QClaw内测体验:能用微信指挥AI干活,私域链路怎么变?
 openinstall运营团队|
openinstall运营团队| 2026-03-19|
2026-03-19| 301
301
从腾讯电脑管家团队低调内测 QClaw 开始,“在微信里对着一只小龙虾发消息,让它远程操控电脑干活”迅速刷屏:本地一键部署 OpenClaw、内置多家国产大模型、微信扫码绑定后即可在聊天框下指令,让它查文件、跑脚本、甚至整理发票和写代码,安装流程被压缩到几分钟内。多家媒体实测都提到,用户几乎不需要懂环境配置,只要下载、安装、扫码就能把 QClaw 跑起来,让 AI 在电脑上执行复杂任务。 的官方介绍则把这套能力概括为“随时随地,微信一下,QClaw 帮你搞定一切”。
这背后真正值得 App 团队关注的,并不仅是“AI 终于能帮忙干活”,而是私域运营链路被悄悄插入了一层“聊天框里的 AI 中控”:用户不一定自己点链接,而是把任务丢给 QClaw 去点、去跑、去执行。对于依赖微信私域拉新和转化的 App 来说,最大的问题变成了——当一个动作既可能是“人手点击”,也可能是“AI 代劳”,你要怎么记渠道、怎么做归因?
从新闻到用户路径的归因问题
先把典型路径摊开。以一篇 QClaw 评测文章里的场景为例:运营在微信群里发了一个“2026 年博客数据总结”的任务链接,用户看到后并没有自己点开 Excel,而是在微信里对 QClaw 说“帮我整理一下下载目录里 2025 年的博客发票/文章”。QClaw 在电脑端打开文件夹、调用本地工具做分析,再把结果以图片或文件形式通过微信客服通道回传给用户。
如果把这套能力迁移到 App 私域运营中,真实链路就会变成: “用户在微信群或企微客户群里收到活动链接 → 把需求转发给 QClaw 或直接用语音/文字指令描述 → QClaw 在桌面浏览器或客户端里打开 H5/小程序、执行下一步操作 → 需要时再唤起或下载 App → 最终结果通过微信消息返回给用户”。在这条链路中,微信端的入口和触达节点没有变,但“点击”和“操作”的那一段,越来越多地被桌面端 AI 代理接管。
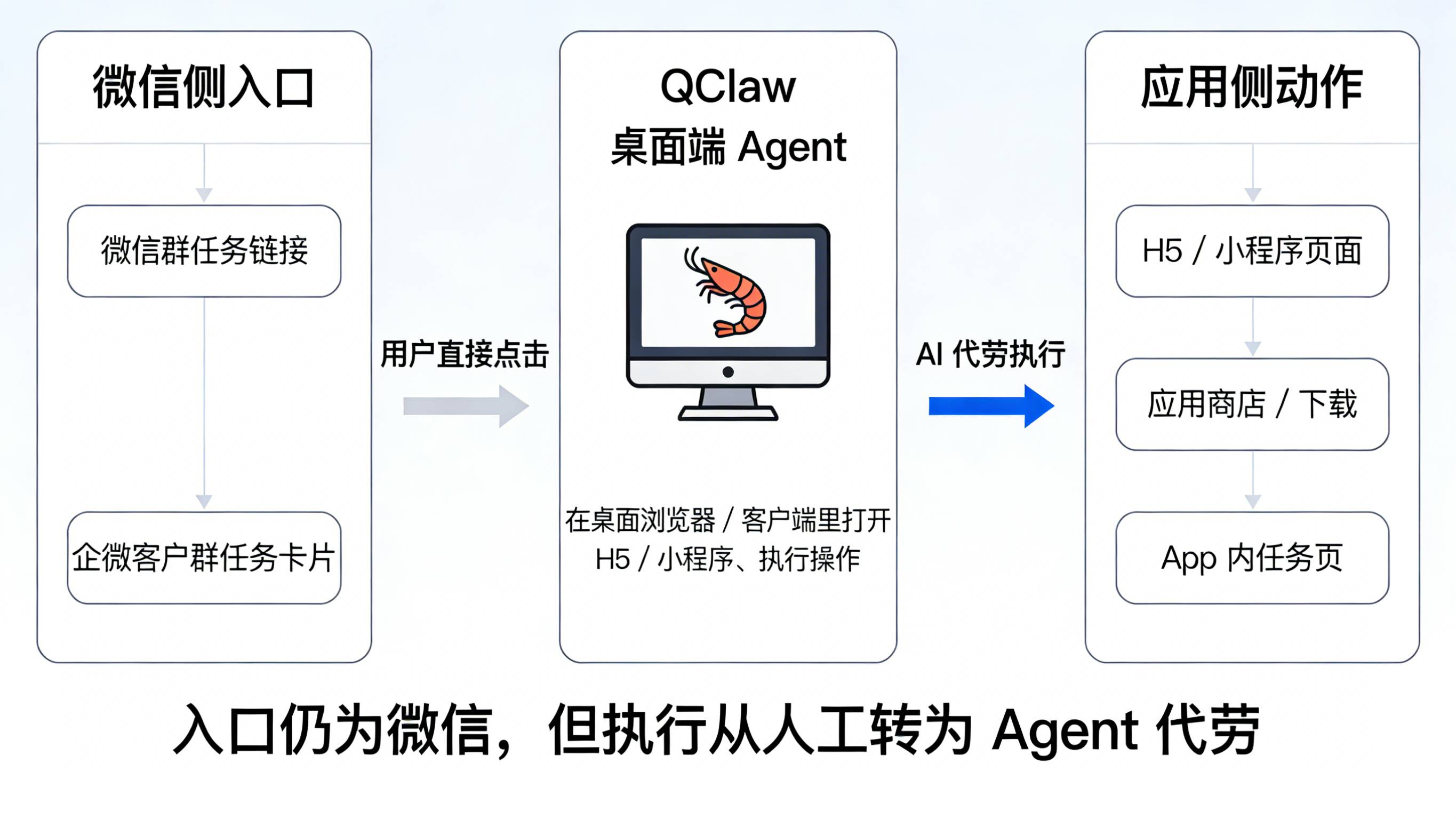
从数据视角看,这会带来几类典型问题:
-
在渠道统计上,埋点仍然只看到“来自微信的点击/安装”,却看不见这一步是“用户手点”还是“桌面 Agent 代表他点”;
-
在设备与画像上,如果大量安装与活跃事件集中在少数桌面设备/IP 上,就既难分清运营在做自测脚本,还是用户在用 QClaw 代劳,也难识别灰产是否在借助龙虾生态批量刷任务;
-
在漏斗分析上,微信 → H5/小程序 → 应用商店/App 的每一跳本来是“人机交互”,现在变成了“人对 AI 说话、AI 对系统动手”,而你现有的归因模型大多默认“每一步都是人点的”,这会直接放大黑盒区间。
如果继续用传统视角,把所有来自微信的行为一股脑归到“私域-微信群-某活动”,不区分“人手 vs Agent”,短期内也许看上去很美(转化涨了、任务完成率提高了),但长期会严重扭曲渠道评估,甚至为恶意脚本和刷量腾出了空间。
工程实践:重构安装归因与全链路统计
给“微信指挥的 AI”单独建一条渠道
第一步,是在渠道模型里承认“Agent 渠道”的存在,而不是把它混在“微信私域”的总桶里。只要承认桌面 Agent(如 QClaw)是一个独立的执行源头,就应该在渠道维度给它一条专门的路径。
具体做法上,可以约定:
-
所有“预期会被 QClaw 等 Agent 执行”的私域链接(群公告任务、长尾活动页、运营用的脚本入口),统一增加一层 Agent 相关参数,如 channel=wx_group、exec=agent、agent_type=qclaw、task_id=xxx;
-
当用户最终完成安装或首次打开时,通过 把这些字段完整回传到服务端,并落在用户与事件两个维度;
-
报表侧在渠道维度上增加“执行方式”维度,把“微信-群-活动 A-人手执行”和“微信-群-活动 A-Agent 执行”分拆成两条可对比的曲线。
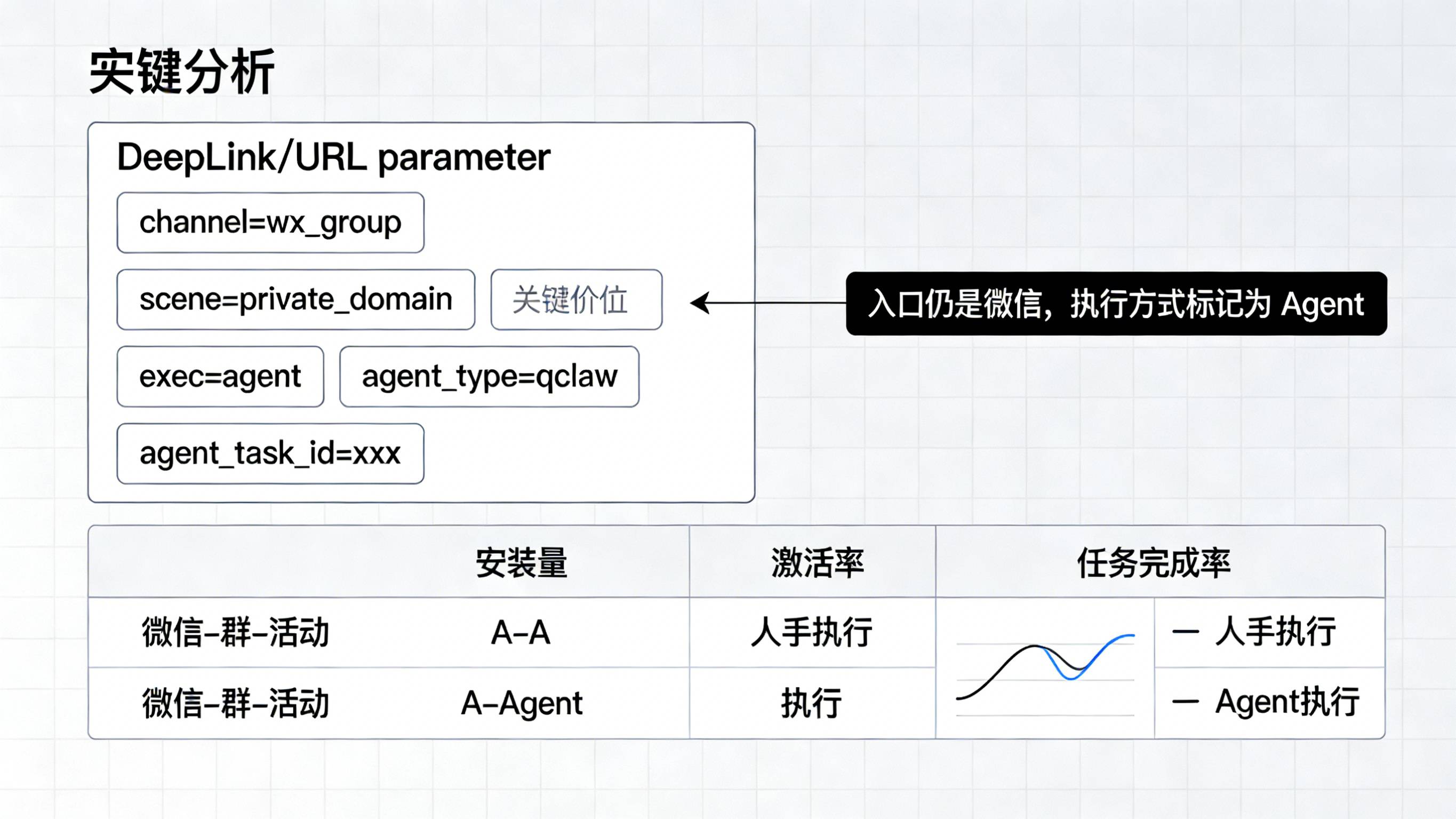
这样,你可以继续把“入口”归在微信私域下面,但能一眼看出“有多少安装/激活是人自己点出来的,有多少是用户或运营用 AI 代劳的”,避免在策略讨论时陷入“大家都说私域很强,但谁也说不清真实人效”的尴尬。
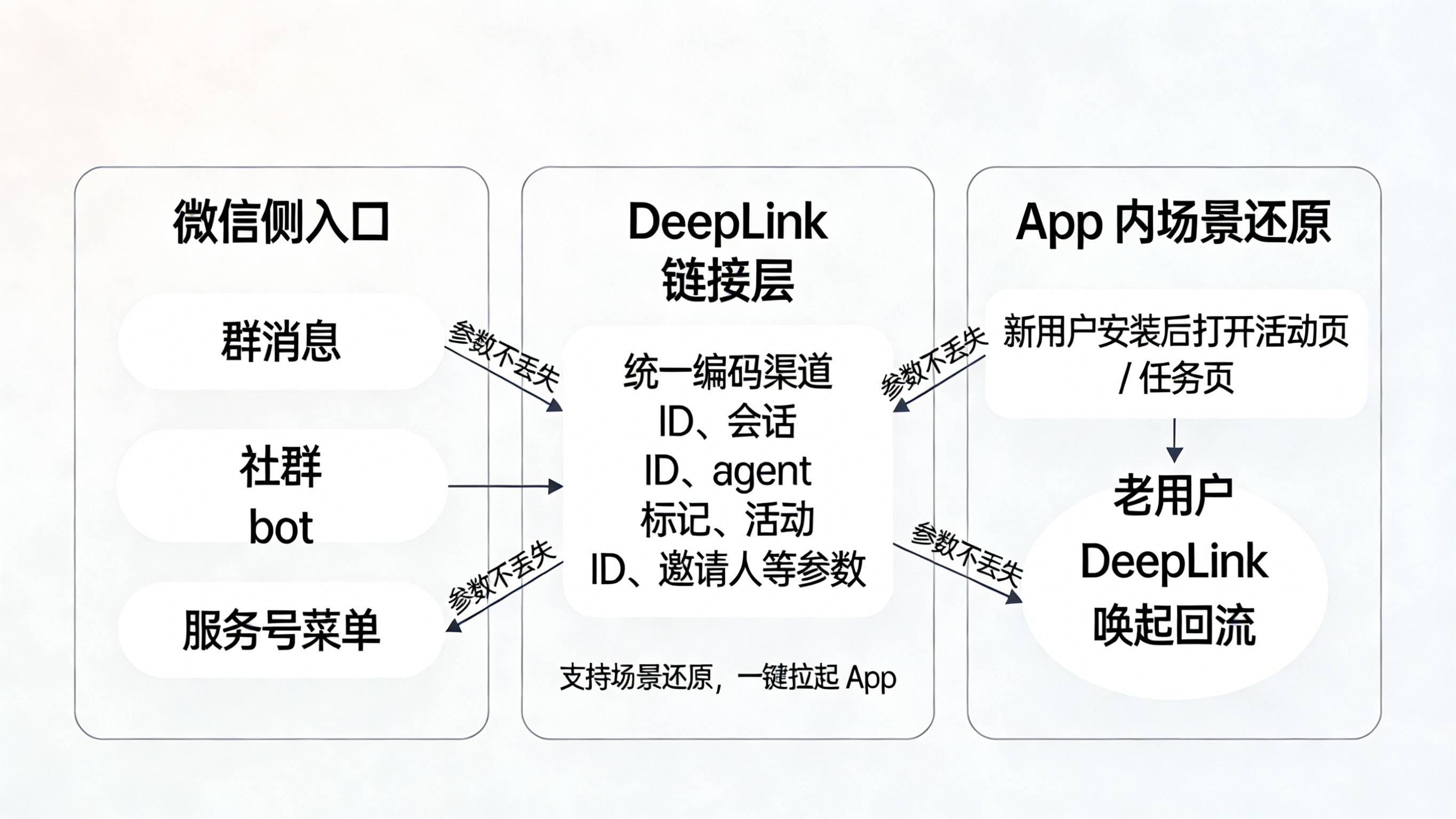
用 DeepLink 接住从微信到 App 的每一跳
第二步,是把“从微信入口到 App 内页面”的参数链彻底打通,尤其是在“AI 代劳”越来越常见的前提下,不能再依赖“用户点按钮”的默认假设。
工程实践上,可以分为两层:
-
在微信侧,无论是群消息、社群 bot 还是服务号菜单,只要目标动作是“下载/唤起 App”,就统一采用支持场景还原的 DeepLink,将渠道 ID、会话 ID、agent 标记(是否来源于 QClaw 任务)、业务参数(活动 ID、邀请人等)编码进链接中,并通过 保证参数在浏览器跳转、应用商店中转、小程序回跳等环节都不丢失;
-
在 App 侧,对新装用户在首次打开时自动还原场景(如打开指定活动页/任务页),并把“执行方式=Agent or 人手”“Agent 类型”等字段写入会话与用户画像,老用户则按同样逻辑处理一次“由 DeepLink 唤起”的回流。
当用户亲自点微信卡片,或者在外面对 QClaw 说“帮我把客服群里的 618 任务全部完成”,最终那一次下载或唤起都能被统一视为一次带完整上下文的 DeepLink 会话,从而让归因和行为分析拥有一份“干净的 Ground Truth”。
{
"base_url": "https://example.com/campaign/618",
"query": {
"channel": "wx_group",
"scene": "private_domain",
"exec": "agent",
"agent_type": "qclaw",
"agent_task_id": "task_20260318_001",
"inviter_uid": "u_987654321",
"campaign_id": "618_2026"
}
}在统计与风控里显式标记“Agent 流量”
第三步,是在数据与风控体系中,把“Agent 流量”从一开始就标出来,而不是等到出现异常再临时拼字段。
可以考虑在数据模型中新增几类字段:
-
在事件层,为安装、激活、核心转化事件增加 is_agent_traffic、agent_type、agent_session_id 等属性,用于在 中灵活过滤和对比;
-
在用户画像层,增加最近一次由 Agent 触发的会话时间、历史 Agent 会话次数、常用 Agent 类型等画像字段,用于后续在留存、付费分析和用户分群时做交叉观察;
-
在风控规则中,把“短时间内来自同一桌面环境的高频事件 + Agent 标记”视为一类需要关注的模式,与典型刷量模式(异常 CTIT、IP 段集中、虚拟设备特征)区分开来:前者很多是运营/用户在用自动化提效,后者则可能是借壳刷任务。
有了这些标识,运营团队就能在回看活动时有两个视角:
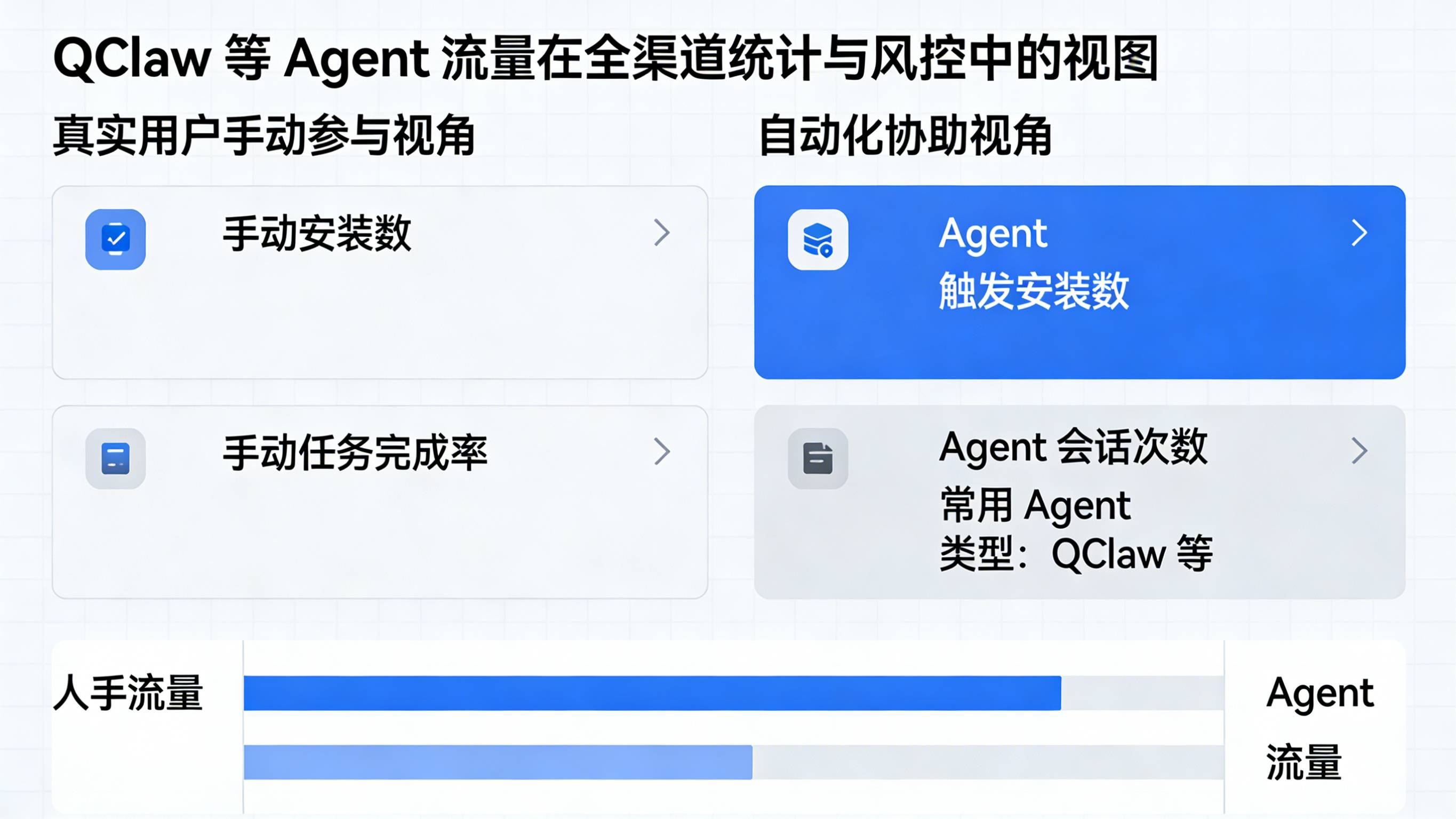
-
一个是“真实用户手动参与”的视角,只看 is_agent_traffic=false 的数据,用于评估活动设计与素材本身的效果;
-
另一个是“自动化协助”的视角,只看或优先看 is_agent_traffic=true,用于评估 QClaw 等工具在提高任务完成率上的价值,以及在什么边界内是“安全可控的效率提升”。
{
"event": "app_install",
"properties": {
"channel": "wx_group",
"sub_channel": "group_xxx",
"campaign_id": "618_2026",
"is_agent_traffic": true,
"agent_type": "qclaw",
"agent_session_id": "sess_1742370000",
"device_os": "iOS",
"app_version": "3.2.1"
},
"user_profile": {
"uid": "u_123456789",
"last_agent_used_at": "2026-03-18T09:30:00+08:00",
"agent_used_times": 5
}
}
这件事和开发 / 增长团队的关系
对开发和架构团队来说,“能在微信里指挥 AI 干活”听上去是交互体验,但落地到工程细节,其实是接口与数据层的重新设计。你需要提前回答几个问题:
-
所有会被 QClaw 等 Agent 调用的 H5、小程序和 API,是否已经预留了渠道和执行方式字段?
-
归因回调接口是否已经通过签名、IP 白名单或 API Gateway 做了足够的隔离,不会被桌面 Agent 直接拿来批量刷安装/激活?
-
日志与审计系统能否在出现异常安装/行为峰值时,快速追溯到“是不是某个 Agent 任务在重复执行”,而不是只看到一个模糊的“微信渠道暴涨”?
对产品、运营与增长团队来说,这件事更像是“重新定义私域里的主路径”。例如:
-
哪些任务是你希望用户亲自点击去完成的(如高价值任务、强参与感任务),哪些是可以放心交给 QClaw 这类 AI 去自动跑的(如数据拉取、日报生成、基础任务补做);
-
在活动设计上,是否需要单独为“AI 协助完成”的路径设定不同的奖励或权重,避免用户完全“甩给 AI 代劳”导致参与感下降;
-
在预算和渠道评估上,是否要把“Agent 渠道”视为一种“内部效率工具”,单独看其 ROI,而不是和自然增长或投放增长混在一起。
简单说,当“聊天指挥 AI 干活”变成常态,产品和增长需要一起决定:哪些环节必须是人来做决策,哪些环节可以让 AI 去帮忙执行,并把这种区分在数据和权限上都表现清楚。
常见问题(FAQ)
微信里由 QClaw 点开的链接,应该算在微信渠道还是 Agent 渠道?
更合理的方式,是“双维度标记”:入口仍然归在“微信私域”下面,以便衡量这个入口的整体价值;同时在执行方式维度上标记“is_agent_traffic=true、agent_type=qclaw”。这样既不会削弱微信入口的渠道贡献,又能在分析和风控时,一键过滤出所有由 Agent 执行的行为,单独评估它们的质量与风险。
让 QClaw 自动完成微信群任务,会不会纵容刷量?
风险不在“允许 AI 自动完成”,而在“统计口径里看不见 AI”。只要所有由 QClaw 触发的行为都被明确打上 Agent 标记,并在风控规则中为这类流量设置合理的频控、额度和核验(例如高价值任务要求设备行为闭环完整、设备画像合理),那么它更多会被用作提升真实用户完成效率的工具;真正的刷量往往是躲在“看不见是谁在点”的数据里。
是否需要为 QClaw 等 Agent 单独设计一整套埋点方案?
不必推翻重来,但需要在现有埋点方案中系统性扩展:在关键事件的公共属性中增加 is_agent_traffic、agent_type、agent_task_id 等字段,在用户画像中增加“是否使用过 Agent”“最近一次 Agent 行为时间”等指标即可。这样既不会打乱已有的数据仓库结构,又能为未来可能接入的更多 Agent(不只有 QClaw,也包括企业自建智能体)留出“统一观测窗口”。
行业动态观察
从更宏观的视角看,QClaw 并不是孤立的一只“小龙虾”,而是腾讯在 OpenClaw 热潮之下,对“行动式 AI + IM 入口”组合的一次集中押注:一端是基于 OpenClaw 的本地一键启动包和数千种 Skills 生态,另一端是微信/QQ 这一对国民级入口,中间由电脑管家团队构建的安全与运维能力把这套系统包裹起来。 提到,QClaw 内测的核心卖点之一,就是兼顾本地部署的安全性与微信直连的高触达。
对 App 开发与增长团队而言,这一轮演进最大的启示在于:真正的“新入口”不一定是一个全新的 App,而是用户已经用惯的聊天界面。当用户习惯在微信里对 AI 下命令,让它自动跨应用跑任务时,传统基于“用户自己点按钮”的路径设计就会显得越来越笨重——你需要的是一套同时看得见“人手点击”和“Agent 代理行为”的数据与归因体系。谁能更早把这两者放在一张图里来优化,而不是把 AI 行为当作黑箱,谁就更有机会在下一代私域运营和多端分发竞争中抢到先手。