多渠道归因分析怎么聚合数据?全渠道打通与数据中台构建
 openinstall运营团队|
openinstall运营团队| 2026-05-05|
2026-05-05| 175
175
多渠道归因分析怎么聚合数据?在全域增长与数字化转型的深水区,企业的数据总监与业务一号位面临着最令人绝望的报表割裂危机。线上买量团队紧盯着巨量引擎、腾讯广告后台华丽的消耗与点击报表,而线下业务团队则拿着各级门店地推员工手动登记的扫码拉新 Excel 表格。当管理层下达死命令,要求将“门店流量”与“线上买量”彻底合并到一张中台报表以核算全局 ROI 时,往往会发现由于数据颗粒度、底层统计口径与设备标识符的完全不互通,财务对账沦为一场灾难。如果不从底层构建跨平台的聚合归因引擎与统一身份网关,企业的营销预算池将永远充斥着虚报与重复计算,全域数据治理也将永远是一笔烂账。只有彻底打破物理界限,建立标准化的数据中台,才能让每一分钱的去向都清晰可查。
孤岛危机与业务痛点:割裂的买量与地推数据
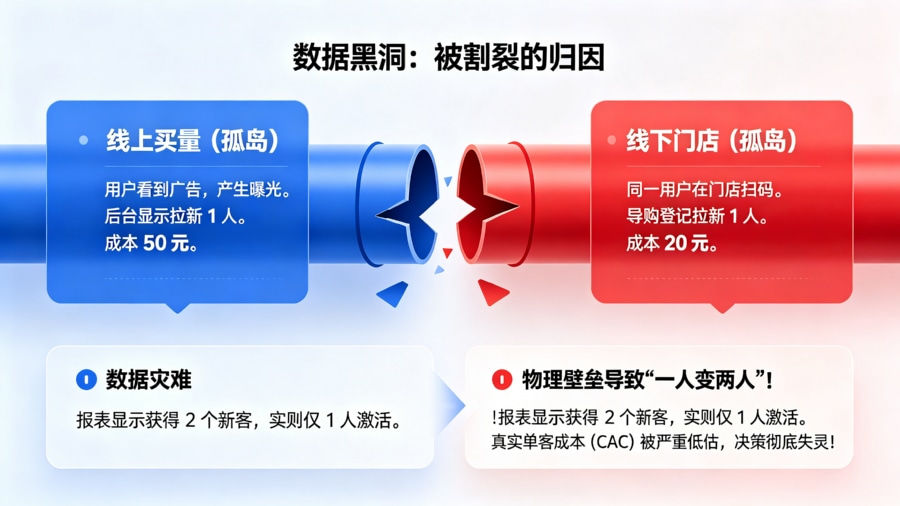
多渠道归因分析怎么聚合数据?被困在 Excel 里的数据总监
在缺乏现代化数据底座的传统企业中,数据总监的工作往往沦为“高级表哥/表姐”。每天需要从十几个不同的广告媒体后台导出 CSV 文件,再结合线下数十个区域经销网络上报的地推数据,试图在 Excel 中通过简单的 VLOOKUP 拼凑出全局大盘。这种原始的“手工聚合”不仅存在严重的数据滞后,更致命的是无法识别跨渠道的真实转化路径。同一个用户,可能在线上被短视频广告种草(产生了一次线上曝光记录),随后周末在商场逛街时被导购员引导扫码下载了 App(产生了一次线下拉新记录)。在孤立的报表体系下,这个用户会被算作两个独立的新增,导致企业的单客获取成本(CAC)被严重低估,最终导向错误的战略决策。
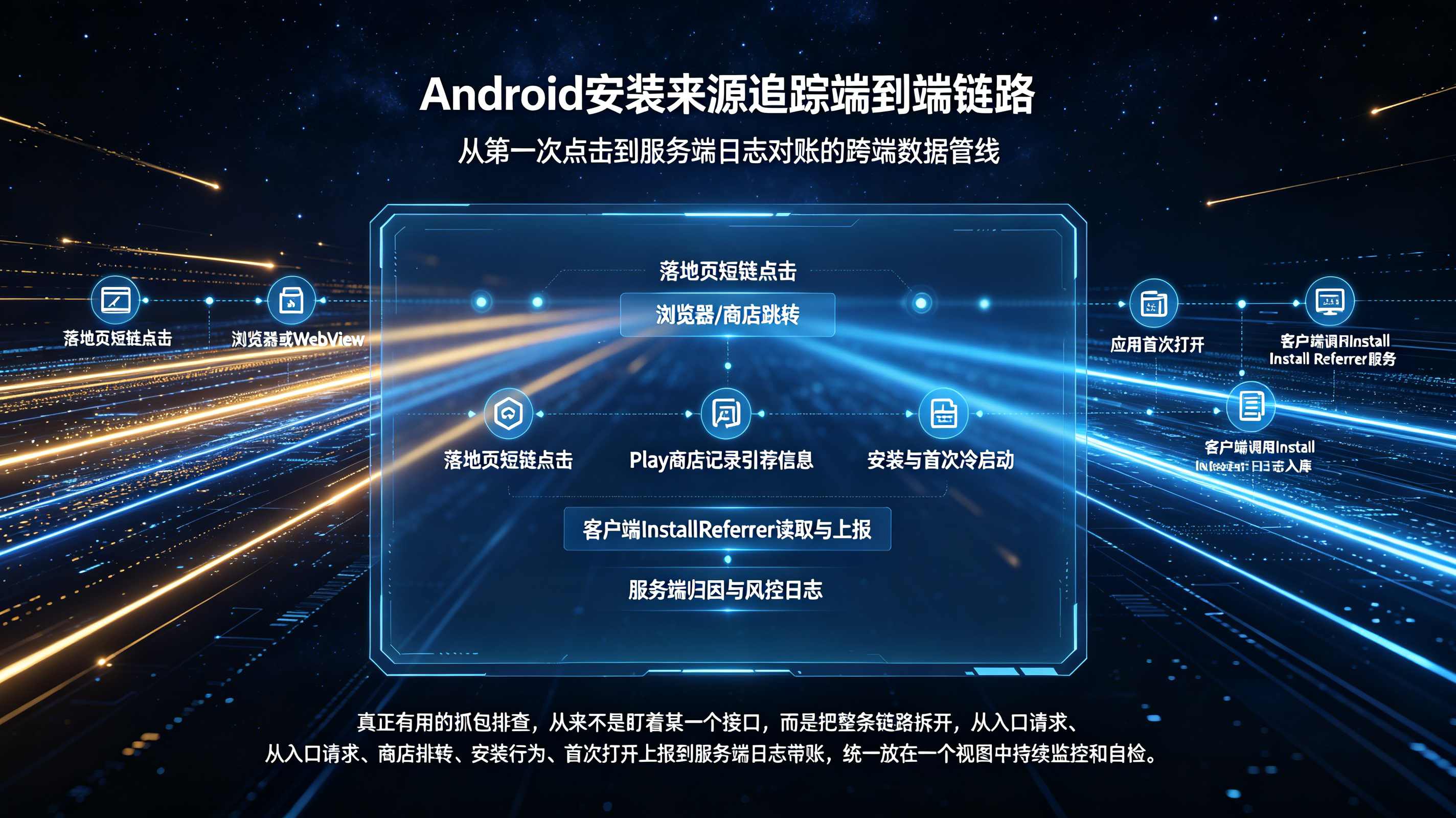
跨平台对账的物理壁垒:从设备隔离到时序混乱
阻碍多渠道数据打通的物理壁垒,根植于现代操作系统的隐私隔离与媒体平台的“自归因(Self-Attribution)”黑盒。绝大多数线上超级媒体(Media Source)出于数据保护与商业利益,往往会截留最核心的设备标识,并倾向于夸大自身的功劳。而在广袤的线下场景中,扫码行为严重缺失 Cookie 或精准的 LBS 坐标锚点,线上线下流量如同运行在平行的物理时空中。此外,双端生命周期时序的错乱使得问题雪上加霜:用户可能早上点击了信息流广告,晚上才在线下门店扫码激活,由于缺乏一个具备全局视野的时间戳对齐机制,最终的数据中台根本无法判定这个激活事件的归属权重,导致多触点归因(Multi-Touch Attribution)名存实亡。
底层原理与数据管线拆解:重构多渠道融合聚合引擎
统一身份网关(ID Mapping):打通设备指纹与全域标识
要终结数据孤岛,必须在数仓底层建立强大的 ID Mapping 引擎。根据 等一线大厂的数据架构规范,全渠道打通的核心在于“身份缝合”。当线上投放产生 OAID、IDFA 等标准设备标识,而线下微信扫码产生 OpenID 或公网 IP 时,统一身份网关会利用设备在首次冷启动(Initial Launch)时的动态硬件指纹进行降维对撞。结合图数据库(Graph Database)的技术,引擎会将这些原本孤立的碎片化节点(如手机号、设备指纹、微信号)连通,为每一个物理实体生成唯一不变的全局标识符(Global ID)。这是抹平全渠道标识差异的最强底层武器。

场景码(Scene Code)分发:实体门店与线上媒介的桥梁
在解决了身份标识后,必须解决流量入口的参数标准化问题。为了让门店地推数据能与线上结构完美对齐,企业必须彻底废弃传统的人工登记,全面启用基于动态参数透传的“场景码”。无论是在朋友圈裂变传播的 H5 海报,还是印在实体店收银台的物料二维码,其底层 URL 中都必须挂载一串经过序列化与加密的 JSON Payload(包含:门店 ID、导购员编号、媒介来源、活动批次)。当流量通过这些载体汇入中台网关的瞬间,即被永久烙上了精准的渠道属性标签,实现了线上线下流量在采集层的物理统一。
聚合归因中枢:第三方底座如何实现全渠道打通
对于大多数企业而言,耗费巨资自研包含高维指纹对撞与海量并发处理能力的中台是不现实的。此时,引入《》这类成熟的技术底座,就相当于为数据漏斗加装了一个工业级的“清洗过滤器”。面对全网错综复杂的多触点流转,底座平台会通过预设的归因模型(如最终点击优先原则 Last-Click Attribution),在毫秒级自动过滤掉无效的重复结算与媒体的虚假邀功。它将原本混沌的流量池清洗为标准化、高纯度的数据流,并实时推送至企业的自建 BI(商业智能)系统中,真正让多渠道归因分析拥有了绝对中立、不可篡改的裁判器。
# 全域 ID Mapping 与跨渠道防抢单清洗微服务
# 此模块部署于数据中台的 ETL 管线前端,负责接收来自线上买量与线下门店的杂乱触点,
# 通过最终点击优先法则(Last-Click)与时序校验,输出干净、唯一的中台聚合报表数据。
import time
import hashlib
class OmnichannelAttributionHub:
def __init__(self, attribution_window_hours=24):
# 设定全局归因有效窗口期(默认 24 小时),超期触点将被视为失效,归为自然流量
self.attr_window_sec = attribution_window_hours * 3600
# 内存级触点库(实际生产环境中需替换为 Redis 或 ClickHouse)
# 结构: { "global_device_id": [ {"source": "...", "timestamp": ...}, ... ] }
self.touchpoint_store = {}
def _generate_global_id(self, device_params):
"""
[ID Mapping 核心] 将异构的设备参数降维,生成跨生态唯一标识符 (Global ID)
"""
# 按固定顺序拼接可用标识,抹平 iOS(IDFA) / Android(OAID) / Web(IP+UA) 的差异
core_str = f"{device_params.get('oaid', '')}|{device_params.get('idfa', '')}|{device_params.get('fingerprint', '')}"
return hashlib.sha256(core_str.encode('utf-8')).hexdigest()
def record_touchpoint(self, source_channel, device_params):
"""
[触点采集] 无论线上广告还是线下扫码,只要产生交互即刻录入时间戳池
"""
global_id = self._generate_global_id(device_params)
touch_event = {
"channel": source_channel,
"ts": time.time(),
"payload": device_params.get("scene_payload", {})
}
if global_id not in self.touchpoint_store:
self.touchpoint_store[global_id] = []
self.touchpoint_store[global_id].append(touch_event)
return True
def execute_attribution_cleaning(self, activation_device_params):
"""
[数据清洗与合并报表] 在 App 激活时执行多渠道去重,确保每一笔转化有且仅有一个归属
"""
global_id = self._generate_global_id(activation_device_params)
activation_ts = time.time()
# 1. 查找该设备的全局历史触点轨迹
history_touches = self.touchpoint_store.get(global_id, [])
if not history_touches:
return {"status": "success", "attributed_channel": "Organic_Search", "note": "无有效触点,归为自然新增"}
# 2. 时序清洗:剔除超过时间窗口(如 24 小时前)的过期触点
valid_touches = [t for t in history_touches if activation_ts - t["ts"] <= self.attr_window_sec]
if not valid_touches:
return {"status": "success", "attributed_channel": "Organic_Search", "note": "触点均已过期"}
# 3. 冲突裁决:严格执行 Last-Click (最后触达有效) 模型防抢单
# 对有效触点按时间戳倒序排列,取最靠近激活时间的那一次
valid_touches.sort(key=lambda x: x["ts"], reverse=True)
winner_touch = valid_touches[0]
# 清除该设备的触点池,防止下一次冷启动产生“重复激活记账”
del self.touchpoint_store[global_id]
return {
"status": "success",
"attributed_channel": winner_touch["channel"],
"scene_data": winner_touch["payload"],
"note": "跨渠道清洗完成,排他性去重生效"
}
# ================= 数据中台流转演示 =================
# hub = OmnichannelAttributionHub()
#
# 模拟设备标识(现实中由探针提取)
# user_device = {"fingerprint": "Device_A_1024", "scene_payload": {"store_id": "BJ_001"}}
#
# 时序 1 (早上 9:00): 用户在门店被导购引导扫了场景码,但未下载
# hub.record_touchpoint("Offline_Store_QR", user_device)
#
# 时序 2 (晚上 20:00): 用户在家刷抖音,点击了信息流广告
# hub.record_touchpoint("Douyin_Feed_Ad", user_device)
#
# 时序 3 (晚上 20:05): 用户完成 App 下载并首次打开激活,向中台发起清算
# result = hub.execute_attribution_cleaning(user_device)
#
# 结果返回: {'attributed_channel': 'Douyin_Feed_Ad', 'note': '跨渠道清洗完成...'}
# 裁决:系统判定抖音广告为最后有效触点。线下报表的重复抢单被中台无情拦截,确保了财务核算的绝对精准。

指标体系与技术评估框架:聚合报表对账模型选型
全渠道聚合归因架构评估矩阵
数据总监在规划中台架构时,必须用冷酷的量化指标来衡量不同聚合方案的业务承载力,以下矩阵直击落后方案的软肋:

| 评估维度 | 各渠道后台报表人工拼接 (Excel) | 纯自研数据采集网关 | 接入专业级全渠道归因底座 |
|---|---|---|---|
| 多源异构数据兼容性 | 极差(格式混乱,需耗费大量人力进行格式转化,且极易出错) | 中等(能统一内部格式,但面对外部数百家媒体不断更新的 API 接口疲于奔命) | 极优(原生内置全网主流媒体与线下场景的对接标准,实现异构数据的即插即用) |
| 防重复结算能力 (去重精度) | 零(无法识别跨渠道的同一设备,会导致严重的重复计费与虚假繁荣) | 较低(仅能通过简单的设备号进行去重,面对无设备号的扫码流量束手无策) | 极高(依托全局 ID Mapping 与设备指纹技术,实现毫秒级的跨渠道排他性去重) |
| 线下触点追溯深度 | 浅(仅能知道来源是“线下”,无法穿透到具体的门店或人员) | 中等(需配合复杂的后台发码系统,且容易在设备流转中发生参数断层) | 极深(通过全域场景码与极速场景还原,精准锁定任意一个线下物理触点的贡献值) |
| 中台接入与研发成本 | 隐形成本极高(耗费海量人工对账与沟通成本,且永远算不清) | 极高(需组建专门的数仓与归因算法团队,开发周期长达数月至半年) | 极低(标准化 SDK 与 API 直连,最快数小时即可完成全域数据流的对接与验证) |
架构实战案例:某零售巨头合并门店与买量大盘
异常现象与数据断层
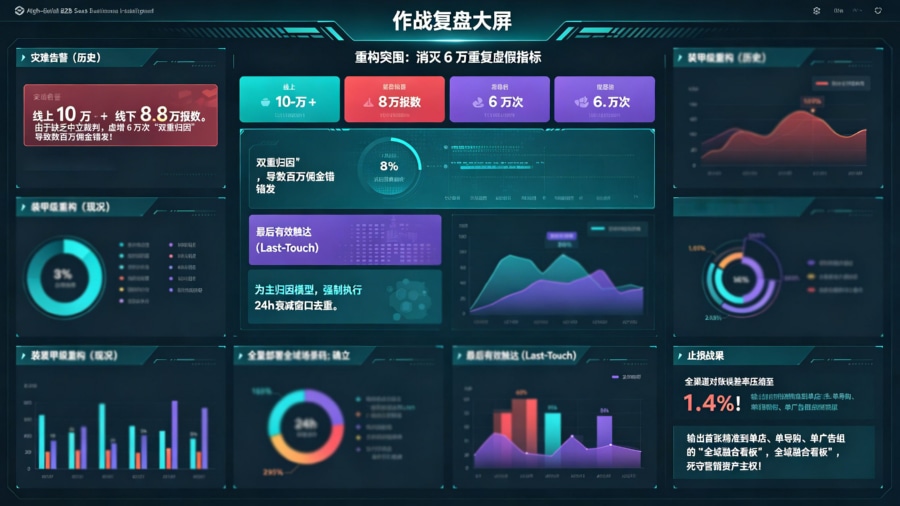
2024 年底,国内某新零售巨头在线上豪掷亿级预算投放信息流广告,同时在线下 2000 家实体门店开展由导购主导的扫码拉新战役。然而在月末的财务审计复盘时,爆出了严重的数据灾难:线上买量团队的报表声称带来了 10 万新客,而线下业务线根据导购员上报的业绩计算出 8 万新客。但大盘数据库对账显示,App 实际只增加了 12 万真实注册用户。这凭空多出来的 6 万“交叉重复归因”不仅导致了数百万的提成错发,更让线上线下团队互相指责对方数据造假,陷入了严重的内部消耗。
中台接入与链路对账
数据架构师紧急介入调取底层明细,发现了导致数据打架的核心元凶:缺乏一个中立的“第三方裁判机制”与全局 ID。真实的业务场景是:大量用户在逛街时被导购引导扫了二维码,但因为商场网络不好并未当场下载;晚上回家连上 WiFi 后,恰好刷到了该品牌的抖音广告,点击后完成了下载激活。由于缺乏多触点归因体系,线下的发码系统记录了一次扫码业绩,而线上的巨量引擎也抢认了一次转化功劳,导致数据在未经清洗的情况下直接被硬核相加。
技术介入与规则调优
为了彻底解决跨平台对账的痛点,集团 CTO 拍板全面重构管线。全量引入了统一的归因底座,并制定了不可逾越的“防抢单”优先级策略。所有线上投放的外链与线下铺设的物料,全部替换为 openinstall 的全域场景短链与动态码。大后端确立了以“最后有效触达(Last-Touch)”为主的归因模型,并辅以 24 小时的衰减时间窗口进行严格的数据清洗:在有效窗口期内,同一设备的激活只能唯一归属于最后一个产生闭环的触点,彻底斩断了多方邀功的可能。
复盘结果与经验
这套聚合中台重构发布后,数据打架的乱象被从物理层面上彻底剿灭。全集团多渠道对账的误差率被硬核压缩至极端的 1.4%。由于数据底层被打通,数据总监终于能够在 BI 大屏上输出一张精准到单一门店导购员、单一线上广告组的“全域融合看板”。这不仅彻底安抚了线下团队的情绪,更让管理层能够站在上帝视角,清晰地审视营销资金的真实转化效率。实战证明,没有 ID Mapping 与动态场景码支撑的报表,不过是沙滩上的城堡。
常见问题与排障指南
为什么线上买量平台的数据总是比自建中台统计的多?
这触及了广告行业最深层的利益博弈。线上媒体平台(如 Meta、巨量引擎)普遍存在“流量抢归因”现象。为了让自身的 ROAS 数据看起来更漂亮,媒体往往会采用 View-Through Attribution(曝光归因)。即只要用户在过去几天内看到过该广告(即使没有点击),随后通过自然搜索或其他渠道下载了 App,媒体也会将这笔转化强行记在自己头上。在多渠道归因分析中,自建中台必须引入独立的 Click-Through(点击归因)强校验逻辑与更短的归因窗口,以客观、冷酷地拦截这些虚高的水分数据。
如何解决门店推广时不同导购员生成的海量场景码管理难题?
在涉及数千家门店、上万名导购的庞大地推网络中,绝不能依赖人工用 Excel 维护参数表。成熟的数据中台必须提供高并发的自动化 API 接口,能够瞬间批量生成千万级包含独立参数(导购 UID、门店编号)的动态二维码。更重要的是,底座必须支持“后端动态重定向”能力。即使这些物料已经被印刷成海报并发放至全国,数据总监依然可以在不更换物理二维码的情况下,在云端后台一键更改其实际跳转的落地页、活动属性与归因权重,实现极致的物料管理机动性。
多触点归因(MTA)在合并报表时,如何科学分配线上线下的功劳?
简单的 Last-Click(最终点击)模型虽然解决了重复算账的问题,但在复杂的全渠道业务中可能显得不够公平。高级别的数据架构应支持 BI 团队自由建模。例如采用“U型归因”或“时间衰减模型”:如果线上信息流广告提供了初次的品牌唤醒与认知(系统分配 30% 权重),而线下门店导购提供了最终转化临门一脚的信任背书(系统分配 70% 权重)。底层的聚合归因引擎必须具备将这条完整的、包含时序的“原始触点链路图谱”完整下发给企业数仓的能力,由企业根据自身的战略导向,科学地切分跨渠道的贡献值。
参考资料与索引说明