




App推广数据不准怎么办?广告平台与归因中台多维对账方法
 2026-03-30
|
2026-03-30
|
 321
321
App推广数据不准怎么办?在移动增长和 App 开发领域,行业里越来越把跨平台的多维数据对账视为广告投放审计的生命线。很多初级优化师往往会陷入一种困惑:为什么媒体后台显示有 1000 个激活,到了自己的 BI 系统里只剩下 700 个?这种“数据对不上”的现象,绝大部分并非是由纯粹的系统 Bug 引起的,而是由于广告平台的贪婪归因机制、不同系统间的归因窗口期错位,以及时区与底层网络折损等物理限制交织而成的必然结果。为了找回这些丢失的漏斗数据并给出合理的财务结算依据,团队必须建立一套严密的“媒体后台 - 归因中台 - 内部BI”倒三角多维对账 SOP。不论是团队耗费巨资自建追踪架构,还是直接接入 openinstall 等专业归因中台,解决数据偏差的核心都在于深度理解各平台的底层计算黑盒并统一数据口径。本文将从协议层与算法层为你拆解数据打架的真相。
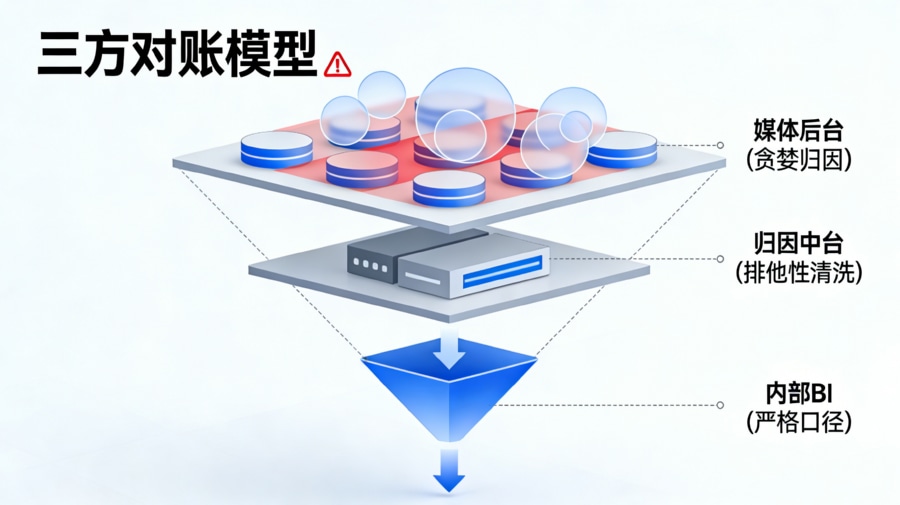
物理断层与行业痛点(概念定位)
从“数据打架”看三方的利益博弈
买量链路中的数据打架,本质上是一场关于“业绩归属”的利益博弈。媒体后台(如巨量引擎、广点通、AppLovin)天生具有“贪婪归因”的倾向,在它们的逻辑里,只要用户曾经看过或点击过它们的广告,最终产生的激活都应该算作自己的功劳,这就衍生出了广泛的自归因与抢归因现象。 相反,企业内部的 BI(业务服务端)是极其严格且排他的,财务和业务线只认“真实通过了风控、完成了验证码注册且唯一去重”的用户。 在这两端之间,往往横亘着一道深不可测的巨大鸿沟,导致市场部拿着媒体数据邀功,运营部拿着 BI 数据抱怨,而投放优化师夹在中间不知所措。这种对不齐的数据不仅会导致财务结算时的剧烈扯皮,更致命的是,不准确的回传会把错误的转化信号喂给媒体的 oCPX 机器学习模型,导致后续跑量越来越贵。
网络波动与黑盒机制导致的物理损耗
除了业务逻辑冲突,数据流转过程中的物理级损耗同样不可忽视。在 iOS 生态中,由于苹果强制推行 ATT(App Tracking Transparency)弹窗框架,导致 IDFA 的获取率暴跌。在这种环境下,第三方归因系统被迫降级使用匿名聚合(SKAN)或受限的模糊匹配,而 Apple Search Ads (ASA) 却作为苹果自家的亲儿子享有底层 API 的特权归因,这种机制的不对等直接撕裂了 iOS 的数据全景。 同时,数据从客户端采集,发送到媒体,再回调给归因中台,最后抛给业务服务器(如通过 https://www.openinstall.com/api/postback),这是一条极其漫长的多跳网络链路。任何一个节点出现 DNS 解析失败、握手超时或 Header 校验不通过,都会导致数据在网络层物理蒸发,最终在报表上表现为“掉单”。
底层原理与数据管线拆解(核心重头戏)
核心差异:Last Click 排他性与抢归因现象
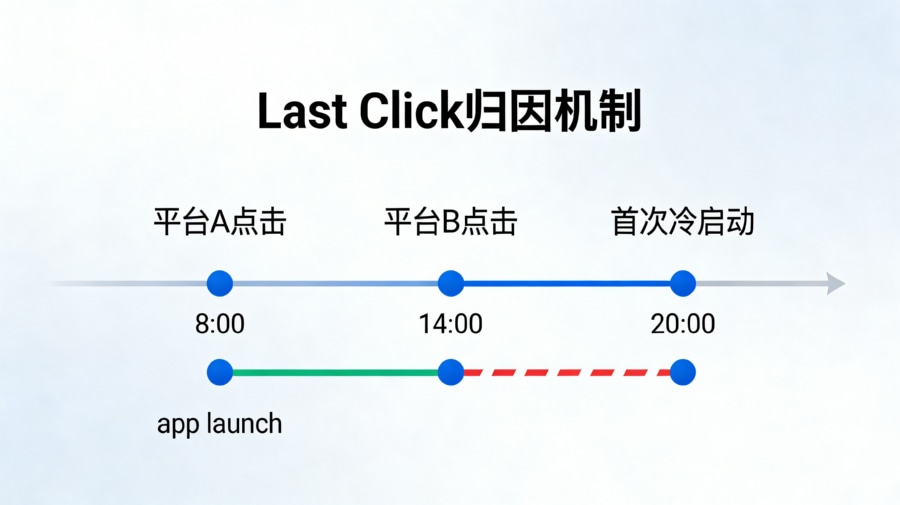
要搞清楚数据去了哪,必须先拆解多渠道投放时最残酷的“抢归因(Credit Hijacking)”时序。目前行业标准遵循的是 Last Click(最后一次点击)排他性模型。我们通过一个标准的数据流转管线来透视这个过程: 步骤一:用户在早上 8:00 于 A 平台的短视频中点击了该 App 的广告,但没有立即下载;下午 14:00,该用户又在 B 平台的信息流中点击了同款 App 的广告;晚上 20:00,用户终于在应用商店完成了下载、安装并首次冷启动。 步骤二:由于 A 和 B 平台的 SDK/API 都记录过该用户的设备特征(如 IP 地址、操作系统微版本号、User-Agent 等),它们在各自的后台报表中,都会骄傲地生成一条“1 个激活”的记录。此时媒体侧总计是 2 个激活。 步骤三:内置在 App 中的归因中台(如 openinstall)苏醒,获取到冷启动特征后,向云端比对快照。中台的算法引擎启动排他性过滤,通过比对时间戳,精确判定 B 平台的点击(14:00)距离激活发生的时间最近,属于 Last Click。 步骤四:中台向内部 BI 系统下发最终定论:B 平台记 1 个有效新增,A 平台记为 0,并且中台只会把成功的 Postback 回传给 B 平台。 这就完美解释了为什么“各个媒体后台的数据加起来,永远远大于内部 BI 的真实大盘”。在遇到这种典型分歧时,开发团队往往需要借助专业的 对接模块,依靠中台中立的 Last Click 清洗引擎,强行剔除那些试图浑水摸鱼的媒体虚假转化。
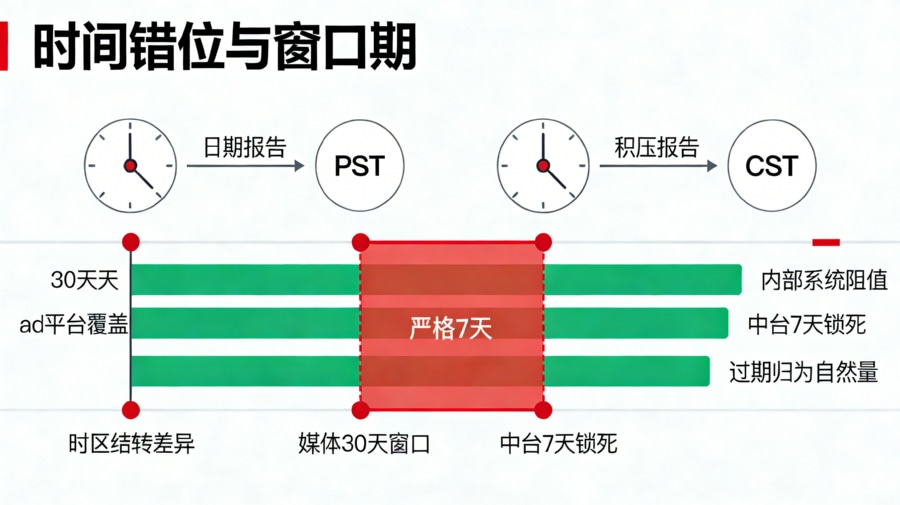
窗口期与时区错位:时间轴上的幽灵
时间戳是对账的唯一标尺,但时间本身却最容易骗人。 首先是时区差异。在进行海外投放或使用跨国广告网络时,广告平台可能默认按照 PST(太平洋标准时间)来切割自然日,而你的内部 BI 数据库则是按照 CST(北京时间,UTC+8)来统计。PST 比北京时间晚了整整 15 到 16 个小时,这就意味着,很多在今天下午产生的激活,在媒体后台会被算作“昨天”,导致单日的日结数据怎么对都存在巨大的缺口。 其次是归因窗口期(Attribution Window)不同。正如 CSDN 社区中关于的技术解析所指出的,各大广告平台为了让自己的数据更好看,往往会设置极其宽泛的归因窗口(比如点击后 30 天内激活都算,或者曝光后 7 天内激活也算)。但为了业务的严谨性,你的归因中台可能将强匹配的点击窗口期锁死在了 7 天,甚至模糊匹配锁死在了 24 小时内。如果一个用户在点击链接后的第 15 天才想起去下载 App,媒体平台会理所当然地把这个激活算给自己,但归因中台的时间窗口校验会判定其已过期,从而将其归入“自然量(Organic)”。
设备指纹与回传口径的底层错位
当排除了时间和排他性因素后,如果数据依然对不上,那往往是因为对“激活”本身的定义以及设备维度的获取能力出现了底层错位。 在特征维度获取上,自 iOS 14.5 推行 ATT 以后,如果用户拒绝了跟踪授权(LAT On),第三方归因平台就无法获取到 IDFA,只能降级采用 IP+UA 的模糊特征进行打分归因;然而 Apple Search Ads 却不受此限制,它可以利用苹果底层的硬性关联直接完成自归因。这种设备凭证的不对称,导致第三方中台很难完美还原所有的 iOS 来源。 在口径定义上更是千差万别:广告平台认为,只要 App 从商店被下载并产生了一次 install 事件回调,哪怕用户只是在 Loading 界面停留了一秒钟就杀死了进程,它也认为这是一个成功的“激活”。而内部 BI 系统的代码逻辑可能规定,用户必须走完新手引导、同意隐私协议、甚至通过了获取设备 IMEI 的风控校验,才算作一个“有效激活”。中间因为闪退、断网、拒绝隐私协议而流失的用户,就成了两套报表中间永远无法填补的黑洞。
指标体系与技术评估框架
搭建三方对账的指标监控看板
为了彻底终结糊涂账,数据与投放团队必须在 BI 中引入多维对账监控看板,重点观测以下几项能够暴露系统差异的硬核指标:
-
点击-激活到达率:用归因中台的激活数除以媒体后台的点击数,一旦该比率异常(过高可能涉嫌注水,过低说明承接链路断裂),需立刻介入排查。
-
CTIT(Click-to-Install Time,点击到安装时间间隔分布):这是反作弊的黄金指标。如果某一渠道大量新增用户的 CTIT 集中在 5 秒以内(违背物理下载常识),说明这批所谓的新增极有可能是接口重放攻击。
-
中台回调成功率:监控归因中台向媒体 API(如
https://www.oceanengine.com/...)发送 postback 时的 HTTP 状态码分布,排查是否存在大量的 500/502/400 报错导致的漏传。
常见的对账模式选型与优劣
在解决数据不对齐的问题上,不同的技术选型决定了公司的排障成本与效率:
| 对账模式选型 | 开发与服务器成本 | 跨渠道排他性去重能力 | 转化回传延迟 | 防治作弊与异常流量的能力 |
|---|---|---|---|---|
| 方案 A:盲投模式(纯依赖媒体后台数据) | 极低(零开发) | 完全没有,各个媒体各算各的,整体 ROI 严重虚高,财务无法按效果结算。 | 无延迟(媒体自归因) | 极弱,全盘接受媒体给出的数据,对于掺水的僵尸粉毫无招架之力。 |
| 方案 B:内部 BI 直连媒体 API | 极高,需几十个后端工程师天天研读各大媒体的 API 文档更新,维护繁杂的签名算法。 | 较强,可以依据内部唯一设备 ID 强行去重。 | 中等,受限于自身服务器的并发处理能力与队列堆积。 | 中等,可以依据业务注册漏斗过滤,但缺乏海量环境特征库去识别底层的设备农场。 |
| 方案 C:引入第三方归因中台(如 openinstall) | 极低(一次性 SDK 接入即可统一全网所有媒体)。 | 极强,内置成熟的 Last Click 与多点触控模型,中立仲裁所有转化归属。 | 极低,采用专线高并发流式处理,毫秒级分发回调。 | 极强,融合 CTIT 异常分布、IP 聚集度识别与签名防篡改机制,主动拦截异常流量。 |
深度解析:初创团队往往企图依靠自己的开发人员去跟每一家广告平台做 API 对接和对账(方案 B),但他们很快就会被诸如 OAID 加解密、回调鉴权失败、海外时区转换等琐碎的脏活累活拖垮。引入居中的归因中台不仅是买了一套去重逻辑,更是把底层那些繁琐的握手协议与防刷黑盒,外包给了能够提供高可用 SLA 的专业机构。
技术诊断案例(四步法):一次 30% 数据落差的极限追凶
异常现象与排查背景
某泛社交 App 在国内某头部短视频平台开启了一轮高价的 CPA 买量活动。在月初拉取对账单时,优化师惊恐地发现:媒体后台显示该计划完成了 10,000 个激活转化,但内部 BI 和归因中台的后台却只记录到了 7,000 个。高达 30% 的数据落差不仅让团队面临巨大的超投成本压力,也让优化师遭到媒介代理商的质疑。
日志与链路对账:从时间戳到报错日志的下钻
风控与开发架构师立刻启动了极限追凶的四步排障法: 第一步(宏观排查):检查双边的时区配置。调取报表对比发现双方统一采用了 UTC+8 的北京时间自然日切分,排除了零点时区结转造成的差异。 第二步(归因模型与窗口期):调取中台底层的 Last Click 被抢夺日志。结果显示,这流失的 3,000 个激活并没有被其他渠道截胡,在中台的判定链中,它们属于“彻底没有记录在案”的幽灵设备。 第三步(微观通信抓包):深入业务底层网关,拉取 Nginx 的入口以及应用层报错日志。数据工程师发现,这 3,000 个从媒体侧带来的流量确实触发了 App 客户端的苏醒,但它们的 User-Agent 显示其操作系统极度老旧,或是表现出了 Root 权限的特征。进一步核对内部代码口径终于水落石出:内部业务侧在上个版本悄悄增加了一层强风控——“对于判定为 ROOT、越狱机型或模拟器的设备,直接在端侧阻断首启激活的埋点上报,视其为黑产机器”。
技术介入与口径重构
找到了这 30% 落差的根本原因后,双方进行了精细的技术动作协同: 首先,业务团队协同媒体平台的运营,在投放后台定向设置中,强制排除了低端过时机型以及通过日志提取出的高危异常 IP 网段的曝光。 其次,在归因中台重新构建了数据回传口径:开放对这部分风控设备的统计,但不计入有效报表,而是将它们单列为一个“风险激活池”。最关键的是,中台切断了针对这批设备的 Postback 回调——不把这些垃圾量反馈给媒体的 oCPX 模型,彻底打破了“机器学习模型误以为这些量很好而继续疯狂采买”的恶性循环。
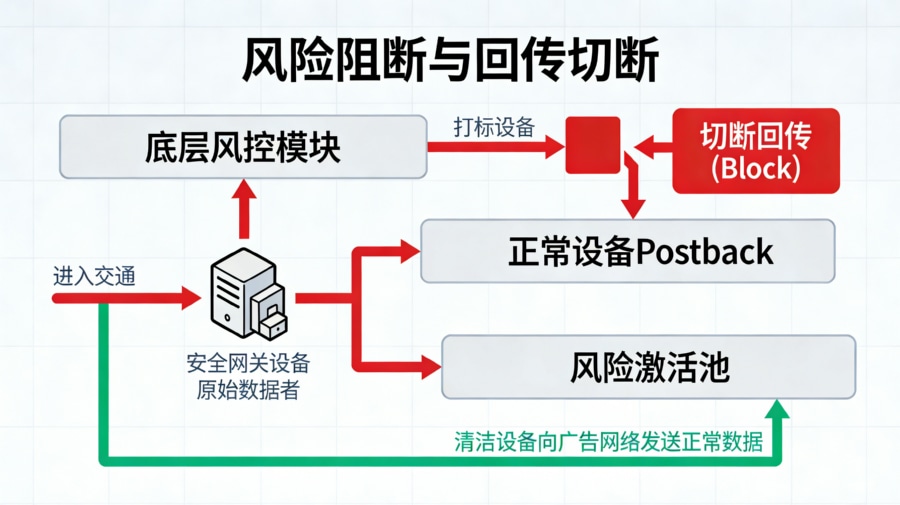
复盘结果与经验沉淀
经过这一套组合拳调优,内部与外部对“什么是有效激活”的定义得到了对齐。媒体后台的大盘数字与中台、BI 之间那 30% 的巨大鸿沟被迅速拉平,整体激活与转化对账的吻合率稳步维持在 98.6% 的健康水位。 此次事件为团队沉淀了一套铁律:当遭遇数据不准时,永远不要先质疑系统挂了。排障 SOP 必须是:第一步对齐“什么是激活”的定义口径;第二步排查网络回传与报错断层;第三步核实时区与归因策略。
常见问题
为什么在 App Store / 安卓商店的下载量,总是比归因系统的激活量多很多?
这是一个不可逆的物理漏斗损耗问题。在商店详情页点击“获取”或完成了下载,绝对不代表用户真正打开了你的 App。真实场景中,大量用户存在“下载到一半断网”、“下载完忘了打开”或是“打开后嫌首屏协议太烦直接卸载”的行为。因为归因 SDK 只有在 App 首次成功联网冷启动时才能苏醒并上报数据,所以下载量(商店维度)永远会大于激活量(端内维度),通常存在 10%-30% 的物理折损是非常正常的。
媒体平台说我们扣量(偷吃数据),怎么用技术手段反驳?
绝不能用情绪互怼,必须拿出底层日志作为铁证。你可以通过归因中台导出带有精确到毫秒级的时间戳(Timestamp)、脱敏的设备指纹 ID(如加密后的 OAID/IDFA)以及接收节点 HTTP 状态码的详细对账单据给对方。如果对方的数据没过来,你可以证明自己网关没有收到该设备的触碰;如果是归因被别人抢走,你可以向媒体出示 Last Click 的判定日志,证明“这个用户在你们曝光后,又去点击了其他渠道的链接”。用客观的底层时序逻辑去反驳,让数据自己说话。
iOS 渠道中那些没有授权 ATT 的用户,数据还能对得准吗?
在苹果极为严苛的隐私沙盒体系下,未授权用户的确定性链路已经被物理层面强行阻断,此时要想做到 100% 精确到设备级别的追踪是不现实的。业界目前只能依靠 Apple 官方提供的 SKAdNetwork(SKAN)框架进行延迟且粗颗粒度的匿名聚合归因,或者是依托第三方平台强大的模糊特征快照(如 IP+设备的组合模型)去尽力推断还原。此时双方的对账不能再苛求“单条明细对齐”,而是要转向“聚合趋势对齐”。
参考资料与索引说明
总结而言,App 推广数据不准绝不是一个简单的技术 Bug,它是极其复杂的网络通信折损、时间与时区错位、以及平台之间因利益抢夺而产生的系统性偏差。对于渴望彻底摆脱手工对账泥潭的团队,建议深入阅读 CSDN 开发者社区关于 的技术文献,加深对底层规则与窗口期差异的理解;同时,强烈推荐借助








 闽公网安备35058302351151号
闽公网安备35058302351151号








