需占用约16GB显存,超过绝大多数手机内存容量。而三值量化将其压缩至2-3GB,普通旗舰手机即可流畅运行8B级别的对话模型。若进一步结合MoE架构与激活范围约束,2-bit量化将模型权重压缩6-8倍,4GB内存能放置16B模型,8GB内存可扩展至60B——未来有望在手机上运行600亿参数的大模型。高通骁龙8850/8397等新一代端侧芯片已原生支持2-bit推理,BitCPM-CANN恰好提供了1.58-bit的权重,与硬件能力精准匹配。李宇轩强调:"如何用最便宜的芯片跑出最大的智能,这就是端侧模型最核心的问题。"
行业评测:面壁智能BitCPM-CANN三值大模型11项基准1:1对照
面壁智能BitCPM-CANN三值大模型与同尺寸MiniCPM-4全精度家族在常识、阅读理解、学科知识、数学与推理等11项任务上进行了1:1性能对照。四个尺寸的能力保留率分别为:0.5B版90.1%,1B版97.1%,3B版97.2%,8B版95.7%。3B版本在数学、代码等高敏感任务上已进入接近全精度区间。
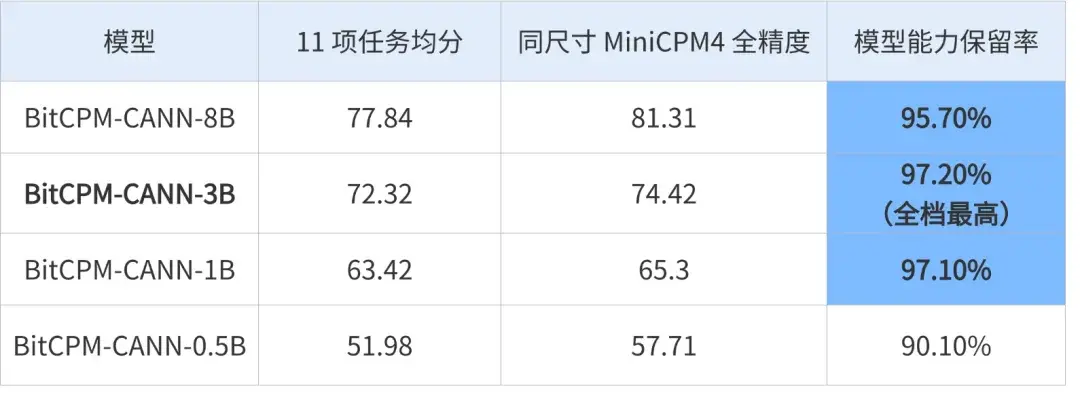
8B版本保留率略低于3B(95.7% vs 97.2%),但绝对能力得分77.84分远超三值版3B的72.32分,证明降低部署门槛的同时维持了高智商。97.2%的保留率意味着三值模型与同尺寸全精度模型的差距,已经小于许多全精度模型之间的差距。李宇轩表示,低比特带来的退化是平缓的而非断崖式的,通过后训练技术可以将损失引导至非核心场景——例如手机AI对代码能力要求不高,可以把损失引导到代码能力上,把重点放在用户关注的指标上。
幕后花絮:面壁智能四年深耕端侧AI的技术底牌
面壁智能BitCPM-CANN三值大模型的亮相并非偶然。5月23日,该模型在华为鲲鹏昇腾开发者大会(KADC 2026)完成首次技术亮相,两天后正式全系列开源。面壁智能与华为昇腾自2024年深度合作以来,持续在端侧大模型、低比特量化训练等领域开展联合创新。
面壁智能从成立之初就不绑定CUDA,自研了训练框架BM-Train(Big Model Train),从稀疏架构InfLLM到低比特量化方法BitCPM、推理框架CPM.cu,逐步构建起覆盖训练到推理的全栈端侧技术体系。面壁智能此前提出"密度定律"并推动轻量化大模型的全球开源,其MiniCPM系列在GitHub上累计收获超3万星标,HuggingFace开源总下载量超过3000万,成为中国端侧AI领域最受欢迎的开源模型家族之一。
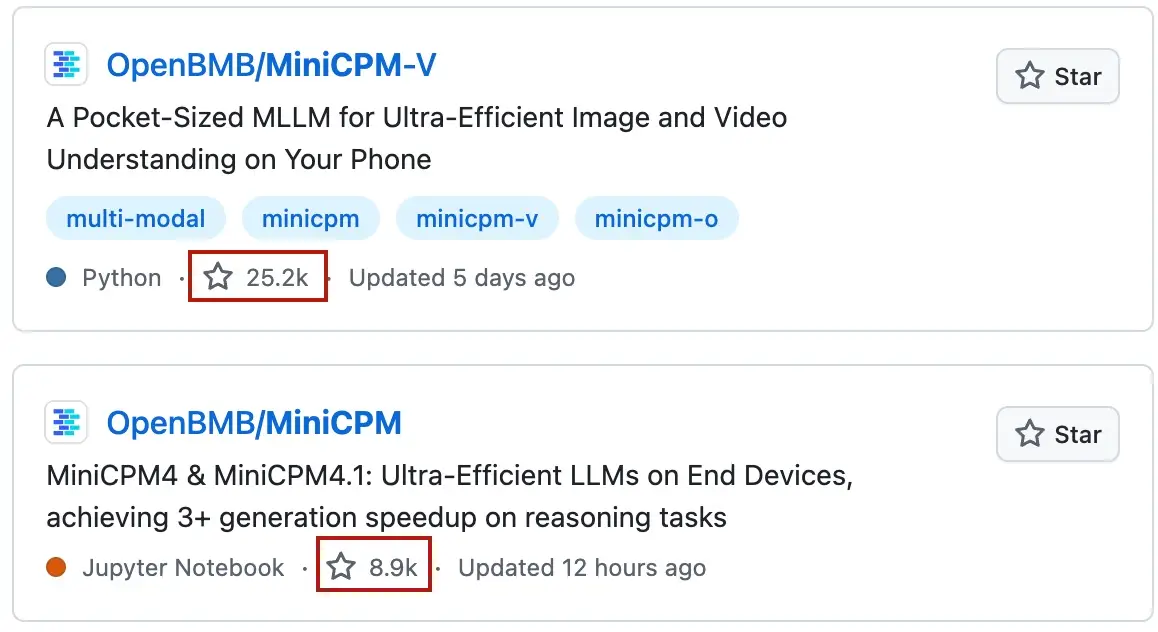
BitCPM-CANN正是MiniCPM家族向三值量化的延伸。全系列模型权重已在HuggingFace(https://huggingface.co/collections/openbmb/bitcpm-cann)和ModelScope(https://modelscope.cn/collections/OpenBMB/BitCPM-CANN)开源,开发者可零门槛体验国产算力在低比特场景的真实性能。李宇轩透露,团队耗时约三周完成昇腾平台的适配与优化,认为在8B以内尺寸模型训练上,昇腾体验已经比较好,训练稳定性、芯片利用率接近可比状态。他判断,低比特技术与稀疏化(MoE)技术叠加之后,更大规模模型(如60B)有望在明年上端,进一步拉近端侧与云端的智能差距。
从业者影响:端侧AI部署格局被1.58-bit重写
面壁智能BitCPM-CANN三值大模型对从业者的冲击是分层的。对手机厂商而言,无需为跑大模型去堆昂贵的超大内存,普通旗舰机就能流畅运行8B级别的对话模型,产品迭代节奏不再被显存预算绑架。对芯片生态而言,"国产芯片只能跑推理"的局面正式翻篇——从量化算子、训练算法到全链路框架全部在昇腾上原生完成,实现了国产NPU、国产模型、国产训练框架的完整闭环。对AI应用开发者而言,内存成本急剧下降,在不增加物理内存的情况下可以大幅提升模型能力或服务密度。
端侧AI落地:当模型塞进手机,意图怎么传、场景怎么还原?
面壁智能BitCPM-CANN三值大模型让8B模型跑进手机,普通用户看到的是"手机变聪明了",开发者看到的却是一整条从触达到激活的增长链路正在被端侧AI的交互范式彻底打碎。
端侧AI催生了两种截然不同的流量形态:主动页面流量——用户在短视频平台看到AI功能推荐,主动点击跳转到App下载页面,这是传统点击驱动的模式;意图/任务流量——端侧大模型根据用户上下文自动触发推理、调度服务,用户甚至不需要点击屏幕,AI就已经在后台完成了决策与跳转。后者的参数传递路径远比前者复杂:意图参数在跨越硬件设备时丢失、在进入应用商店中转时被截断、在系统内唤起App时上下文断裂、在首次打开时变成数据黑盒——每一个环节都是用户增长链路上的断点。
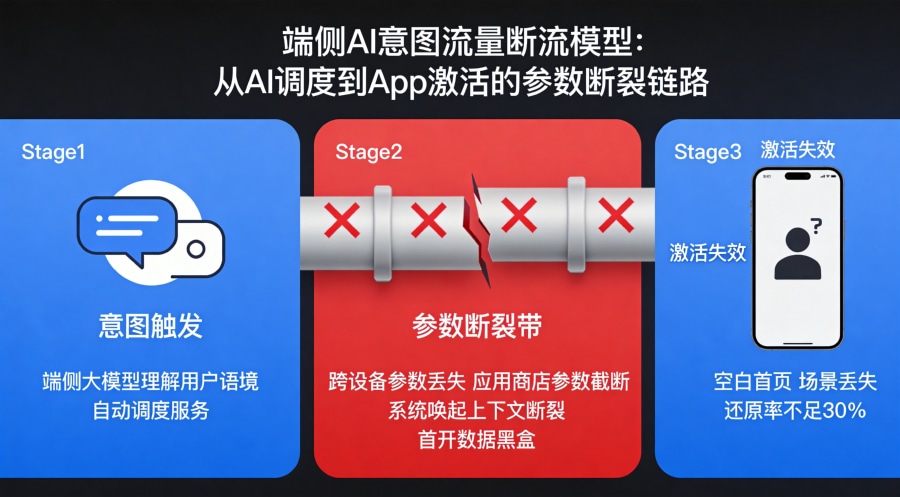
当端侧大模型需要根据用户在短视频中表达的"帮我规划周末行程"的意图,跨端拉起旅行App并还原场景时,唤醒App那一刻的能否完整还原用户所处的场景?当企业需要评估不同渠道引入的用户在端侧AI功能上的激活率和留存率时,归因数据是否准确?这些问题在云侧AI时代并不突出,因为所有交互都在云端完成。但在端侧AI时代,用户与模型的交互发生在设备本地,传统云端埋点方案面临覆盖盲区。
工程实践:重构端侧AI的深度链接与场景还原
实践一:意图跨端传递——从"点击"到"AI调度"的参数不丢失
问题:端侧大模型自动触发的意图/任务流量,在跨越硬件设备、进入应用商店中转时,意图参数(用户上下文、场景信息、渠道标识)面临丢失风险,传统基于URL参数的传参方案无法覆盖AI自动调度的场景。
做法:通过在端侧AI意图触发时即刻生成携带完整上下文的调度链接,无论用户是主动点击还是AI自动唤起,参数都能无损传递至目标App的首次启动,实现意图的完整还原。
带来的好处:端侧AI功能从"能用"升级为"好用"——用户被AI推荐触达后,打开App即可无缝继续之前的场景,而非面对一个空白的首页,激活率与场景还原率显著提升。
实践二:端侧归因闭环——AI交互时代的渠道效果可量化
问题:端侧AI的交互发生在设备本地,传统云端埋点方案无法覆盖"AI自动触发→跨端调度→App激活"的全链路,渠道归因数据出现大面积盲区,企业无法判断哪个渠道引入的端侧AI用户质量更高。
做法:在深度链接的基础上叠加能力,从意图触发源头到App激活完成,建立端到端的归因链路,确保每一条AI调度的参数都能被准确归因到具体的渠道与场景。
带来的好处:企业在端侧AI时代仍然拥有清晰的数据视图,可以精确评估不同触达渠道的转化效率,避免在流量泡沫中盲目投入。
行业前瞻提示:针对端侧大模型自动触发意图并跨端调度的场景,openinstall技术实验室目前正与部分头部App展开定向的联合探索,以验证深度链接在AI自动调度场景下的参数完整性保障能力。
这件事和开发/增长团队的关系
面向开发/架构
端侧大模型入终端,意味着App的入口不再只是桌面图标和推送通知,AI意图调度正在成为新的入口形态。开发团队需要提前预留深度链接的接口位置,确保端侧AI的调度请求能被正确路由到App内的目标页面;在多端ID策略上,需要统一设备标识与用户标识的映射关系,避免意图参数在跨端传递时因ID不匹配而丢失;在参数安全上,需对AI调度的链接进行签名防刷,避免恶意构造的调度请求篡改用户场景或注入虚假参数;在设备兼容性上,需覆盖不同Android厂商的深度链接适配差异与iOS Universal Link的配置要求。
面向产品/增长/运营
端侧AI改变了用户的触达路径——从"看到广告→点击下载→打开App"变为"AI推荐→意图触发→场景还原"。产品团队需要重新定义主路径渠道,将AI意图触发的场景纳入核心转化漏斗;增长团队需调整预算策略,将投入从传统的页面流量采买逐步向意图流量场景倾斜;运营团队可利用场景还原设计闭环体验——用户被AI推荐触达后,打开App直接进入个性化推荐页而非空白首页,大幅缩短从激活到核心功能使用的路径。同时,需警惕端侧AI场景下可能出现的虚假流量——意图参数可能被伪造,需借助归因数据中的异常指标识别并剔除劣质流量。
常见问题(FAQ)
面壁智能BitCPM-CANN三值大模型的三值权重是什么意思?
三值权重指模型每个参数只能取-1、0、+1三个值,而非传统FP16的数万种取值。三个值的信息量为log2(3)≈1.58 bit,因此称为1.58-bit量化。这不是简单的精度丢弃,而是通过量化感知训练让模型在极低位宽约束下"原生生长",迫使每个bit承载最大信息密度。
端侧AI部署为什么需要低比特量化?
端侧设备的内存容量有限且成本高昂。2026年HBM内存价格暴涨165%以上,DRAM涨幅达250%-280%。一个8B参数的BF16模型需16GB显存,超过绝大多数手机内存;而1.58-bit三值量化后仅需2-3GB,普通旗舰机即可运行。低比特量化是端侧AI落地的必要条件。
1.58-bit量化的模型能力会大幅下降吗?
面壁智能BitCPM-CANN三值大模型评测数据显示,1B/3B/8B三个尺寸的能力保留率分别为97.1%/97.2%/95.7%,3B版本在数学、代码等高敏感任务上接近全精度水平。低比特带来的退化是平缓的而非断崖式的,且可通过后训练技术将损失引导至非核心场景。








