OpenClaw 安装后必看,科学“养虾”下的自动化脚本如何影响拉新?
 openinstall运营团队|
openinstall运营团队| 2026-03-19|
2026-03-19| 328
328
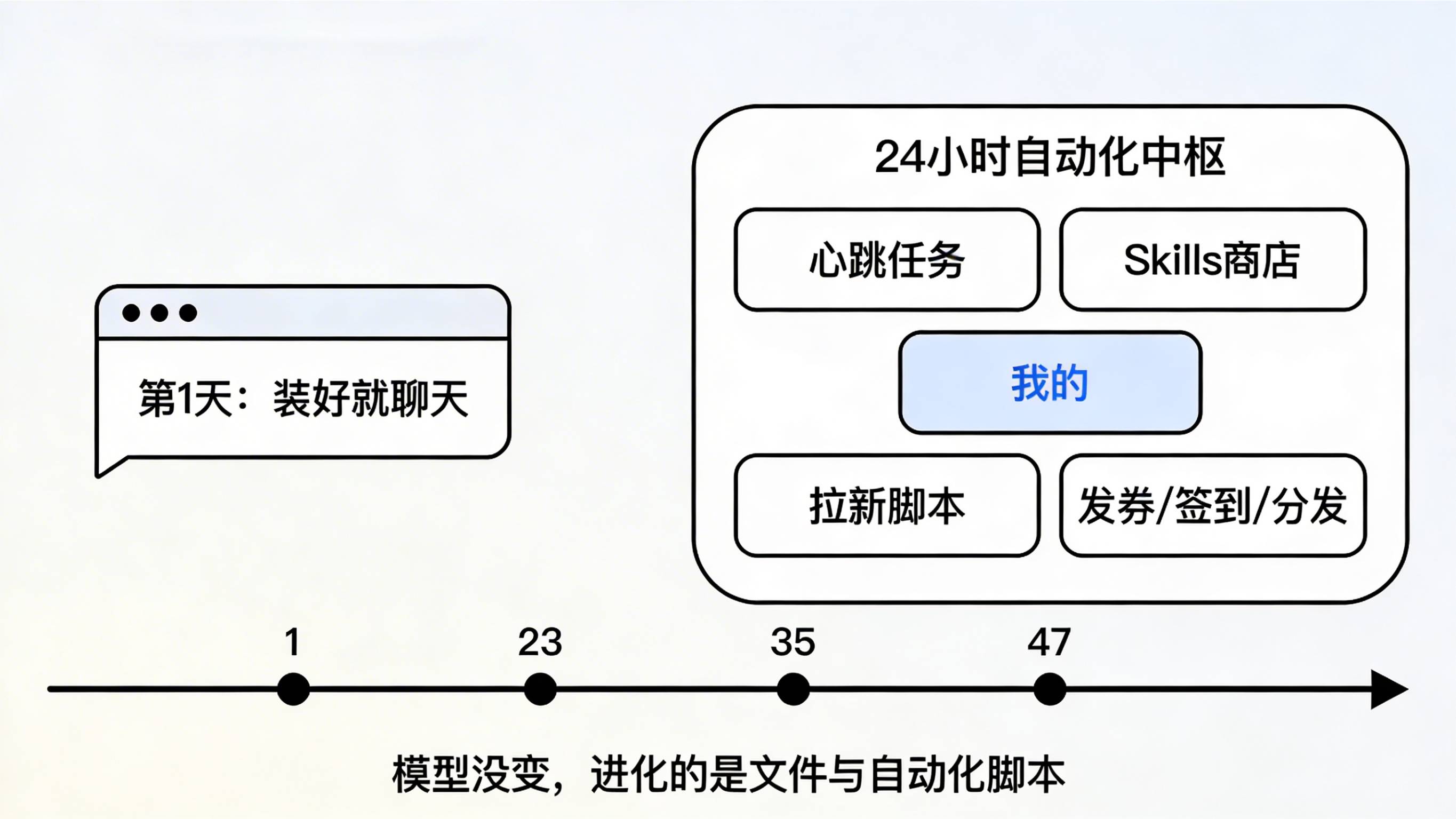
从“第 1 天装好就聊天”到“第 47 天靠心跳任务自动跑脚本、发公众号和小红书”,OpenClaw 已经从一个聊天窗口,演变成许多用户的 24 小时自动化中枢。关于 OpenClaw 的整体架构、网关能力与本地持久化记忆,可以参考这篇面向开发者的概览文章:。它可以在服务器或本机长期挂着,通过心跳任务和 Skills 去跑拉新、发券、签到和内容分发,一旦设计不当,就会直接扭曲 App 的拉新数据和归因结果。对开发和增长团队来说,“科学养虾”的关键,是把这类自动化脚本视为新的渠道入口,在架构层面重写安装归因与风控逻辑,而不只是“多了一个 AI 玩具”。
从新闻到用户路径的归因问题
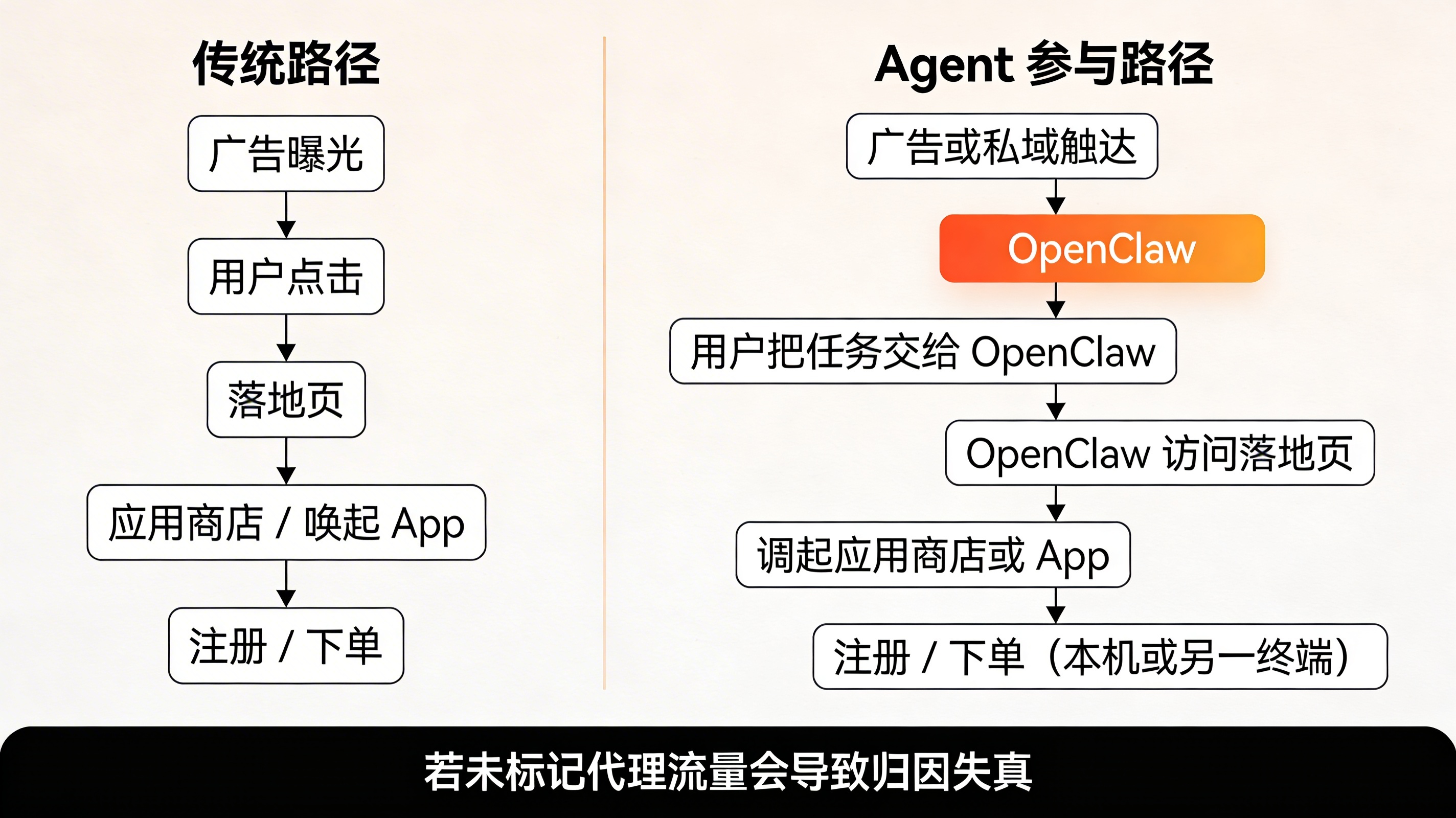
原始文章里,作者重装 OpenClaw 时回看了 47 天的使用差异:模型没有变强,用的还是同一个 qwen-3.5-plus,真正进化的是以 MEMORY.md、每日日志目录和 shared-context 组成的三级记忆体系,以及围绕心跳任务、Skills 商店搭出的各种自动化脚本。对一个 App 增长团队而言,这意味着:过去“人点链接—进落地页—跳到商店/拉起 App”的漏斗里,多了一层“Agent 先帮你点、先帮你执行”的隐形中间环节。
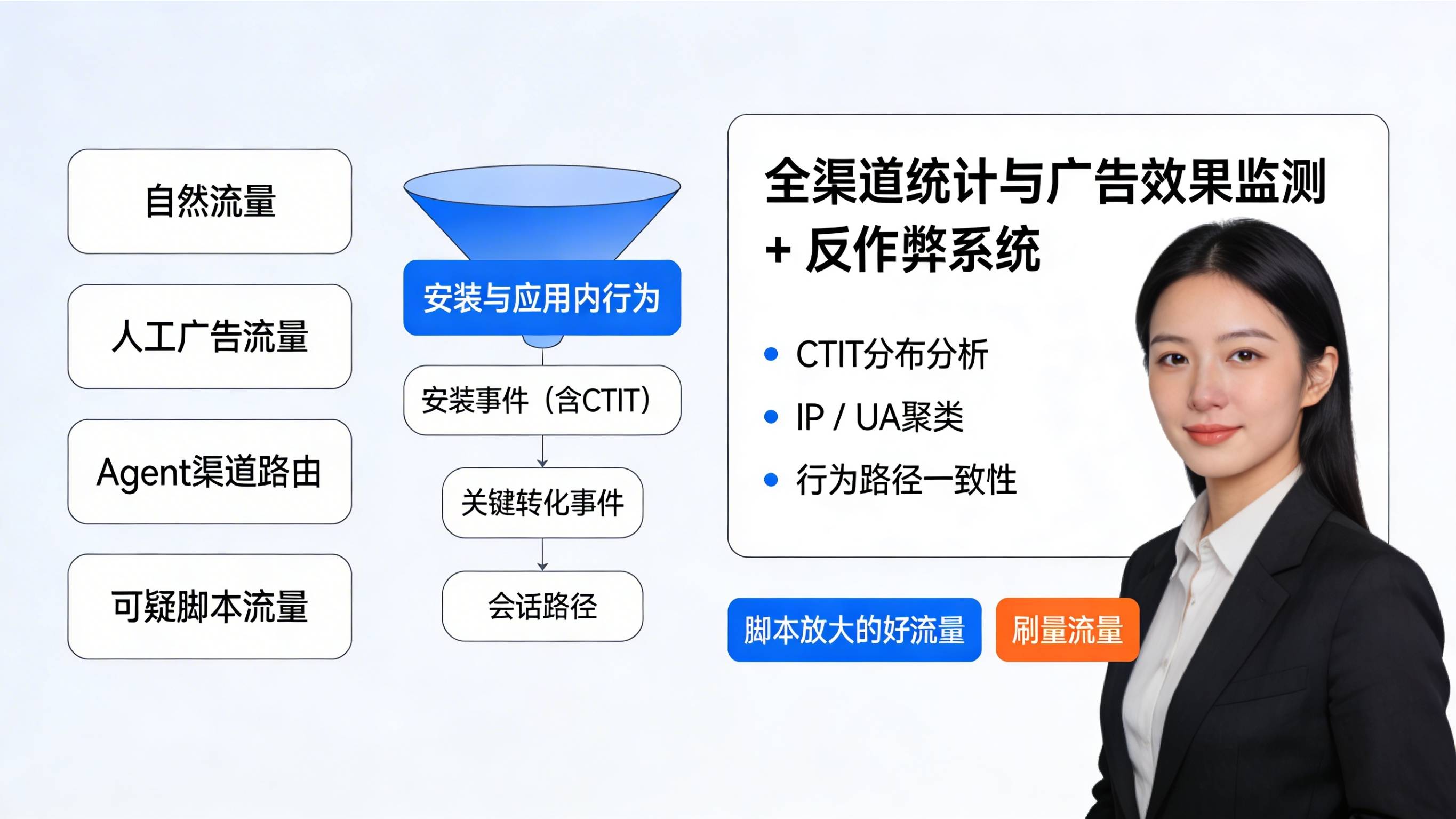
典型的“龙虾参与型”拉新路径,很可能变成:广告或私域触达 → 用户把任务丢给 OpenClaw → OpenClaw 在服务器上用浏览器或 HTTP 客户端访问落地页 → 调起应用商店或直接唤起 App → 在本机或另一终端完成注册、下单等关键行为。若这一段没有被明确定义为“Agent 流量”,又没有用传参与 DeepLink 固定住渠道信息,那么统计后台看到的只是“一些 CTIT 异常、IP 集中、机型或 UA 过于统一的安装”,很难和真实自然流量区分开来。
更进一步,当 OpenClaw 的记忆体系中写满了你的项目、常用活动页、后台账号,它在执行自动化任务时的“复利效应”会越来越强——可以同时改脚本、查数据、发群消息、投放广告。对运营效率来说这是巨大利好,但对归因和风控来说,如果没有专门的标识和分层,就等于把一个超强的“脚本放大器”直接插在了统计系统前面。此时简单依赖设备 ID 和渠道号,很容易把“自己养的虾”错判为外部作弊流量,或者反过来把真正的刷量掩盖在自动化噪声中。
工程实践:重构安装归因与全链路统计
把“龙虾流量”定义成独立渠道
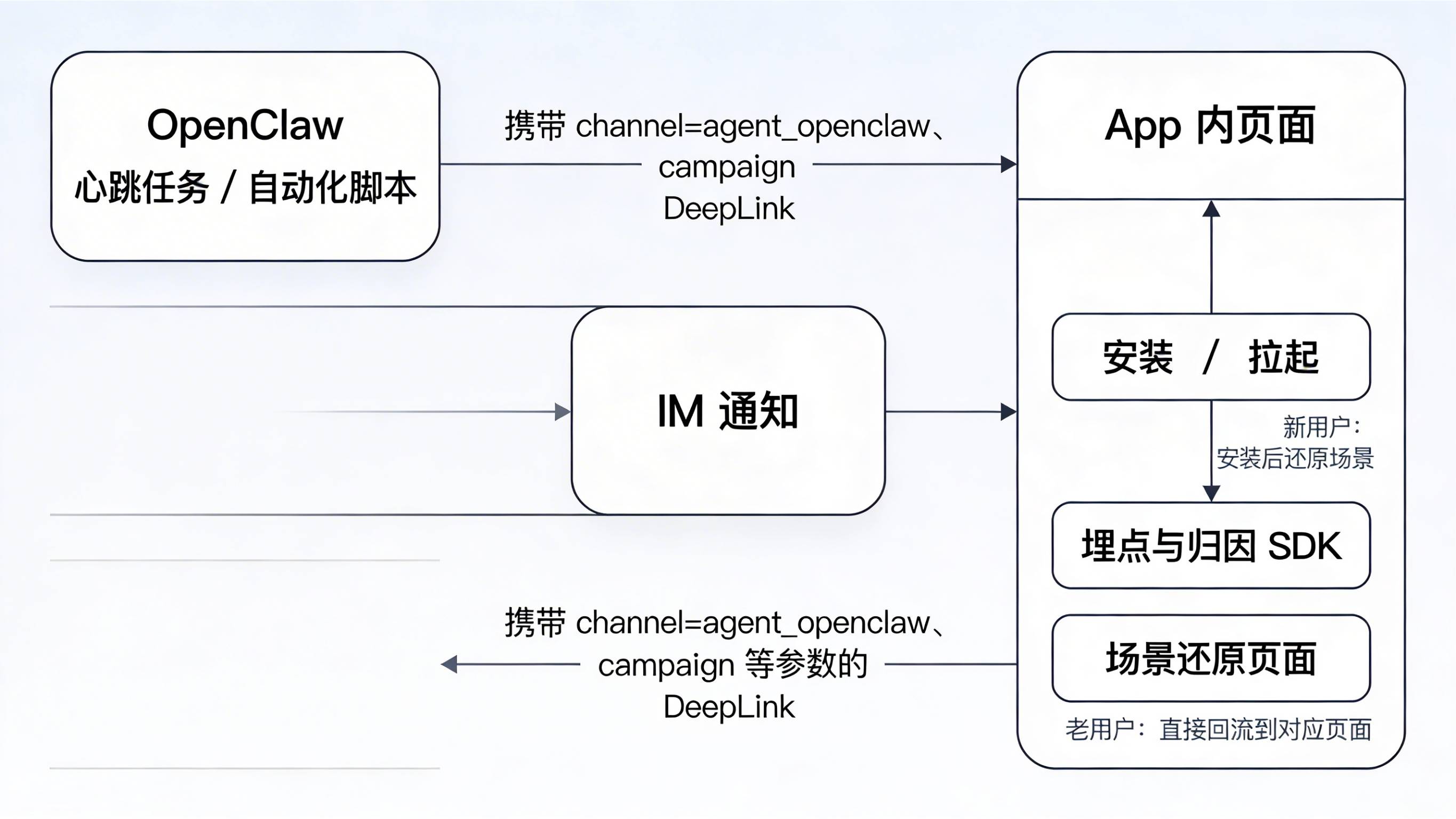
第一步,不要在数据层假装这类自动化不存在,而是要在渠道模型中显式增加“Agent / 脚本来源”这一维度。做法很简单:在所有通过 OpenClaw 执行的落地页链接上,统一加上特定的渠道参数(如 channel=agent_openclaw、campaign=heartbeat_signup),并通过 在安装时还原到具体活动与任务上。
这样做有三点直接好处:其一,安装报表里可以一眼看出“人手流量”和“Agent 代劳流量”的占比,不会把脚本带来的拉新误判为自然增长;其二,可以进一步在多维报表中对比 Agent 渠道的留存、付费、卸载表现,判断哪些自动化任务是真正有价值的;其三,一旦发现某类脚本行为和黑灰产刷量模式高度重叠,可以快速下掉对应活动或限制开放的任务类型,而不用牵连整体渠道。
用 DeepLink 接住跨端与心跳任务
文章中提到,作者最喜欢的一点是 OpenClaw 的心跳机制:完成自动化或复杂任务后,会通过飞书等 IM 把结果回推回来,并可以为每个心跳任务在 heartbeatworkspace 下建独立目录。类似“脚本完成 → IM 通知 → 用户再点开”的链路,如果最终目标是拉起 App,就非常适合用 DeepLink 来承接。
增长团队可以约定:所有由心跳任务推送的链接,都必须使用支持场景还原的 DeepLink,将活动 ID、用户 ID、任务 ID 等关键字段编码进去,并通过 保证从 IM 点击到 App 内页面的全过程参数不丢失。对于已经安装过的老用户,这能让你清楚知道某次“被龙虾提醒”带来的回流,到底对应的是哪一次任务执行、哪一个活动;对于未安装用户,也能在下载后自动还原到正确页面,同时将“Agent 渠道”写入归因维度。
{
"agents": {
"defaults": {
"contextPruning": {
"mode": "cache-ttl",
"ttl": "5m",
"hardClearRatio": 0.5
},
"reserveTokens": 20000
}
}
}
结合反作弊,识别“异常勤奋”的脚本流量
从安全视角看,开放式 Agent 框架已经被多家安全与合规团队点名为“企业看不见的新攻击面”,包括 OpenClaw 在内的高权限 Agent,被专门的安全清单和 CISO 指南反复强调要做资产盘点、最小权限控制和隔离部署,这类文章可以作为企业风控的基线参考:。对 App 来说,最现实的风险不是“所有 Agent 都是坏人”,而是:只要有一部分被黑灰产控制,就会产生极其规整、机械化的行为模式,并通过高权限接口放大。
在工程上,可以针对“龙虾型自动化流量”重点做三类特征交叉:一是 CTIT 分布,大量安装在极短时间内完成,或集中在少数固定时间窗口,且长期稳定复现;二是 IP / UA 聚类,来自少量 IP 段、代理机房或同构容器环境,User-Agent 单一;三是行为路径,在同一次会话内访问顺序高度一致、几乎不出现犹豫与回退。
这类模式一旦被识别出来,就可以在 中单独打标签,把“脚本放大的好流量”和“刷量流量”拉开:前者可以被视为“人机协同效应”,在预算和运营层面单独评估;后者则可以直接纳入拦截和限流规则,而不必因为“都是脚本”就全部拉黑。
这件事和开发 / 增长团队的关系
对开发与架构团队来说,OpenClaw 的三级记忆体系(MEMORY.md + 每日日志 + shared-context)和工作区结构(SOUL / USER / AGENTS / HEARTBEAT / skills 等)意味着:需要在服务端预留一整套“Agent 友好”的接口层,包括安全的回调签名、幂等控制、限流和审计日志。否则一旦 Agent 获得过高权限,就很难在事后追责和止损,而这些接口一旦对外暴露,又很容易成为黑灰产脚本的攻击入口。
workspace/
SOUL.md # 智能体人格与原则
IDENTITY.md # 外部身份/名片
USER.md # 关于用户的信息
AGENTS.md # 工作区级协作与安全规则
MEMORY.md # 长期记忆与“血泪教训”
HEARTBEAT.md # 心跳任务清单
Key.md # 密钥与访问凭证
shared-context/ # 跨智能体共享上下文
heartbeatworkspace/ # 心跳专区
juejin-checkin/ # 掘金签到任务
security-audit/ # 安全审计任务
memory/
2026-03-16.md # 当日日志
2026-03-15.md # 前一日日志
skills/
weather/ # 天气等技能
github/ # GitHub 相关技能
同时,所有与拉新、登录、分发强相关的接口都应在协议层设计好渠道字段、设备标识与会话 ID,确保 Agent 参与的请求能够被完整还原和溯源。比如:把“是否由 Agent 触发”“对应的 Agent 标识”“所在的任务名称或心跳 ID”写入日志,再在数据仓库中和安装回传、应用内事件打通,用统一的用户 ID 和设备 ID 做纵向串联。
对产品、增长与运营团队而言,更重要的是重新定义“任务”本身:哪些拉新和促活任务适合交给 OpenClaw 这类 Agent 去跑(如定时推送、日报生成、活动状态巡检),哪些则必须保持“人先触达—Agent 辅助执行”的模式(如需要强主观判断的内容运营或高风险资金操作)。每增加一类自动化场景,都要在渠道归因模型里增加一条可被统计的路径,并提前和反作弊、法务对齐合规边界,避免出现“从平台视角看是一堆异常脚本,从业务视角却是理所当然的拉新任务”的割裂。
常见问题(FAQ)
自动化脚本带来的拉新流量要不要一刀切掉?
不需要也不应该一刀切,因为很多高价值任务(例如自动生成 A/B 实验落地页、按心跳检查活动页可用性、定时推送老用户召回链接)本身就是在提升运营效率。关键在于:在链接与统计层明确“Agent 渠道”标识,通过 CTIT、IP、行为路径等维度识别刷量模式,把问题限定在异常流量上,而不是把所有自动化一股脑封杀。
如何区分“高价值自动化”和“作弊脚本”?
一个实用的经验是先看“是否可追责”:高价值自动化通常是由内部团队配置,有清晰的职责人、变更记录和可读的 OpenClaw 配置文件;而作弊脚本往往来源不明、运行环境分散,甚至绕过了正式配置途径直接触达接口。在此基础上,再用渠道参数、设备画像与行为特征,结合你自己的全渠道统计报表做增量分析,就能较清晰地划出“可优化利用的自动化流量”和“需要封禁的异常脚本流量”边界。
如果第三方合作伙伴自己在用 OpenClaw 拉量,我要提出什么要求?
最关键的,是把“自动化行为”提前写进合作条款里:要求对方为所有由 Agent 发起的请求打上固定渠道标记,并对其 OpenClaw 工作区中的关键配置(如心跳任务、Skills 列表、访问频率)提供只读审计说明,方便你在发现异常时快速比对。与此同时,可以约定一套基础的风控红线,例如禁止通过 Agent 直接调用高风险资金接口、禁止在未实名的服务器上长期开启高权限技能,必要时参考行业内关于 OpenClaw 风险的实践指南,定期更新你自己的黑名单和告警规则。
行业动态观察
从更大的行业视角看,OpenClaw 已经不再只是一个“会聊天的本地助手”,而是被视为 Agentic AI 方向的代表性开源项目:它通过本地运行、工具注册和文件型记忆系统,把“自动化工作流 + 高权限执行”推到了普通开发者和中小团队面前,也因此被越来越多的文章拿来和传统 ChatGPT 式聊天机器人做对比。围绕 OpenClaw 的教程、经验分享和工具链,正在快速形成一个以 Skills 和本地自动化为核心的新生态。
与此同时,安全社区也在不断提醒:这类高权限、长时间在线的 Agent 实例,已经成为企业和开发者新的安全盲区,相关安全厂商和安全团队给出了详细的排查与防护建议,例如针对 OpenClaw 的安全核查与 CISO 行动清单。