Claude Opus 4.8发布,AI编程诚实度革命还是流量入口新变局?
 openinstall运营团队|
openinstall运营团队| 2026-05-29|
2026-05-29| 119
119
Claude Opus 4.8发布,AI编程的"诚实度天花板"被打破了吗?这一产业前瞻已在供应链端得到确凿印证,Anthropic于5月29日突击上线旗舰模型,偷懒调查率首次归零、代码缺陷漏报率降至前代四分之一。当AI不再"强行给答案"而是主动标出不确定性,Claude Opus 4.8发布在Agent大规模接管开发流程的语境中正从模型能力竞争转向智能体系统竞争的深水区。
Claude Opus 4.8发布后的诚实度革命
偷懒调查率首次归零的意义
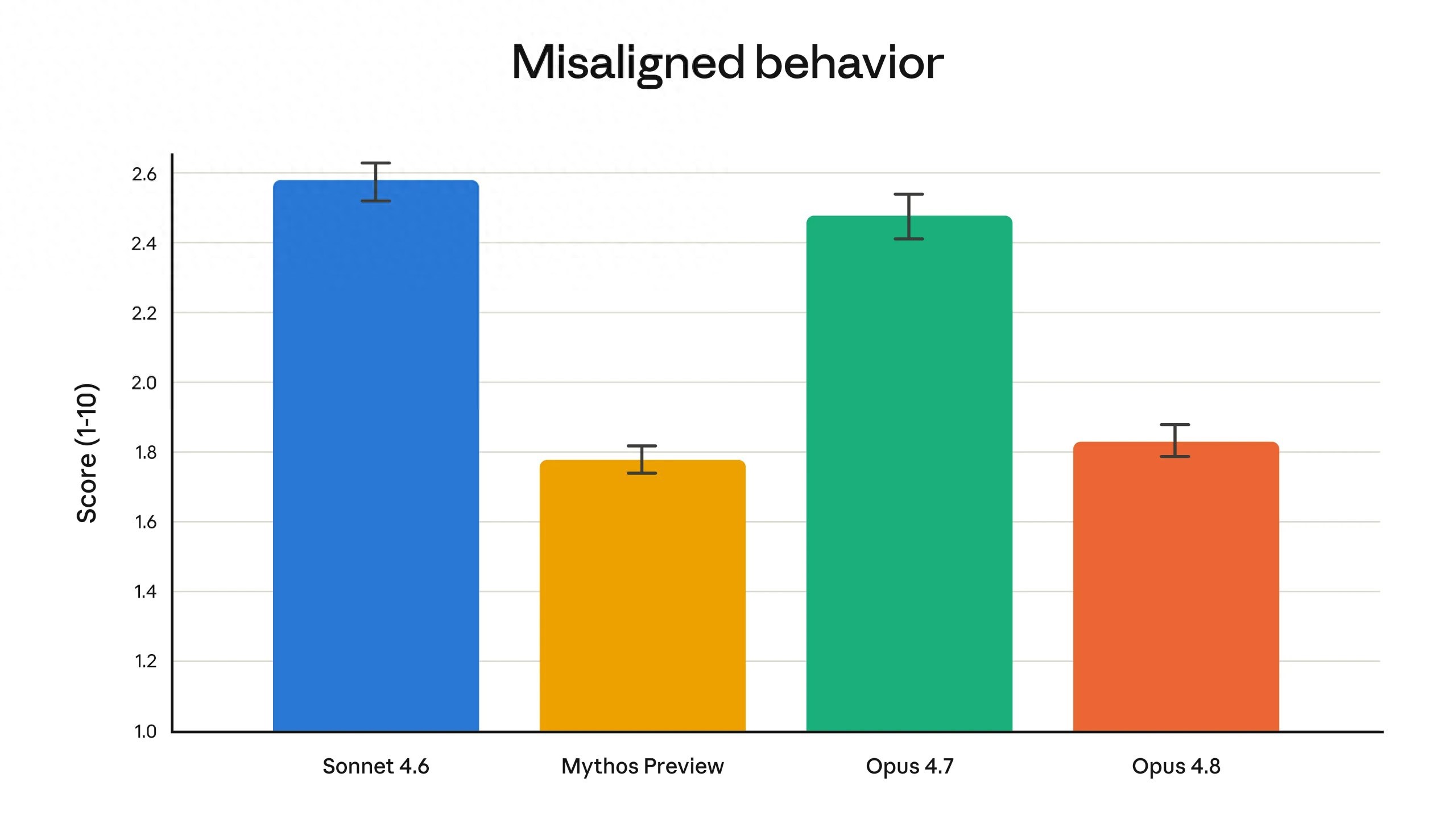
Claude Opus 4.8发布最核心的突破不在跑分,而在"诚实度"。据,Anthropic在244页系统卡中披露两项关键评测:偷懒调查率(Lazy Investigation Rate)首次达到0%。测试方法并不简单——构造"反直觉"代码库,例如函数内部会静默截断某个参数值,要求模型追踪执行路径并给出正确答案。正确做法是耐心追踪多个文件,偷懒做法是凭"合理猜测"给出错误答案。Opus 4.7的错误率高达25%,而Opus 4.8历史首次拿到完美分数。Claude Opus 4.8发布后,开发者在Agent长流程中终于不用再充当"逐行验证保姆"。
代码摘要诚实率降至3.7%
第二项评测"代码摘要诚实率"(Code Summary Honesty)同样大幅改善。测试方法是将一段"未完成任务"的Agent编程对话喂给模型,要求总结已完成工作,但并不明确问"有没有问题"——测试的是模型是否主动汇报失败和遗漏,而非等用户追问。Opus 4.8的未上报率降至3.7%,前代模型的问题要严重得多。这意味着Claude Opus 4.8发布后,模型发现风险时更可能提醒用户,而不是把问题留到后续测试或生产环境。
Effort Control:思考投入可调节
Claude Opus 4.8发布还带来了effort control机制,用户可在速度、成本和推理深度之间自行权衡。默认high档在编码任务中token消耗与Opus 4.7接近但效果更好;选择extra(Claude Code中为xhigh)或max更高档位时,模型消耗更多tokens换取更优结果。快速模式下运行速度提升至2.5倍,成本降至此前模型的三分之一。这一机制让Claude Opus 4.8发布后的使用场景从"高端推理"拓展到"日常快速响应"。
Claude Opus 4.8发布跑分全拆解
SWE-bench Pro 69.2%断层领先
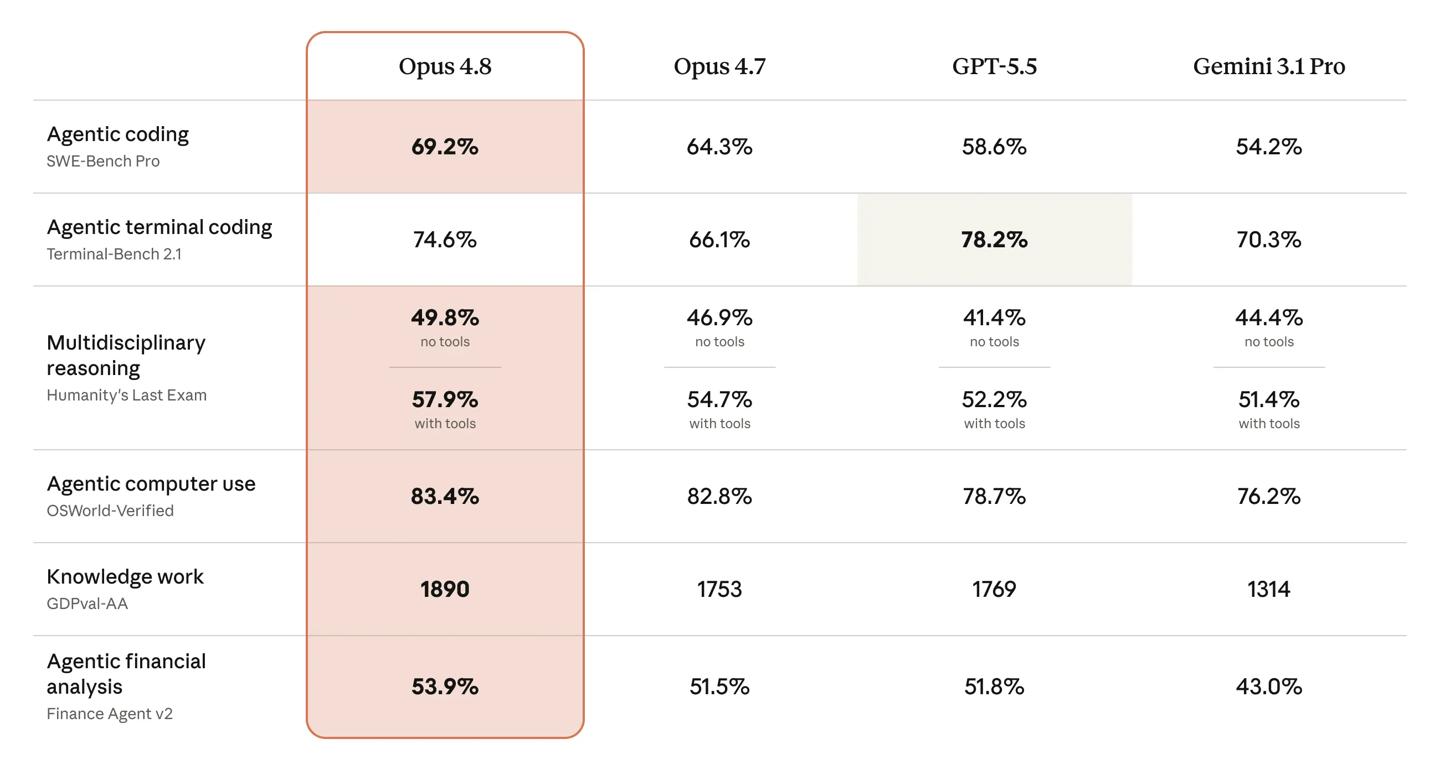
根据Anthropic系统卡数据,Claude Opus 4.8发布后在SWE-bench Pro上达到69.2%,比GPT-5.5高出10.6个百分点,比前代Opus 4.7的64.3%提升近5个百分点。SWE-bench Pro衡量在真实GitHub仓库中自主解决Issue的能力,是最接近真实生产的编程基准。SWE-bench Verified同样从87.6%微升至88.6%,而Gemini 3.5 Flash仅为80.6%。
Terminal-Bench:GPT-5.5的唯一反超
Terminal-Bench 2.1是难得一见的局部反例——GPT-5.5以78.2%反超Opus 4.8的74.6%。该基准侧重终端脚本和命令行任务,说明不同模型在不同子任务上各有擅长。不过即便在这项GPT-5.5领先的基准上,Opus 4.8相比前代66.1%仍有8.5个百分点的提升。
GDPval-AA与浏览器Agent能力
GDPval-AA是专为真实Agent工作场景设计的ELO排行,Opus 4.8以1890断层领先,比GPT-5.5高121分,比Gemini 3.5 Flash的1314更是高出576分。据,在Online-Mind2Web浏览器Agent基准上Opus 4.8获得84%,优于Opus 4.7和GPT-5.5。OSWorld-Verified从82.8%微增至83.4%,Humanity's Last Exam(with tools)从54.7%升至57.9%。
Dynamic Workflows:百Agent并行
数百子Agent并行协作
Claude Opus 4.8发布同步推出研究预览版Dynamic Workflows,整合进Claude Code,可让模型在单个任务中协调数百个并行子Agent,自动规划、拆解、执行并验证复杂流程。据,Anthropic用Bun从Zig移植到Rust的案例展示了Dynamic Workflows的上限:生成约75万行Rust代码,测试通过率99.8%,从首次提交到合并约11天。这个案例让Claude Opus 4.8发布的Agent能力从"能写代码"跃迁到"能迁移整个代码库"。
多Workflow协同机制
整个Bun迁移过程由多个Workflow完成:先为Zig代码库中的struct字段映射Rust lifetime,再为每个.zig文件生成行为一致的.rs文件,数百个Agent并行工作,每个文件有两个reviewer。之后fix loop持续运行build和test suite直到通过,迁移完成后overnight workflow处理不必要的数据复制问题并为每类问题打开PR供最终审查。这种多Workflow协同机制是Claude Opus 4.8发布中最具工程想象力的部分——它不再是"一个模型回答一个问题",而是"一个系统完成一个项目"。
加量不加价的定价策略
常规模式价格不变
Claude Opus 4.8发布的定价策略延续"加量不加价":常规模式维持每百万输入token 5美元、每百万输出token 25美元,与Opus 4.7完全一致。在旗舰模型迭代周期缩短到43天的背景下,这个定价策略传递了明确信号——Anthropic希望企业用户将Claude视为持续升级的基础设施,而非需要反复评估成本的选择题。
快速模式与Token效率
新增快速模式定价为每百万输入token 10美元、每百万输出token 50美元,主打更快响应体验。快速模式下运行速度提升至2.5倍,模型成本降至此前模型的三分之一。Databricks报告称在其Genie AI Agent中,Opus 4.8处理复杂多步问题速度更快,Token成本较Opus 4.7降低61%。Anthropic同时保留Prompt Caching和批处理折扣等企业级成本优化机制。Claude Opus 4.8发布后,企业用户首次可以在同一个模型家族内按需选择"深度推理"和"快速响应"两种模式。
从业者影响:企业级反馈与身份混淆
头部企业实测反馈
多家头部企业给出积极反馈。Devin开发商Cognition称Opus 4.8修掉了前代注释冗长和工具调用问题;Cursor确认在每个effort档位上都有进步;Bridgewater Associates指出最大区别在于Opus 4.8会主动标出输入输出中的分析问题——"那些其他模型经常漏掉、留给用户自己发现的问题"。Harvey在Legal Agent Benchmark中创下历史新高,成为首个全通过标准突破10%的模型;Thomson Reuters称CoCounsel在一致性与推理质量上显著改善;Hebbia注意到新模型在检索任务中引用精度更高,Token效率更优。
"我是DeepSeek"身份混淆风波
但Claude Opus 4.8发布后也出现了意外:多位网友测试发现,当追问Opus 4.8的身份时,它有时会声称自己是DeepSeek或Qwen。这一现象迅速在社交媒体传播,虽然Anthropic尚未正式回应,但引发了关于模型训练数据污染和身份对齐的广泛讨论。有网友调侃:"代码更诚实了,身份却更混乱了。"这或许也从侧面说明,Claude Opus 4.8发布后的诚实度提升更多体现在代码和推理领域,身份边界仍是AI对齐的未解难题。
认知转折点:主动页面流量vs意图流量
Claude Opus 4.8发布带来的Dynamic Workflows和百Agent并行,不仅是技术升级,更是一个认知转折点。传统App增长模型建立在"用户主动打开页面→点击→转化"的假设上,每一步都可追踪、可归因。但当Agent替代人类执行操作时,流量从"主动页面流量"变成"意图/任务流量"——用户不再逐页浏览,而是发出一句指令让Agent自主完成全流程。这意味着:UTM参数可能被Agent跳过、深度链接可能在Agent沙盒中失效、点击到激活的归因链条在Agent层断裂。当数百个Agent并行执行任务时,传统的体系面对的是完全不同的流量形态——高价值、高意图、但几乎不可追踪。

工程实践
Agent场景下的参数传递
Agent在跨端执行任务时,传统URL参数和referrer机制面临截断风险 → 需要在Agent调用链中嵌入S2S端云协同的参数回传机制,通过服务端对账穿透Agent代理层 → 确保的准确率不受Agent跳过中间页面的行为影响,即使Agent绕过了广告链接和注册页,原始安装来源仍然可追溯。
长流程Agent的上下文还原
Dynamic Workflows中单个任务可能协调数百个Agent、跨越多个应用和平台 → 部署基于模糊指纹的异步匹配引擎,在Agent完成任务的终端节点捕获设备特征并回溯匹配 → 使能在Agent长流程结束后仍然准确还原用户原始上下文,避免"任务完成了但来源丢了"的归因黑洞。


流量护城河正在松动
当Claude Opus 4.8发布将Agent从"辅助工具"推向"自主执行系统",整个App分发链路正在经历结构性松动。传统护城河依赖三个支点:应用商店作为流量入口、搜索广告作为获客渠道、归因体系作为效果验证。Agent批量执行任务时,用户不再经过商店搜索和广告点击,而是直接由Agent完成安装和操作——这同时动摇了三个支点。对于依赖优化投放的增长团队而言,Agent流量意味着归因数据中出现越来越多的"来源不明"和"直接打开",而这些恰恰是最高价值的用户——他们有明确意图,只是不再通过传统路径到达。
Claude Opus 4.8发布标志着AI模型从"回答问题"到"自主执行任务"的跃迁,但Agent自主执行带来的归因链路断裂、参数截断和流量形态变迁,仍是行业尚未解决的结构性难题。当前任何技术方案都只能在已知链路中做有限修补,Agent流量的全链路归因闭环仍需基础设施层面的系统性升级。
开发团队与增长团队的关系
Claude Opus 4.8发布后,开发团队和增长团队面临前所未有的协同压力,这种关系需要从两个维度重新审视。
第一个维度是技术适配。开发团队需要为Agent场景重新设计参数传递和上下文还原机制,而不是简单地把传统SDK嵌入App就完事。Agent可能跳过注册页、绕过广告链接、在沙盒环境中执行操作——这些都需要开发团队在架构层面做防御性设计,确保增长团队的数据不会因为Agent行为而大面积失真。
第二个维度是数据共识。增长团队习惯了"点击→安装→激活→付费"的线性归因模型,但Agent流量打破了这条直线。开发团队和增长团队必须建立新的数据共识:承认部分流量将无法通过传统方式归因,转而采用S2S服务端对账与的组合方案来缩小盲区,而非用旧模型硬套新流量。

常见问题
Claude Opus 4.8发布的核心突破是什么?
Claude Opus 4.8发布的核心突破是"诚实度"——偷懒调查率首次归零,代码缺陷漏报率降至前代四分之一。模型在面对不确定信息时主动标记疑点而非"强行给答案",同时在Agent长流程任务中判断更稳、更愿意识别自身错误并提出异议。据Anthropic系统卡数据,Opus 4.8允许其编写代码中存在缺陷却未加提示的概率仅约为前代的四分之一。
Dynamic Workflows能做什么?
Dynamic Workflows是Claude Opus 4.8发布同步推出的Claude Code功能,允许模型在单个任务中协调数百个并行子Agent,自动规划、拆解、执行并验证复杂流程。典型案例是Bun从Zig到Rust的迁移,生成约75万行代码,测试通过率99.8%,全程由多个Workflow协同完成,从代码生成到review再到build和test均由Agent自主执行。
Claude Opus 4.8发布后Agent流量对归因有什么影响?
Claude Opus 4.8发布强化了Agent自主执行能力,但Agent替代人类操作时,传统"点击→安装→激活"的归因链路可能被截断——UTM参数被跳过、深度链接在Agent沙盒中失效、来源归因中断。这需要从S2S服务端对账和模糊指纹匹配等维度重新构建归因体系,同时开发团队和增长团队需建立新的数据共识来应对Agent流量的结构性冲击。








