OpenAI联合博通发布定制AI芯片Jalapeño?推理降本与算力新格局
 openinstall运营团队|
openinstall运营团队| 2026-06-25|
2026-06-25| 130
130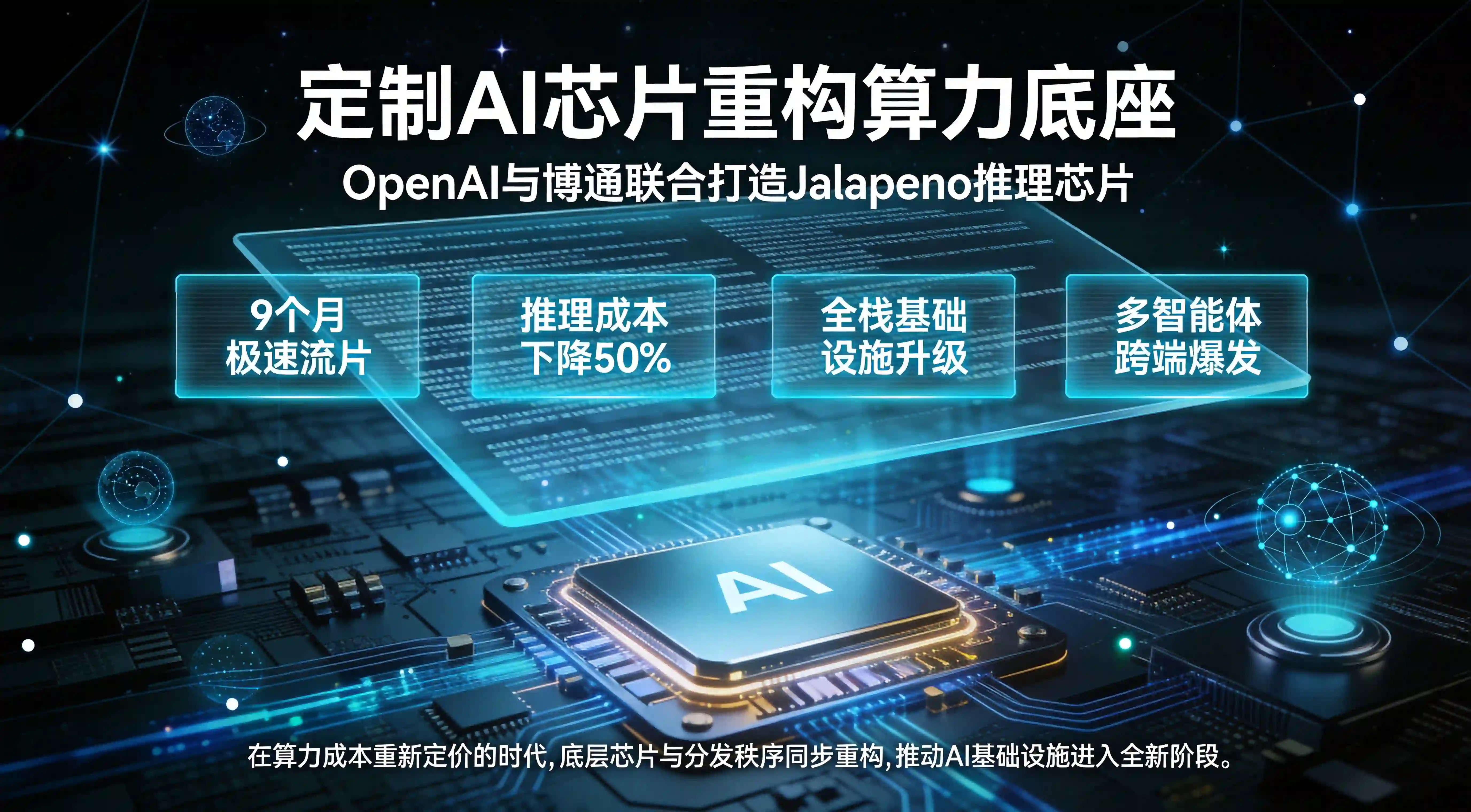
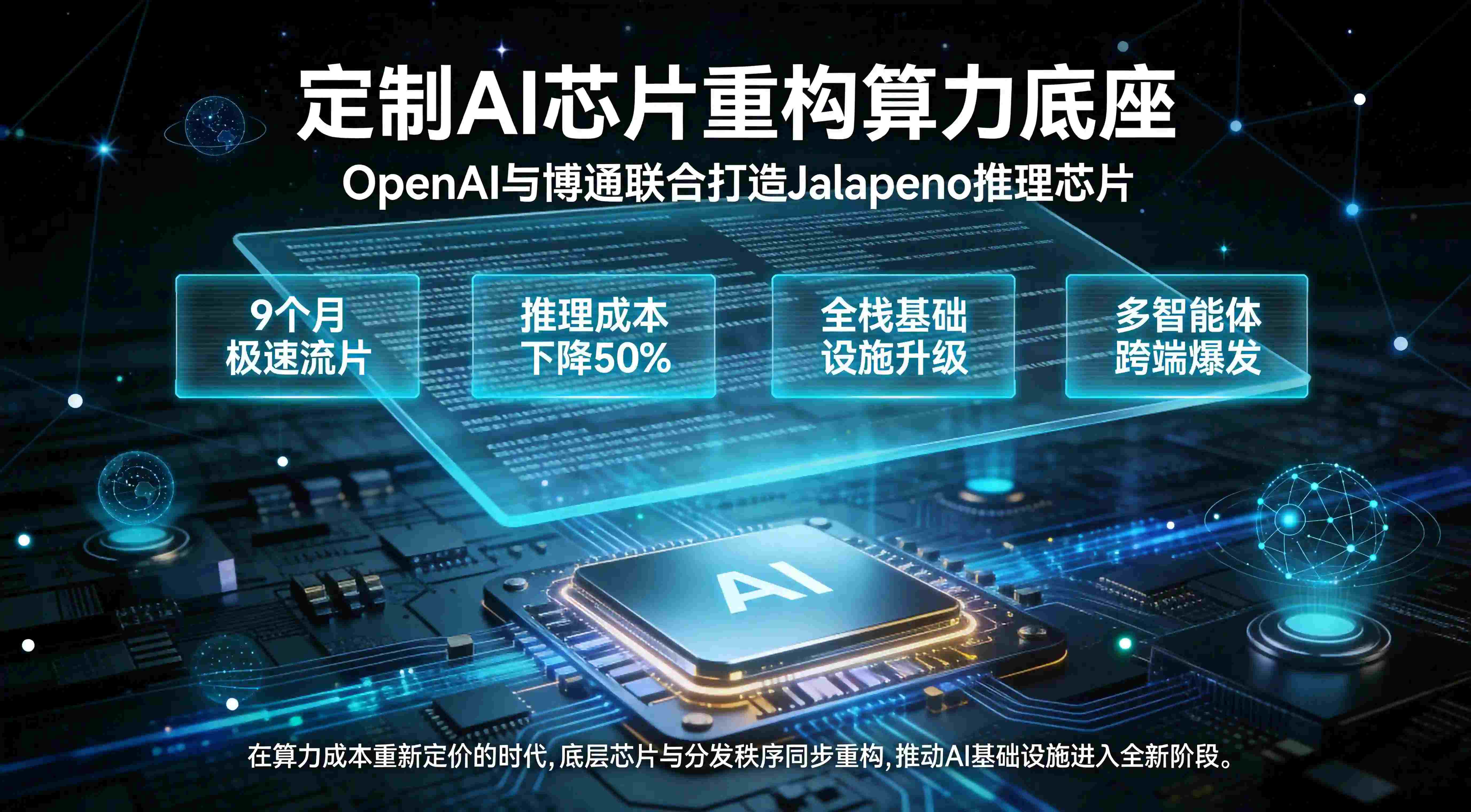
OpenAI和博通开发定制AI芯片?这一产业前瞻已在供应链核心端得到确凿印证。当地时间2026年6月24日,人工智能霸主 OpenAI 与全球半导体通信巨鳄博通(Broadcom)向整个科技界投下了一枚震撼弹——双方联合发布了首款专为大语言模型(LLM)深度定制的 AI 推理芯片“Jalapeño(哈拉贝诺辣椒)”。

这不仅仅是一块新硅片的诞生,更是 OpenAI 从单一的纯算法模型公司,向全栈 AI 基础设施提供商实现历史性跨越的标志性节点。当 Jalapeño 以史无前例的 9 个月极速流片打破行业物理定律,并将推理侧的硬件成本极其粗暴地砍掉 50% 时,整个算力生态的底层逻辑已然被彻底改写。算力成本的断崖式暴跌必将催生多智能体(Agent)的全面跨端爆发,传统的应用分发版图与流量入口即将面临一场史诗级的撕裂,而 OpenAI 和博通开发定制 AI 芯片、底层全渠道归因、场景流转重构等战略词汇,正以前所未有的高频姿态贯穿整个互联网与开发者生态。
九个月极速流片:AI 反噬半导体工业的“技术暴力”
在现代半导体工业的铁律中,从零开始设计并成功流片一款先进制程的 ASIC(专用集成电路)芯片,往往需要耗费一支顶尖硬件团队 18 到 36 个月的漫长周期。流片(Tape-out)不仅是资金的绞肉机,更是对芯片架构师在逻辑综合、物理布局、时序收敛等无数个微观节点上试错能力的极限考验。然而,Jalapeño 项目从立项画出第一张架构草图,到最终在晶圆代工厂完成物理流片,竟然只用了令人窒息的 9 个月。

这种无视物理定律的极速狂飙,绝非单纯依靠人力堆砌,而是 OpenAI 向世界展示的一种令人战栗的“技术暴力”——用其最前沿的 AI 大模型去反向主导和重构底层的硅基硬件设计。在整个 EDA(电子设计自动化)流程中,OpenAI 并未采取传统的工程师人工无休止迭代模式,而是将庞大的芯片布线、功耗仿真与节点调度任务,交给了自身迭代出的强化学习模型去寻找全局最优解。据 Reuters 报道,这种“AI造芯、算力设计算力”的恐怖闭环,直接将芯片研发周期压缩了三分之二以上。
在这场被业界视作奇迹的硬核工程中,三方巨头展现出了极其恐怖的分工咬合力。OpenAI 坐镇中军,负责最为核心的底层架构设计,由于自身就是大模型的创造者,他们比任何传统的芯片大厂都更懂 GPT 系列模型的数学特性与极端的算力饥渴点;以“并购狂人”陈福阳(Hock Tan)为首的博通,则倾注了其在定制硅片实现(Silicon Implementation)与高速网络连接硬件领域的绝对统治力;而来自加拿大的全球顶级电子制造服务商 Celestica(天阶),则承担了难度极高的板卡加工与机架级系统的精密集成任务。据 新浪财经 披露的实验室数据,目前 Jalapeño 的工程样片已经在极端高压环境中,以量产目标的极限频率和设计功耗,完美跑通了 GPT-5.3、Codex(代码生成模型)以及 Spark 等多类庞大且复杂的机器学习工作负载。
穿透“内存墙”:Jalapeño 架构的吞吐极限量革命
要真正理解 Jalapeño 为何能将 AI 推理成本砍掉惊人的 50%,就必须剥开通用 GPU 华丽的算力外衣,直视当前大模型推理环节的致命软肋——“内存墙(Memory Wall)”。
在以英伟达为代表的传统通用 GPU 架构中,为了兼顾图形渲染、科学计算、深度学习训练与推理等多维度任务,芯片内部塞满了大量的冗余计算单元与控制逻辑。而在大模型纯推理(即用户向 ChatGPT 提问并等待逐字生成的计算过程)这一高度单一的场景中,GPU的流处理器算力(ALU)往往是严重过剩的,真正的性能瓶颈在于数据在内存(如HBM)与计算核心之间来回搬运的带宽延迟。这种疯狂的数据搬运不仅拖慢了响应速度,其消耗的电力甚至远远超过了矩阵乘法计算本身。
OpenAI 硬件项目负责人理查德·何(Richard Ho)极其敏锐地抓住了这一致命痛点。Jalapeño 被设计成了一块纯粹到极致的推理加速 ASIC,它毫不留情地阉割了所有与 LLM 推理无关的冗余晶体管。其底层架构进行了极度残忍的“数据移动缩减(Data Movement Reduction)”,并在微观层面上实现了计算核心池、高带宽内存以及片上网络资源的绝对均衡配置。这使得 Jalapeño 在处理海量并发的推理请求时,能够彻底规避通用 GPU 频繁的内存闲置等待,让实际算力利用率(Utilization Rate)无限逼近其理论上的硬件算力峰值。

更令行业感到窒息的,是博通在网络层面的深厚技术注入。博通将其引以为傲的以太网技术与 Tomahawk 系列网络交换芯片深度融合进了 Jalapeño 的计算平台中。在当今的大规模数据中心里,单颗 AI 芯片的战力是微不足道的,真正的决胜点在于成千上万颗芯片组成的庞大集群协同。通过这种超低延迟的互联网络,Jalapeño 集群在进行多节点分布式推理时,实现了近乎无损的显存拉通。正如理查德·何在采访中所强调的,早期测试结果已经无可辩驳地证明,这枚“辣椒”的每瓦性能(Performance-per-Watt)将显著碾压当前市面上的所有最先进加速器。
1.3吉瓦算力矩阵与算力独立运动背后的资本博弈
Jalapeño 的问世,揭开的仅仅是 OpenAI 试图摆脱算力桎梏、构建独立硬件帝国的一角。博通首席执行官陈福阳在接受 Yahoo Finance 等媒体采访时,毫不掩饰其在这场算力革命中的庞大野心。他指出,这款芯片不仅将于今年晚些时候正式开始部署到微软(Microsoft)及其他核心云合作伙伴的大型数据中心,更直接抛出了一个足以让全球能源界震动的数字——预计到明年,OpenAI 和博通联合部署的芯片规模将突破 1.3 吉瓦(Gigawatts),并且下一代芯片已经在紧锣密鼓的规划中,预计 2028 年问世,此后将保持每年一代的疯狂迭代速度。
1.3 吉瓦是什么概念?这相当于一座大型商用核反应堆的全部物理输出功率,足以维持一个中等国家几座大型城市的日常运转。支撑如此恐怖的物理基建扩张,绝非单凭 OpenAI 账面上的现金流所能撬动,它牵出了隐藏在 AI 硬件狂潮背后更深层的资本博弈。尽管 OpenAI 对于具体的芯片采购资金来源三缄其口,但陈福阳却透露了一个关键的金融密码:博通已经与全球顶尖的私募股权巨头 Apollo Global Management(阿波罗全球管理公司)以及华尔街资本之王黑石集团(Blackstone)联手设立了专门的芯片融资工具。这意味着,OpenAI 的算力扩张已经彻底完成了与全球最庞大资本引擎的深度捆绑。
这种从底层技术到上层资本的全方位布局,标志着 OpenAI 在供应链战略上的彻底觉醒。在过去的长达数年里,OpenAI 在硬件层面几乎将命脉完全交给了英伟达的 GPU,并接受微软的巨额投资,以“资本换算力”的妥协姿态,租用由数万枚 NVIDIA 加速卡组成的专属集群进行模型的训练与托管。然而,随着 ChatGPT 等大模型在全球范围内的全面商用,日均数千亿次的 Token 推理请求,让算力消耗的天平彻底倒向了推理端。高昂的英伟达“算力税”正在疯狂吞噬 OpenAI 好不容易积累起来的软件利润。
为了打破这种被卖水人拿捏的宿命,OpenAI 在 2024 年至 2025 年间便开始了痛苦的多元化供应链平衡。他们不仅联合 AMD、英特尔甚至甲骨文(Oracle)去优化多芯片间的高速通信以压榨硬件极限,更时刻紧盯同样拥有自研 TPU 的谷歌以及深度绑定亚马逊定制芯片的 Anthropic。Jalapeño 的重磅降临,正是 OpenAI 在面临巨额运营成本与算力卡脖子的生死存亡之际,打出的一张试图重构全行业利润分配格局的终极底牌。这标志着这家 AI 霸主终于试图将算力成本的定价权,牢牢攥在了自己手中。
算力通缩下的分发黑洞:传统应用版图的史诗级撕裂
当整个半导体圈和华尔街都在为制程节点与百亿美元的融资规模欢呼时,对于广大的独立 App 开发者、互联网产品操盘手以及增长业务负责人而言,这场远在云端的大型硬件换代,带来的将是一场兵临城下的终端分发生态大地震。
当 OpenAI 凭借 Jalapeño 等定制芯片将最顶级的 AI 推理成本直线砍掉 50% 甚至更多,底层的算力将经历一场史无前例的“通货膨胀式贬值”。这意味着,原本受制于算力瓶颈与昂贵响应成本的“高智商复杂 Agent(智能体)自动执行”、“多模态跨应用深度穿透交互”等科幻技术,将以前所未有的极低门槛,全面、深度地接管智能手机、PC、穿戴设备甚至是刚刚试点的工业 5G 独立专网的底层操作系统。
随之而来的,是流量入口的急剧坍塌与调用链路的彻底“黑盒化”。在传统的数字世界里,流量的分发是高度结构化且线性的:用户产生明确需求——打开搜索引擎或应用商店——看到目标 App 曝光——点击下载并完成应用内转化。然而,在廉价算力支撑的纯血智能体时代,用户的底层需求(例如“帮我实时比对全网机票并自动预订明天去东京的最优航班”)将被超级 AI 助手的对话框在第一触点直接无情拦截。AI 智能体会化身为无形的网络幽灵,通过极速的 API 调度静默跨越各种操作系统的沙盒边界,去后台调用各个第三方的独立服务模块,并在 AI 自身的对话界面内完成所有流程的闭环呈现。
在这个算力深度协同、去中心化调度的分布式网络中,传统的“应用商店中心化曝光”的分发秩序正被彻底粉碎。缺乏不可替代核心价值与高频刚需的独立 App,将迅速沦为被彻底剥夺了前端展示权与品牌存在感的“无面目后端接口”。更让业务增长团队感到恐惧的,是随之而来的“归因失明”——面对系统后台激增的 API 调用或隐蔽的深度跳转请求,传统的买量追踪漏斗与归因面板将完全失效。你甚至无法分辨,这些海量涌入的瞬时流量究竟是来自某个云端推理节点的 AI 自然智能分发,还是来自底层链路中无关紧要的数据摩擦与错误爬虫调度。
穿透算力暗网:重铸全域链路基建死守业务生命线

面对 AI 算力基建大爆发所引发的流量极度碎化与底层链路的黑盒危机,如果继续抱守传统买量漏斗与生硬的漏斗转化逻辑,相关的团队必将在接下来的生态大洗牌中被迅速清退。唯一的生存之道,是极其果断地彻底打碎旧有 App 的封闭外壳,从底层代码级别重构自身的数据与链路流转基建,将原本厚重、封闭的端侧服务,化作能够自由穿梭于任何外部 AI 界面与超级 App 分发场景中的高维动态节点。
在极其复杂的算力协同与成千上万个智能体的高频调度网络中,去抢夺并承接住每一次真实的意图触达,必须依赖穿透力极强的底层流转体系。试想一下,当 AI 大模型生成的复杂回答或多 Agent 的推荐场景中,极度罕见地出现了指向你独立 App 的引流入口时,如果用户点击后还要经历“跳出-打开搜索-应用商店下载-重新寻找对应服务页面”的漫长断层体验,这种极其糟糕的转化摩擦力将导致流量在瞬间彻底流失殆尽。此时,开发者必须依靠 Open+ 等前沿的底层基建体系,将极其关键的业务逻辑与场景参数深度隐匿在最基础的 URL 层级之中。
通过毫无摩擦的场景还原技术,无论用户是在何种碎片化的外部环境、超级 App 生态矩阵或是极客式的 AI 聊天框中触发了链接点击,系统都能在毫秒级别实现底层意图的精准响应。对于那些已经安装了目标 App 的设备,系统能够瞬间无缝唤起并直接越过所有首页障碍,穿透至那个特定的深层服务页面;而对于大量尚未安装 App 的新设备,在引导其完成下载并首次打开应用的那一刻,底层架构同样能够凭借极致的传参安装能力,完美追溯并恢复点击前那一刻的场景记忆,彻底终结跨端流转中的任何转化流失。
与此同时,面对去中心化网络分发带来的数据追踪噩梦与防不胜防的虚假作弊风险,粗放的表面统计报表与单一渠道归因模型已然成为一堆废纸。建立一套能够穿透底层算力暗网的全渠道归因与多维数据监测体系,已成为鉴别真实流量价值与计算精确投资回报率(ROI)的核心武器。依托这套不可或缺的机制,开发者能够实时穿透底层数据的重重迷雾,精准看清每一次跨域点击、每一次后台静默拉起背后的真实转化来源,剥离掉那些毫无意义的无效冗余调用。在底层算力狂飙突进、硅谷大厂试图通过底层芯片与大语言模型彻底重构全球流量分发底层规则的存量搏杀时代,唯有用最轻盈、最顺滑且极具技术穿透力的技术基座去接稳并追踪每一滴珍贵的外部流量碎片,开发者才能在这场史无前例的生态剧变中,死死守住自己的业务生命线。
常见问题(FAQ)
OpenAI 为什么要放弃生态完善的通用 GPU,投入巨大精力研发定制化的 ASIC 芯片?
通用 GPU(如图形处理器)虽然算力强大且生态极为完善,但其内部包含了大量处理图形渲染、科学计算等 AI 大模型纯推理所根本不需要的冗余计算单元。随着大语言模型应用进入规模化爆发期,每天全球产生的数百亿次推理请求导致了极其恐怖的算力开销。研发专为 LLM 推理极限深度定制的 ASIC(专用集成电路)芯片 Jalapeño,能够彻底剔除这些冗余的硬件设计,大幅优化计算内核与高带宽内存之间的数据传输效率(即打破所谓的“内存墙”),从而将硬件的推理成本直接打断骨折(降低约 50%),这也是 AI 巨头试图摆脱供应商掣肘、实现商业可持续发展并重获行业定价权的必经之路。
Jalapeño 芯片能够在短短 9 个月内实现极速流片的核心原因究竟是什么?
在传统的半导体工业中,一款先进制程的商用芯片从画出架构草图到最终实现流片,通常需要耗费顶尖团队 1.5 到 2 年甚至更久的时间。OpenAI 能够将研发周期恐怖地压缩至 9 个月,是因为他们采用了“用先进 AI 制造 AI 芯片”的颠覆性工程范式。OpenAI 利用自家最前沿的 AI 大模型去辅助进行复杂的芯片架构探索、全局功耗仿真和基于强化学习的节点布线优化,极大幅度地缩短了人工工程师不断试错的漫长周期。同时,这一项目还叠加了博通在硅片实现与超低延迟网络通信(Tomahawk 架构)技术上的顶尖工业积累,最终创造了这一极其罕见的研发奇迹。
为什么 AI 底层硬件算力成本的断崖式下降,反而会对传统 App 开发者造成严重的生存危机?
当定制化推理芯片将 AI 的实际算力成本大幅降低后,高阶的 AI Agent(多模态智能体)功能将以极低的门槛全面普及到各类智能手机、PC 甚至物联网终端设备的底层系统中。这意味着,用户未来越来越多的长尾与核心需求,将被超级 AI 助手在对话框或语音界面内直接“吞噬”,并由智能体代为在后台调用第三方服务接口完成。用户将越来越少地主动去搜索、下载或打开传统的垂直独立 App,这会直接截断 App 与用户接触的“第一触点”,从而引发传统应用分发入口的全面枯竭和转化来源变得难以追踪的流量“黑盒化”生存危机。