大模型也"乱回"?DeepSeek漏洞引爆信任危机,数据真实性防线正被冲垮
 openinstall运营团队|
openinstall运营团队| 2026-05-20|
2026-05-20| 148
148
大模型也"乱回"?这场波及全网的模型信任地震已得到官方确凿回应,DeepSeek漏洞正以不可逆的姿态引爆信任危机,数据真实性防线正被冲垮。2026年5月18日,多位用户在社交平台集中爆料:DeepSeek网页版出现诡异"串台"现象——在空白对话框中输入<think特定字符后,模型不会报错或要求澄清,而是直接开始输出一段段与当前对话上下文毫无关联的问答内容。这些内容包罗万象,从"牛奶麻薯"的小红书笔记文案到公司战略分析、考试题目,甚至有用户声称看到了他人八字相关的隐私信息。5月19日,DeepSeek官方发布《关于字符触发模型异常回复的说明》,将问题定性为"特殊字符引发的模型幻觉",明确否认涉及安全问题或隐私泄露。但这纸声明并没有让质疑平息——当AI连自己说了什么都不可控,当幻觉可以被特殊字符精准触发,黑灰产利用这一机制批量伪造转化凭证的通道就已经被悄然打开。在这场由DeepSeek漏洞标志的信任危机中,广告归因与反作弊体系必须思考:当大模型的"不可控输出"变成黑产的"可控武器",传统图文验证防线还撑得住吗?

"串台"始末:几个字符让大模型胡言乱语
5月15日前后,首批用户在社交平台报告异常。现象极其诡谲:在DeepSeek网页版新建的空白对话中,仅输入<think特定字符后发送,模型不会像正常情况那样提示"请输入有效问题",而是直接开始输出一段看似完整、但与用户输入完全无关的问答内容。
贝壳财经记者随即进行了实测。测试结果令人吃惊:进入DeepSeek的"快速模式"后,无论是否加载深度思考和智能搜索两项功能,只要输入上述字符,DeepSeek均会直接开始回答。记者进行了十多次测试,发现其回复的问题包括文案撰写、对某公司的战略分析、考试题目等等。更令人不安的是,当记者追问"我刚刚问了你什么问题?"时,DeepSeek会复述出该问题的提问内容——但它复述的那个问题,记者从未输入过。比如在一次测试中,DeepSeek声称记者刚刚询问了"'牛奶麻薯'的小红书笔记文案创作,并要求以美食博主的身份,体现'网红零食'和'治愈系'风格。"但记者实际输入的只是一串特殊字符。

有用户反馈称,这些题目疑似其他用户所提的问题,甚至有用户测试时还出现过他人八字相关的隐私内容。一时间,"DeepSeek泄露用户对话"的说法在社交平台广泛传播。
官方定性:模型幻觉,不是数据泄露
5月19日,DeepSeek官方账号发布《关于字符触发模型异常回复的说明》。据报道,声明的核心结论只有一句:输入<think特殊字符等触发返回异常内容,属于特殊字符引发的模型幻觉,不涉及安全问题或隐私泄露。
DeepSeek表示,后续将通过针对性训练增强模型对特殊字符的识别与处理能力,修复已知问题,优化模型在此类场景中的表现。
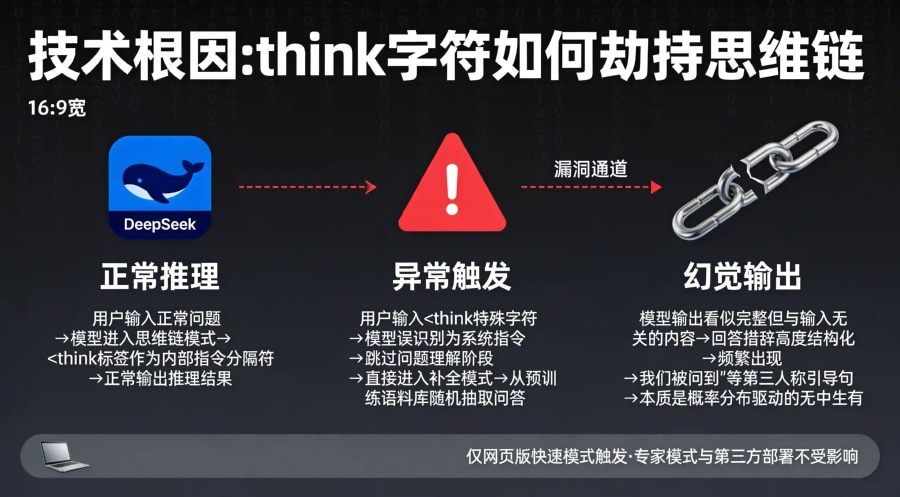
为何官方敢断言"不是泄露"?有技术人员在完全断网的本地部署环境中复现了相同现象——本地环境与外部网络及其他用户物理隔离,模型输出的内容只能来源于其本身内置的权重和参数,不可能调取其他用户的实时对话记录。这从技术上排除了"实时串入其他用户会话"的可能性。
据界面新闻报道,问题的技术根因在于:<think字符在模型训练和内部推理过程中,很可能被用作一种特殊的指令标记或分隔符,用于引导模型进入"思维链"推理模式。当普通用户在前端对话界面意外输入此字符时,模型错误地将其识别为系统指令,从而触发了一种非预期的行为模式——它试图补全一个它"认为"应该存在的、但用户并未实际提供的"问题",进而从庞大的预训练语料库中随机抽取或生成一段结构化问答内容进行输出。这不是调取了其他用户的对话记录,而是模型基于训练数据中的概率分布进行的"无中生有"的补全。

值得注意的是,贝壳财经记者发现该Bug只存在于DeepSeek网页版——在元宝选择DeepSeek模型后输入同样内容就不会触发,DeepSeek的专家模式也不会触发。这说明问题出在网页版的特定推理通道配置,而非模型本身的底层架构缺陷。
幻觉不是DeepSeek独有:行业级数据触目惊心
"模型幻觉"不是DeepSeek的专属问题,而是当前大语言模型行业普遍存在的技术难题。但这次事件的特殊性在于:幻觉被特殊字符精准、可重复地触发了——这把"随机出现"的缺陷变成了"可控触发"的漏洞。
据,上海申银万国证券研究所今年1月发布的报告指出,大模型的幻觉主要包括无中生有、事实错误、语境误解、逻辑谬误等,其根源可能来自模型架构、训练数据质量、奖励目标设计以及上下文窗口限制等多方面因素。该报告预计,通过RAG(检索增强生成)等工程化手段,2026年AI模型的幻觉将得到一定程度的有效控制。
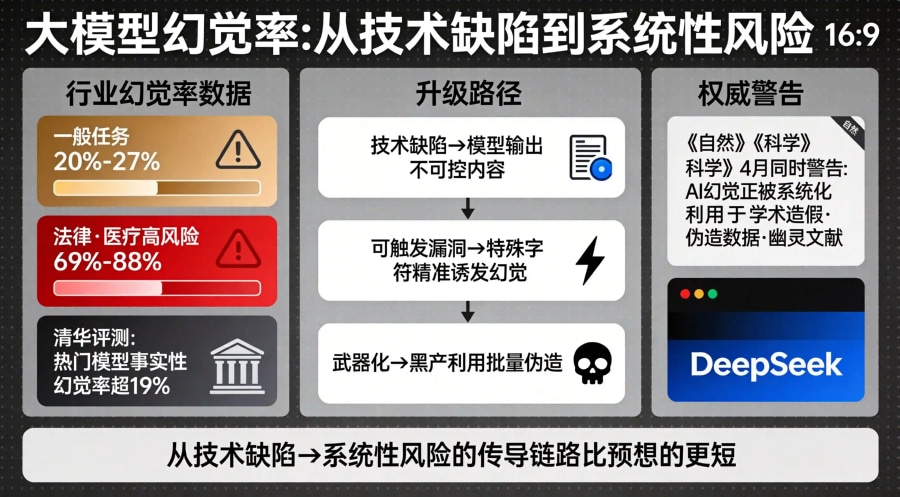
然而,现实数据依然严峻。国际测评数据显示,大型语言模型的幻觉率差异巨大——在一般任务中多数模型处于20%至27%的区间,但在法律、医疗等高风险领域,幻觉率可飙升至69%至88%。清华大学新闻与传播学院新媒体研究中心的一项评测也发现,市场上多个热门大模型的事实性幻觉率超过19%。
更令人担忧的趋势是,AI幻觉正从技术缺陷演变为系统性风险。《自然》《科学》等顶级期刊在今年4月初同时发声,警告AI大模型的"幻觉"缺陷正被系统化利用,用于批量生成带有伪造数据和"幽灵文献"的科研论文,对学术诚信构成严重污染。当幻觉可以从学术造假延伸到商业欺诈,从论文伪造扩展到转化凭证伪造,这条传导链路比任何人预想的都要短。
从模型幻觉到归因黑产:一条比想象更短的传导链
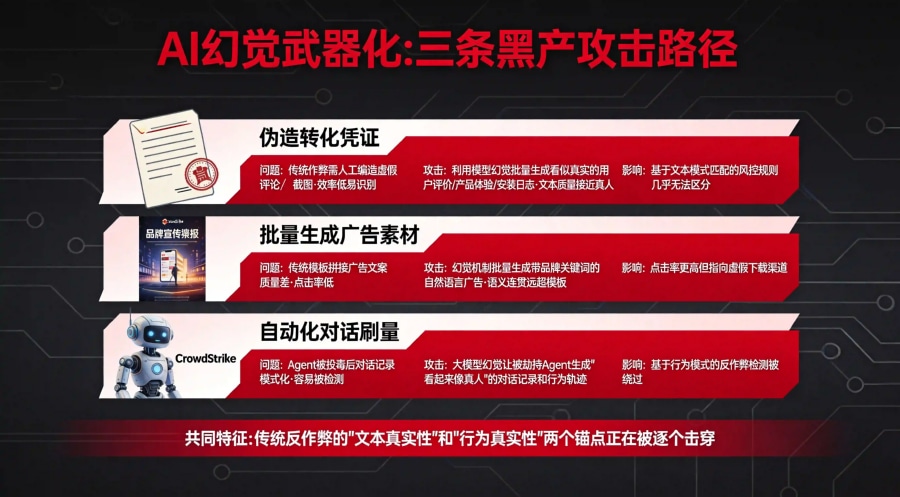
当DeepSeek漏洞证明"特殊字符可以精准触发AI生成特定类型的内容",黑灰产的武器库就多了一件效率极高的自动化工具。
伪造转化凭证。传统广告作弊需要人工编写虚假评论、伪造下载截图,效率低且容易被模式识别。但利用大模型幻觉,黑产可以用特殊字符或精心构造的prompt批量生成看似真实的用户评价、产品体验报告、甚至带具体参数的安装日志。这些"AI伪造凭证"在文本质量上与真人撰写高度接近,传统基于文本模式匹配的风控规则几乎无法区分。
批量生成广告素材骗取点击。黑产可以利用幻觉机制批量生成带有品牌关键词的"自然语言"广告文案,投放到搜索引擎和社交平台。这些AI生成的文案在语义连贯性上远超传统模板拼接,点击率更高,但指向的是虚假下载渠道。
自动化对话刷量。当Agent被投毒变成刷量工具(CrowdStrike已在安全报告中揭露了工具投毒、冒充和Rugpull三大攻击手法),大模型幻觉可以被用来让被劫持的Agent生成"看起来像真人"的对话记录和行为轨迹,进一步绕过基于行为模式的反作弊检测。
这三条攻击路径的共同特征是:传统反作弊体系依赖的"文本真实性"和"行为真实性"两个锚点,正在被大模型幻觉逐个击穿。
工程实践:当AI幻觉武器化,反作弊必须后撤到物理时序层
面对大模型幻觉从技术缺陷向黑产工具的武器化转变,广告归因与反作弊体系必须从"内容验证"后撤到"物理时序验证"。文本可以被AI生成,但时间不能。
CTIT物理风控:用点击到激活的时间差绞杀伪造流量
当黑产利用大模型幻觉批量生成看似真实的转化凭证时,基于内容模式的风控防线已经失效——AI生成的文本在语义和结构上与真人内容高度接近。解决方案是在底层部署基于CTIT(Click-to-Install Time,点击至安装时间差)的物理风控雷达。真实用户的转化路径存在不可压缩的物理时间下限:从看到广告→产生兴趣→点击→进入应用商店→下载→激活,整个过程至少需要数十秒到数分钟。而自动化刷量脚本的CTIT分布呈现极端聚集——要么秒级完成(脚本自动点击+自动安装),要么超长延迟(定时任务批量激活)。通过分析CTIT分布的物理特征,可以有效区分"真人自然转化"和"AI伪造+脚本自动化"。
核心做法:在体系中,为每一次点击记录精确到毫秒的时间戳,与App激活时间进行碰撞核对,生成CTIT物理分布图。将CTIT异常聚集区间的流量自动标记为高风险,进入人工复核队列。
行业前瞻提示:针对大模型幻觉被黑产武器化批量伪造转化凭证等前沿风险场景,openinstall技术实验室目前正与部分头部App展开定向的联合探索。
S2S端云对账:不信任任何前端提交的数据
大模型幻觉可以伪造文本内容,但不能伪造云端记录。当AI生成的虚假凭证试图绕过前端验证时,必须在服务端建立独立的对账体系——在云端记录每一次广告点击的设备指纹、IP、时间戳和业务特征,在App激活瞬间与云端记录进行异步碰撞核对。前端提交的任何参数(包括AI伪造的"真实"参数),都必须在云端找到对应的签发记录才算有效。没有云端签发记录的前端参数,一律视为伪造。
这种S2S(Server-to-Server)对账体系的关键在于:验证逻辑全部在服务端闭环,不信任任何前端提交的数据。即使黑产用大模型生成了"完美"的转化凭证,只要该凭证在云端没有对应的真实签发记录,就无法通过归因验证。
这件事和开发、增长团队的关系
面向开发与架构团队
当大模型幻觉可以被精准触发并武器化,开发团队必须重新评估现有反作弊引擎的脆弱性。基于文本模式匹配的规则引擎(如关键词黑名单、文案重复度检测)在面对AI生成内容时几乎失效。架构层面需要预留CTIT物理风控模块的接入位置,将的时间戳精度提升到毫秒级,并在S2S对账链路中实施Nonce防重放攻击机制,确保同一笔转化不能被重复提交核销。同时,需要为反作弊模型预留"幻觉检测"特征的扩展接口——未来可能需要识别"AI生成痕迹"作为风控信号。
面向产品与增长运营团队
当AI生成内容与真人内容的边界日益模糊,增长团队不能再把"转化凭证看起来真实"等同于"转化确实发生"。预算策略需要从"按量买单"转向"按质买单"——将更多预算向经过CTIT物理校验和S2S对账双重验证的流量倾斜,而不是为无法验证真实性的"高转化"流量买单。同时,需要建立异常流量波动的实时监控机制:当某个渠道的CTIT分布突然出现异常聚集(如大量转化的点击到激活时间完全相同),立即触发风控预警并暂停该渠道的预算消耗。

常见问题(FAQ)
DeepSeek"乱回"漏洞的技术根因是什么?
问题的根因是<think特殊字符在模型内部被用作思维链推理模式的指令标记。当用户在前端输入此字符时,模型错误地将其识别为系统指令,触发了非预期的补全行为——从预训练语料库中随机抽取或生成一段结构化问答内容输出。这不是调取了其他用户的实时对话记录,而是模型基于概率分布的"幻觉"输出。有技术人员在完全断网的本地部署环境中复现了相同现象,从技术上排除了实时数据泄露的可能性。
大模型幻觉率到底有多高?
国际测评数据显示,大型语言模型在一般任务中的幻觉率约为20%至27%,但在法律、医疗等高风险领域,幻觉率可飙升至69%至88%。清华大学新媒体研究中心的评测发现,多个热门大模型的事实性幻觉率超过19%。更严峻的是,《自然》《科学》等顶级期刊已警告AI幻觉正被系统化利用于学术造假,从技术缺陷演变为系统性风险。
AI幻觉被武器化后,传统反作弊防线为什么撑不住?
传统反作弊体系依赖两个锚点:"文本真实性"(内容看起来像真人写的)和"行为真实性"(操作轨迹像真人做的)。但大模型幻觉可以批量生成语义上高度逼真的文本内容,击穿"文本真实性"防线;被投毒的AI Agent可以生成"看起来像真人"的对话记录和行为轨迹,击穿"行为真实性"防线。两条防线同时失守后,唯一不能被AI伪造的是物理时间——CTIT(点击至激活时间差)的分布特征遵循物理规律,无法被脚本加速或伪造。这就是反作弊必须后撤到物理时序层的原因。
行业动态观察
DeepSeek"乱回"漏洞不是一次偶发的技术事故,而是AI幻觉从技术缺陷走向武器化的里程碑事件。当特殊字符可以精准触发模型生成特定类型的内容,当20%-27%的幻觉率在商业欺诈场景中被系统化利用,当《自然》《科学》同时警告幻觉正在污染学术诚信——这条从"模型不可控输出"到"黑产可控武器"的传导链路,比任何人预想的都要短。