全模态大模型Qwen3.5-Omni:跨端并发,归因断层如何破局?
 openinstall运营团队|
openinstall运营团队| 2026-04-01|
2026-04-01| 264
264
3月30日,阿里云正式发布新一代原生全模态大模型 Qwen3.5-Omni,以斩获 215 项 SOTA(性能最佳)的成绩全面超越 Gemini-3.1 Pro,并将 API 调用成本打到了令人咋舌的每百万 Tokens 不足 0.8 元。当大模型从单一的文本对话,彻底跃迁为能听、能看、能随时被打断、甚至能通过“动嘴”直接生成代码的超级智能体,应用的交互入口正在被系统级的多模态 Agent 强力重构。面对这种结构性的生态变迁,App 开发与增长团队必须直面一个核心命题:当用户的意图由全模态大模型在多终端跨屏发起,如何精准追踪并归因这些全新涌现的“任务流量”?
新闻与环境拆解
在 2026 年初这场大模型迭代竞速中,Qwen3.5-Omni 不仅是一次参数规模的升级,更是底层架构与多模态感知能力的一次质变。它彻底打破了传统“视觉模型+语言模型+语音模型”的拼接式桎梏,实现了真正的端到端全模态原生。
215项SOTA与“Audio-Visual Vibe Coding”的涌现
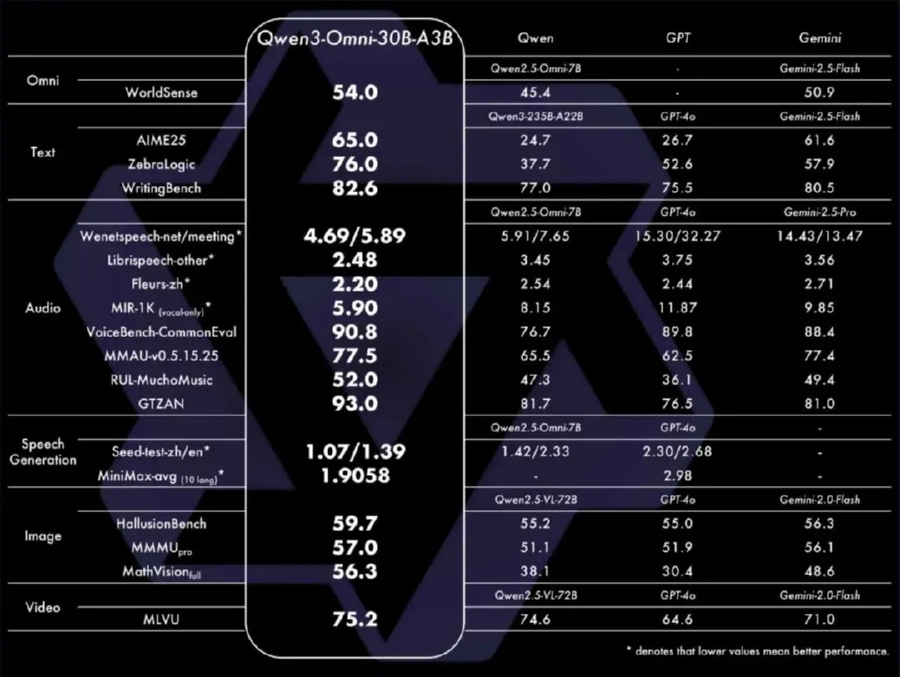
根据官方披露的数据,Qwen3.5-Omni 在海量文本、视觉素材以及超过 1 亿小时的音视频数据上进行了预训练。在离线能力测试中,其 Plus 版本在音频及音视频理解、推理和交互等任务上豪取 215 项子任务 SOTA。通用音频理解、多语种翻译及对话能力全面超越谷歌的 Gemini-3.1 Pro。 更令开发者震撼的是,通过原生多模态 Scaling 扩展,该模型自然涌现出了“Audio-Visual Vibe Coding”能力。用户无需敲击键盘,只需打开摄像头,对着草图或现实场景口述复杂的产品逻辑,模型就能直接输出带有复杂 UI 的 App 原型界面或网页代码。这种从“感知理解”到“执行落地”的能力跨越,意味着大模型已具备极强的工程级转化能力。
核心架构:Hybrid-Attention MoE与Thinker-Talker协同
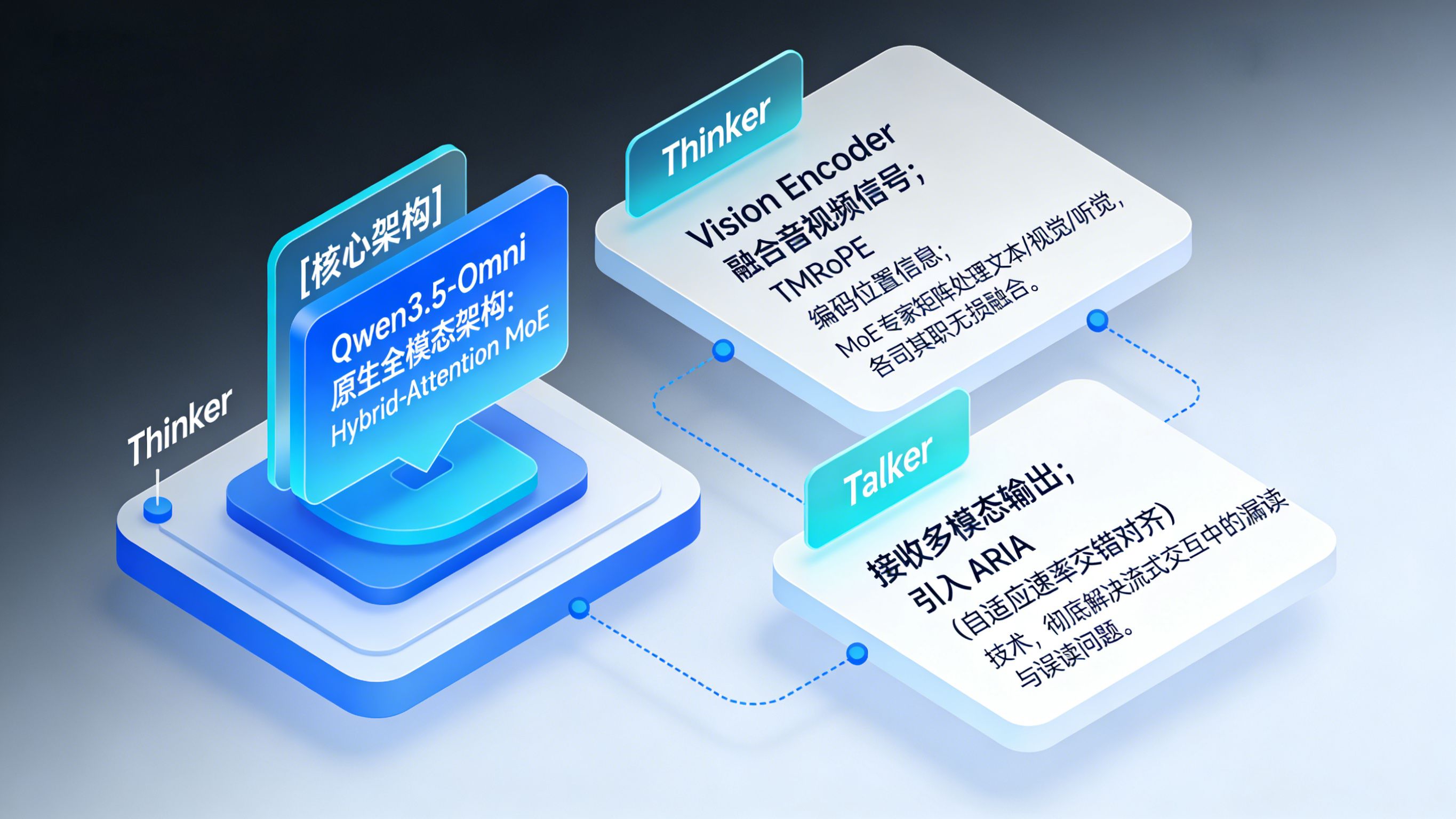
Qwen3.5-Omni 延续并大幅升级了上一代的 Thinker-Talker 分工架构,两者均采用了 Hybrid-Attention MoE(混合注意力混合专家)架构。 Thinker 模块负责“理解”,它通过 Vision Encoder 接收视觉信号,并融合音频信号,利用 TMRoPE 编码位置信息。MoE 架构的引入使得处理文本、视觉、听觉的“专家神经网络”各司其职,互不干扰,从而在实现多模态融合的同时,依然保持了和单模态模型一样强悍的性能。 Talker 模块负责“表达”,它接收 Thinker 的多模态输出,进行 Contextual 语音生成。新版本放弃了繁重的 DiT 运算,改用 RVQ 进行编码。最核心的突破在于引入了全新的 ARIA 技术(自适应速率交错对齐),彻底解决了流式语音交互中因文本与语音 Token 编码效率差异导致的漏读、误读问题。
10小时超长音频解析与113种语言支持
在长上下文处理能力上,Qwen3.5-Omni-Plus 支持高达 256K 的长上下文,能够一次性吃下超过 10 小时的音频输入或 400 秒的 720P 视频。它支持 113 种语种和方言的语音识别(包括极小众的毛利语和海南方言),以及 36 种语种的语音生成。这种超长时序内容的结构化解析能力,使其能自动完成视频切片、时间戳打标及人物关系梳理,将原本繁琐的音视频后期梳理工作缩短至秒级。
实时交互进化:语义打断与复杂Function Call
在实时交互体验上,Qwen3.5-Omni 支持语义级别的智能打断,能准确区分用户的无效背景音(如随口附和)与真实的 Talk-taking 意图;支持端到端语音控制,可根据指令自由调节音量、语速和情绪;原生支持 WebSearch 与复杂的 Function Call(函数调用)。当模型被赋予强大的工具调用能力后,它就不再只是个聊天框,而是能自主决定是否联网搜索、是否调取第三方 API 扣费的“行动派”。配合低至 0.8 元/百万 Tokens 的极寒定价,全模态 Agent 的大爆发已是箭在弦上。
从新闻到用户路径的归因问题
Qwen3.5-Omni 展现出的全模态原生与复杂工具调用能力,标志着数字生态正在发生底层逻辑的迁徙。当用户开始习惯用摄像头扫一扫、用嘴巴说一说来下达指令,App 获取新用户的真实链路也在变得面目全非。我们需要深刻区分两类截然不同的流量形态:

第一类是传统手机屏幕内的“主动页面流量”:用户看到广告素材,点击落地页,跳转至应用商店下载,最后打开 App。这套链路尽管存在跳转损耗,但依然是基于屏幕点击的强因果关系。 第二类则是由 Qwen3.5-Omni 等全模态 Agent 伴随多模态场景自动触发的“意图/任务流量”:例如,用户戴着搭载该模型的智能眼镜,指着路边的一家新开餐厅说“帮我拿个号排队”。智能眼镜内的 Agent 经过音视频理解与 Function Call,在后台通过 API 或静默下载调起某个本地生活 App 并自动排号。
在这种多终端并发、跨越物理与数字边界的场景下,App 开发与增长团队面临着致命的归因断层。任务是谁发起的?是智能眼镜、车机,还是桌面端的自动化脚本?意图参数(如餐厅的特定门店 ID、用户的实时位置特征)在跨越硬件设备底层、进入应用商店中转时,不可避免地会被操作系统抹除。App 的后台只能看到激增的下载量或接口请求,却像一个“黑盒”,完全不知道这批高价值的转化来源于哪个具体的硬件终端、哪一次特定的语音交互指令。归因链路的断裂,将导致多模态 AI 时代的渠道评估失效,企业无法衡量不同智能硬件和 Agent 生态的导流 ROI。
工程实践:重构安装归因与全链路统计
为了接住全模态大模型带来的海量“任务分发”红利,避免 App 沦为底层且盲目的“服务管道”,研发团队必须在工程链路上进行底层升级,用标准化的技术手段锚定跨模态并发下的每一次系统调用。
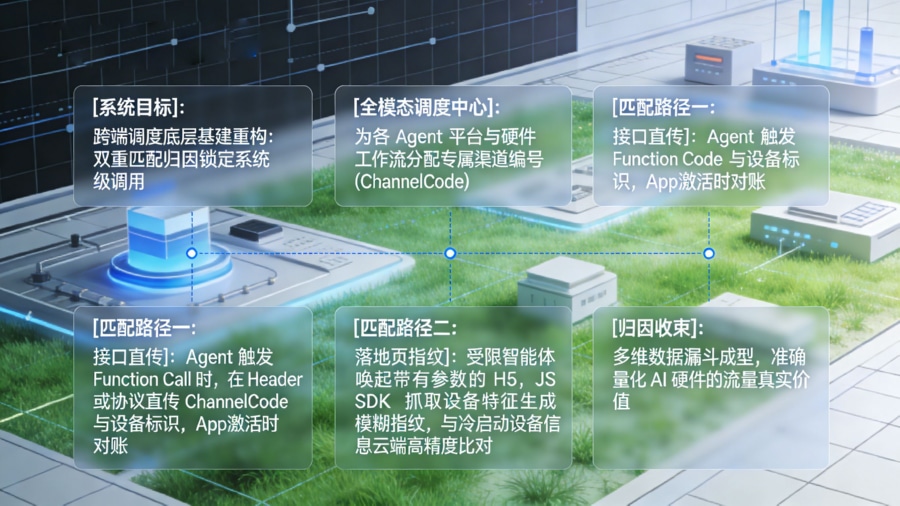
统一多模态入口标识与双重匹配归因机制
-
问题:来自智能音箱、AI 眼镜、车机端大模型及各类自动化工作流的调度指令碎片化严重,传统的依靠单一 H5 页面 User-Agent 的追踪方式彻底失效,流量来源难以在同一套数据池中对账。
-
做法:为各大全模态 Agent 平台及硬件工作流分配专属的渠道编号(ChannelCode)。在借助专业的 平台进行底层基建重构时,需要建立两种并行的标准匹配路径: 一是接口直传匹配:对于深度集成的 AI 硬件或大模型平台,要求 Agent 在触发 Function Call 时,直接在 Header 或底层协议中返回 ChannelCode 及设备标识等传参信息,等 App 激活时直接与这些硬参数进行对账归因。 二是落地页匹配:若智能体的能力受限,只能通过唤起带有参数的 H5 落地页作为跳转中转,则由落地页的 JS SDK 直接获取当前智能终端的设备特征与业务参数,生成模糊指纹,再与用户后续打开 App 时的设备信息进行云端高精度匹配。
-
好处:将无形且散落在多终端的“意图流量”进行显性化收束。无论是哪种模态引发的下载与激活,都能形成从调度、拉起到业务转化的多维数据漏斗,帮助企业准确量化不同 AI 终端的流量真实价值。
智能传参安装,打通跨端硬件的意图断层
-
问题:当全模态模型(如 Qwen3.5-Omni)通过视觉识别判定需要下载某款垂类 App 来承接特定服务时,关键的视觉上下文参数(如特定商品的 ID、某个长视频的时间戳)往往在应用商店下载环节全部丢失。用户打开新安装的 App,面对的是冰冷的默认首页,多模态交互的沉浸感瞬间破灭。
-
做法:采用成熟的 方案。基于双重匹配机制获取到的底层参数,当大模型发起带有强烈业务意图的下载请求时,系统在云端将这些参数(如
target_item_id、vision_context_id)与当前 AI 终端的设备快照进行强绑定;待 App 完成下载并首次冷启动时,SDK 会立即向云端发起请求,自动还原并下发这些多模态参数。

-
好处:实现了跨下载链路与跨硬件壁垒的“场景还原”。新用户打开 App 瞬间就能直接承接 AI 刚刚“看到”或“听到”的任务流程,跳过繁琐的搜索步骤,极大地降低了任务流失率。
强化深度链接的系统级响应与高可用拉起
-
问题:对于已经安装了 App 的设备,系统级的全模态 Agent 需要高频、低延迟地唤起应用的极深层级页面以执行细粒度动作。而在不同厂商定制的 Android OS 或闭环的 iOS 中,传统的 URL Scheme 唤起经常遭遇底层拦截、白名单限制或唤起报错。
-
做法:全面梳理并优化 Universal Links 及 App Links 的底层配置文件(如
apple-app-site-association),并利用标准化的深度链接 (DeepLink) 路由分发技术,确保 App 能够 100% 响应并解析来自任何外部大模型的系统级意图调度。 -
好处:让 App 彻底摆脱前端展示的局限,蜕变为一个高可用、可信赖的“AI 节点服务”。保障任务流量在全模态并发环境下的流转顺畅,避免跳转失败导致的大模型执行报错。
前瞻性延展声明:需要注意的是,本文提及的接口直传与模糊匹配逻辑,主要针对当前基于应用沙盒与链接分发生态的工程解法。未来随着全模态大模型进一步向操作系统底层(OS-Level)融合,硬件级别的跨模态意图追踪可能需要依赖终端厂商开放更底层的专属广告与归因 API(如改进版的设备标识符)。
这件事和开发 / 增长团队的关系
面对全模态大模型掀起的交互革命,团队需要迅速建立一套适配多模态并发的数据与响应机制:
面向开发 / 架构
需要紧急升级现有的事件追踪模型。在埋点系统和 API 接口设计中,必须增加用于区分流量维度的专属字段,例如:agent_platform(标识是 Qwen 还是 Gemini)、interaction_modality(标识是语音输入还是视觉输入唤起)、workflow_id(执行批次)和 scene_context(多模态上下文)。同时,务必确保 App 首启参数还原接口的调用时序处于客户端生命周期的最高优先级,以便 App 能瞬间衔接外部的视觉或语音意图。对于参数传递过程,需加强签名校验,防止恶意脚本篡改 Function Call 传入的业务数据。
面向产品 / 增长
增长的底层逻辑正从“争夺屏幕曝光率”演变为“争取被全模态 Agent 高频调用”。团队需要利用全渠道看板,严格分离出传统人类用户的触屏转化与 AI 工作流的自动转化表现,重新定义哪些是“高优主路径渠道”。针对不同的 AI 硬件生态(如智能家居、车载大模型、AI 眼镜)调整投放策略与商务拓展,利用“场景还原”机制为大模型用户设计极致顺滑的免搜索体验闭环,把有限的预算倾斜给那些真正能带来高频高净值业务调用的模态入口。

常见问题(FAQ)
Qwen3.5-Omni 的全模态架构和普通的“多模态拼接”有什么区别?
传统的拼接方案通常是将独立的语音识别(ASR)、大语言模型(LLM)和文本转语音(TTS)模型强行串联,这会导致严重的级联延迟和信息损耗(例如语气、情绪在转成纯文本时被丢弃)。Qwen3.5-Omni 采用的是端到端原生架构,音频、视觉信号直接由底层的 Hybrid-Attention MoE 神经网络统一编码和推理,各模态共享语义表示。这种架构不仅延迟极低,还能让模型同时理解画面中的动作和伴随的背景声音。
Audio-Visual Vibe Coding 是如何实现音视频直接生成代码的?
这项能力并非工程师提前写好的特定规则,而是模型在进行超大规模多模态 Scaling 过程中“自然涌现”的泛化能力。当模型接收到摄像头的视频流(如用户在白板上画的原型草图)并结合麦克风采集的口述需求时,它的视觉编码器和语言解码器会联合进行跨模态推理,将抽象的视听意图直接映射为结构化的前端代码语言(如 HTML/CSS/JS 或 Flutter),从而绕过了传统的人工 PRD 编写阶段。
为什么新模型要将 API 价格降到这么低(每百万Tokens不到0.8元)?
大幅降价是大模型厂商抢占企业级市场和开发者生态的核心商业策略。全模态模型的应用场景(如长达十数小时的音视频解析、高频的视频流实时交互)会消耗极其庞大的 Token 量。如果维持原有的高昂定价,开发者将无法承担实时多模态 Agent 的运行成本。将价格打到 Gemini-3.1 Pro 的十分之一,旨在鼓励开发者毫无负担地将 Qwen3.5-Omni 接入智能硬件和边缘设备,快速确立行业标准。
搭载复杂 Function Call 的模型会存在越权调用风险吗?
存在此类风险。当模型具备自主决定是否联网或调用第三方服务(如支付、下单)的能力时,如果不对其边界进行严格的权限控制,可能会遭遇提示词注入(Prompt Injection)或不可控的“幻觉”操作。业内通常的解法是在关键的执行节点(尤其是涉及财务和隐私的操作)前,设置强制的“Human-in-the-loop”(人类介入确认)机制,并在接口层对大模型的请求参数做严密的类型和逻辑校验。
行业动态观察
从宏观产业视角来看,阿里云此次发布 Qwen3.5-Omni 并取得霸榜 SOTA 的成绩,标志着国产大模型在全模态赛道已经不仅是“追赶”,而是具备了全球领先的定义能力。 中针对该模型的极高关注度也印证了这一点。大模型技术正无可阻挡地从单纯的逻辑推理引擎,向具备物理世界感知与执行能力的“超级中枢”演进。