自托管AI网关与OpenClaw远程访问,归因回调安全边界
 openinstall运营团队|
openinstall运营团队| 2026-03-19|
2026-03-19| 262
262
最近一篇《自托管AI网关的正确姿势:OpenClaw远程访问与安全配置》的技术文章,把“Gateway 才是 OpenClaw 真正核心”“Gateway 默认绑定 127.0.0.1:18789,只通过 SSH/Tailscale 暴露”的实践细节讲得很透:一台永远在线的服务器上挂着 Gateway,通过微信、Telegram、Discord 等多渠道远程访问多个 Agent,相当于给自己配了一支 7×24 小时的“数字员工”队伍。与此同时,慢雾安全团队和微软安全博客都在提醒:这类自托管 Agent 一旦接近生产系统,就必须被当成“不可信但有长期凭证的执行环境”,否则一次配置疏忽就可能让归因回调接口、渠道报表乃至整个增长数据面暴露在高风险之下,更完整的防护清单可以参考慢雾团队的《》。对 App 团队来说,问题已经不是“要不要用 OpenClaw”,而是“在用它前,先把哪些安全边界划清楚,尤其是涉及归因回调这条线”。
从新闻到用户路径的归因问题
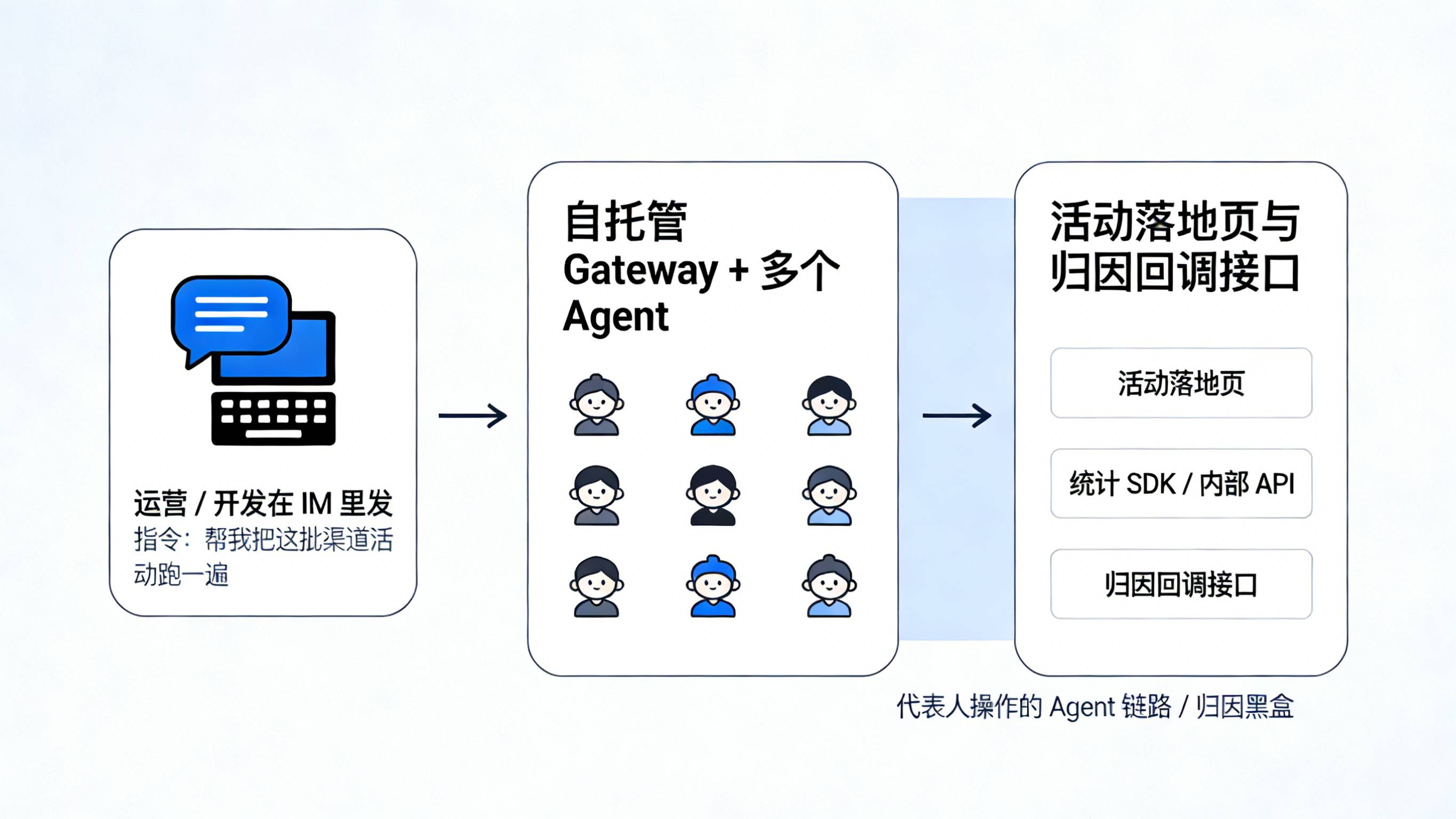
把这篇 Gateway 实战文章还原到一个典型业务场景,会发现一条很常见、但过去被严重低估的用户路径:运营或开发在 IM 里一句“帮我把这批渠道活动跑一遍”,OpenClaw 通过网关接到任务,在服务器上批量访问活动落地页、请求统计 SDK 或内部 API,最后再把结果通过飞书/微信发回人手上。表面上看,这只是在“替人点点链接、跑跑报表”,但对归因体系来说,多了一整段“Agent 代表人操作”的黑盒链路。
如果网关所在的服务器和生产环境在同一内网段,甚至能直连归因回调接口,那么用户真实路径就可能变成:广告点击或社群触达 → 用户把链接丢给 OpenClaw → OpenClaw 在服务器上访问落地页并触发下载/拉起 → 服务器再去请求归因回调或内部统计接口 → 最终在后台看到“安装/激活/首单”被记在某个渠道下面。这里最危险的点有两个:一是“看起来来自真实设备/正常 IP 的请求,其实是脚本或 Agent 执行”;二是“Agent 同时握着运营后台账号、API Key 和脚本权限”,一旦被误用或攻陷,就能以极高效率放大错误配置和恶意行为。
如果不在模型里明确区分“人手流量”和“Agent 流量”,不在日志里标记“由哪个 Agent/任务触发”,一旦出现归因异常(例如某渠道安装暴涨、CTIT 异常集中、回调量明显大于有效设备量),团队几乎很难第一时间判断:到底是黑产在刷,还是自家部署的 OpenClaw 在“帮倒忙”。归因回调这条线,本质上需要在“业务自动化的效率”与“数据可信度和安全性”之间重新画一条边界。
工程实践:重构安装归因与全链路统计
把自托管网关视为独立渠道源头
第一步是承认现实:一旦你把 Gateway 部署在 VPS 或办公室服务器上,并通过多渠道远程访问,它就已经是一个独立的“流量源”。因此,应该在渠道模型里显式把它建成“自托管网关 / Agent 渠道”,而不是把它混在自然流量或广告流量里。
具体做法上,可以约定:所有通过 OpenClaw 触发的落地页访问与下载/拉起,都统一带上明确的来源参数,例如 channel=agent_gateway、agent_id=coding 或 writer、task_id=xxx,并在安装和首次打开时,通过 将这些参数完整写入归因维度。这样一来,报表上就能直接看到:哪些安装是由人手触发,哪些是由 Agent 触发;后续在 页面上,也能单独观察“Agent 渠道”的留存、付费和卸载指标,避免把自动化带来的“自转”误判为市场真增长。

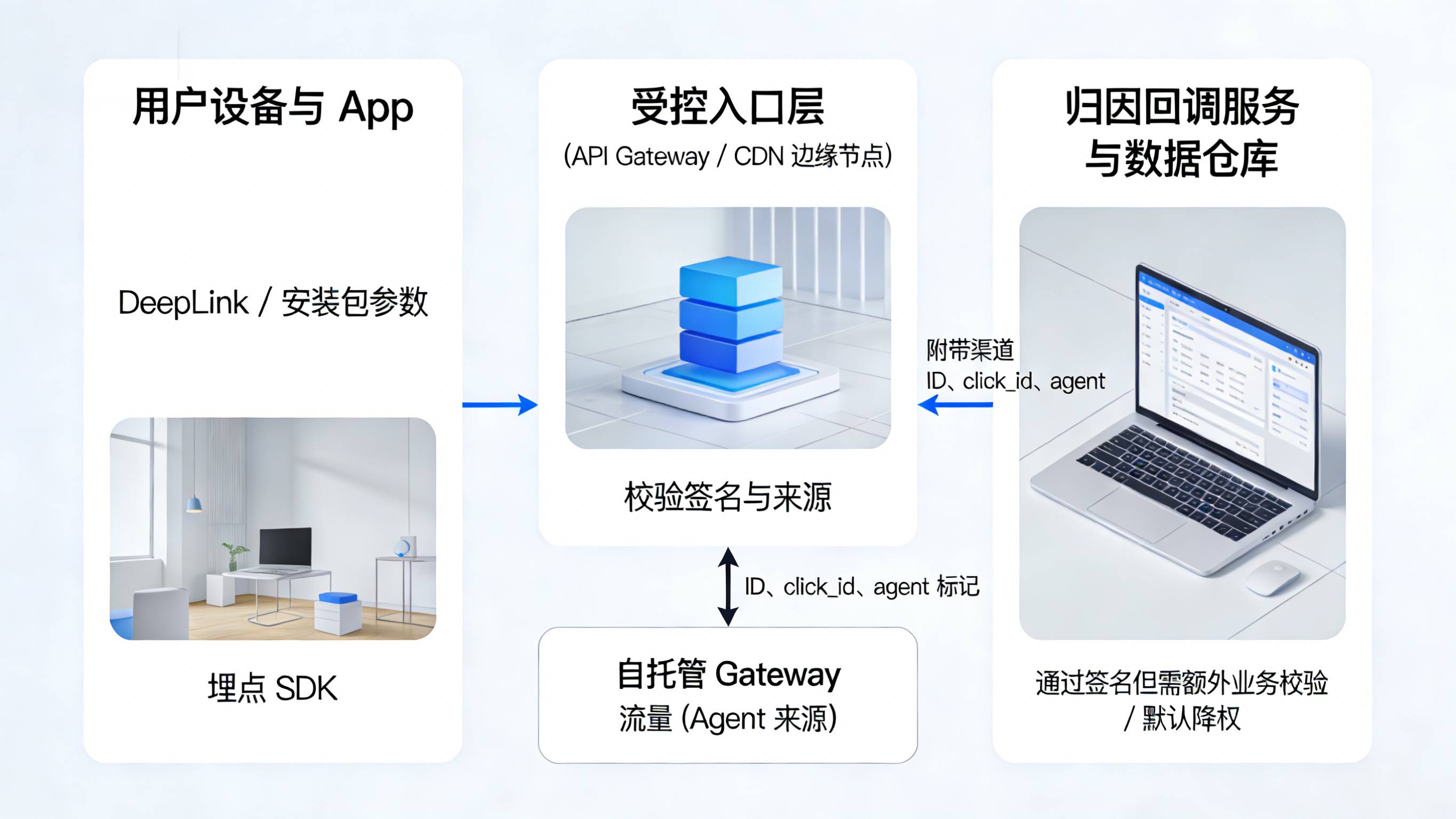
用“前端参数 + 服务端签名”保护归因回调接口
第二步,是在归因回调接口本身加一层“只信任正确入口”的安全网。很多团队把归因回调做成一个简单的 HTTP 端点,只要带上 app_id、device_id、click_id 就能记一次安装或激活,这在有 OpenClaw 这种高权限 Agent 存在的环境里风险极高。
更稳妥的做法是:
-
前端仍然通过 DeepLink 或安装包参数,把渠道 ID、click_id、agent 标记等透传下来,依赖 保证参数不丢失;
-
服务端回调接口增加签名校验,例如基于 app_secret 的 HMAC 或短期有效的签名 token,只允许来自受控网关(如 API Gateway、CDN 边缘节点)的请求进入真实归因逻辑;
-
对来自自托管网关所在 IP 段的请求,单独打上“Agent 来源”标签,即便签名通过,也要求额外的业务侧校验(例如必须有对应的真实设备行为、必须在合理时间窗口内等),否则默认降权或只计入“辅助贡献”。
在这种设计下,即便有工程师误把 OpenClaw 部署在和生产同一网络中,它也只能以“受限身份”访问归因回调,而不能像一个全功能脚本那样随意增删安装记录。对外,所有真实写入归因结果的行为,仍然集中在一小撮受控服务上,方便风控与安全团队做审计。
{
"gateway": {
"bind": "127.0.0.1",
"port": 18789,
"auth": {
"mode": "token",
"token": "your-strong-random-token"
}
},
"agents": {
"list": [
{
"id": "coding",
"workspace": "/home/app/.openclaw/workspace-coding",
"meta": {
"channel": "agent_gateway",
"role": "dev-tools"
}
},
{
"id": "growth",
"workspace": "/home/app/.openclaw/workspace-growth",
"meta": {
"channel": "agent_gateway",
"role": "growth-ops"
}
}
]
}
}
利用全渠道统计与风控指标监控网关流量
第三步,是在数据面持续“看得见”网关行为。自托管网关的一个特点是:一旦部署成功,它会长期在线,而且可以承接越来越多的自动化任务——自动生成活动页、自动执行拉新脚本、自动跑日报等等。
在统计和风控层面,建议至少做三类监控:
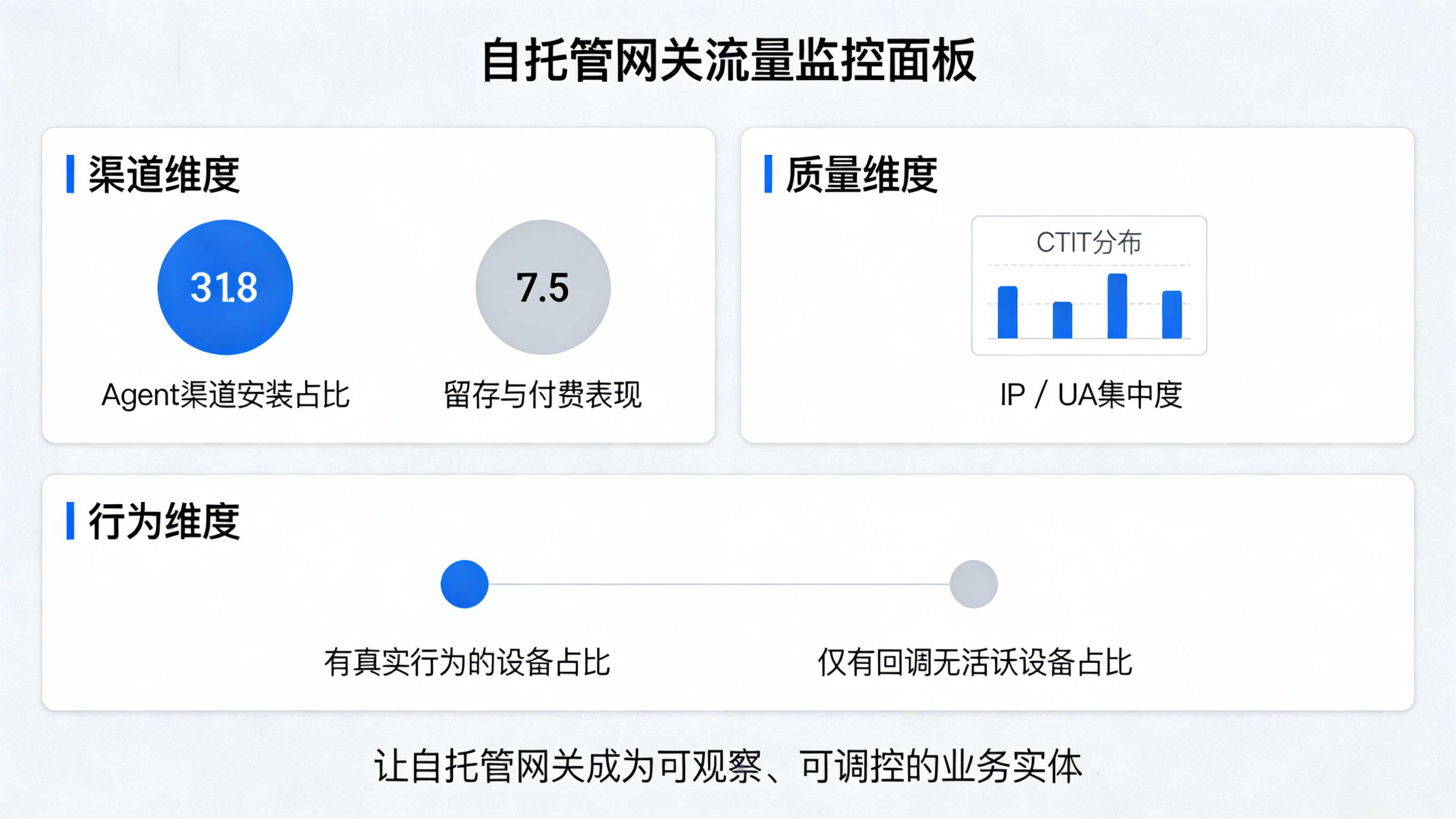
-
在渠道维度上,持续跟踪“Agent 渠道”的安装量、激活率、付费率与留存,避免其占比异常上升;
-
在质量维度上,对 Agent 渠道的安装做 CTIT 分布、IP 分布、设备指纹多样性分析,一旦出现集中度异常(过多同 IP、同 UA 或极短 CTIT),立即拉高风控等级;
-
在行为维度上,对“由 Agent 触发的回调”与“同一用户/设备在 App 内的真实行为”做对比,如果大量回调对应的是“无活跃、无事件”的冷设备,则应当视为可疑并进入反作弊规则。
这些指标都可以落到 中,让“自托管网关”成为一个可观察、可调控的业务实体,而不是藏在内部脚本里的“幽灵渠道”。
{
"app_id": "com.example.app",
"device_id": "d_1234567890",
"click_id": "clk_abc123",
"channel": "agent_gateway",
"agent_id": "growth",
"event": "install",
"timestamp": 1742366400,
"signature": "b5fd0ef2b0c0c6f9b1b3c1a6e8d4c9aa"
}
这件事和开发 / 增长团队的关系
对后端与架构团队来说,自托管 AI 网关的最大挑战在于:它把“会跑脚本的人”变成了“随时可以改脚本的 Agent”,而 Agent 默认是 7×24 在线的。这意味着在设计归因回调与内部统计 API 时,要把 OpenClaw 这类 Agent 当成“半外部调用者”来处理:接口要有严格的鉴权(签名、IP 白名单、限流)、最小权限(只给到必要字段和动作)、清晰审计(每次调用都能溯源到具体 Agent 和任务)。
对产品、增长与运营团队来说,需要更新的则是“任务设计观念”:不是所有拉新、促活动作都适合交给 OpenClaw 来跑。适合自动化的是那些“有清晰输入输出、可被标记为 Agent 渠道、且业务风险可控”的任务,例如自动生成某渠道日报、自动巡检活动页健康、自动生成落地页 AB 版本等;而真正写入用户状态、改动核心账务或涉及敏感个人数据的任务,则应继续由受控后台和人工流程来承接,把 OpenClaw 的角色限定为“建议和辅助执行”,而不是让它直接触达归因和结算核心。
常见问题(FAQ)
自托管网关是不是最好彻底隔离出生产网络?
在理想方案里,是的:把部署 OpenClaw 的机器放在隔离网络,只允许它访问公开的落地页和中间层 API,不直接接触生产数据库和内部归因回调,会大幅降低风险。但在很多中小团队里,物理隔离未必现实,这时就要用“逻辑隔离”的方式:通过 API Gateway、签名校验、角色权限控制,把它能做的事情限定在一个明确、可审计的范围内。
用 OpenClaw 去访问第三方广告平台或商店后台,会不会影响官方归因?
如果只是读取报表或通过官方 API 拉数据,本身对官方归因逻辑没有破坏性;但一旦用它去模拟用户点击、触发测试安装或批量拉起 App,就很容易干扰官方的点击–安装–打开链路,尤其是在 iOS SKAN、ASA 等强约束的生态里。实际接入时,建议把“归因实验脚本”和“生产环境运营行为”分开:前者在沙盒账号和测试 App 上跑,后者在生产账号上尽量少用自动化操作,避免给官方归因系统制造额外噪音。
如何向业务侧解释“Agent 渠道”的存在,不被误解为“刷量”?
关键是透明:一方面,在渠道规划和投放会中,把“Agent 渠道”当成一个正常渠道来列入规划——它的作用是自动化执行运营和测试任务,而不是用来堆 KPI;另一方面,在报表和结算口径上,明确把 Agent 渠道的数据剥离出“真实用户拉新”口径,只在内部效率评估和技术实验中使用。这样既能让业务侧看到自动化带来的效率,又不会在对外或对高层的增长数字中“掺水”。
行业动态观察
从行业趋势看,自托管 AI 网关 + OpenClaw 远程访问,已经逐渐成为技术团队尝试“数字员工化”的主流组合:一台云主机或办公室服务器上跑 Gateway,通过 Tailscale 或 SSH 隧道暴露到内网,再挂上微信、Telegram、Discord、企业 IM 等渠道,当作“全员共享的 AI 中控”。在这种架构下,App 拉新和留存相关的很多动作(拉取活动配置、生成投放文案、跑数据脚本)都容易被“顺手接”到 OpenClaw 上。
与此同时,安全社区和大厂安全团队已经开始把 OpenClaw 类的 Agent 作为独立风险源来对待:慢雾提出了围绕 OpenClaw 的 Agent 零信任实践指南,微软则在《