安装归因数据报表怎么设计?从曝光到留存的指标体系搭建
 openinstall运营团队|
openinstall运营团队| 2026-03-30|
2026-03-30| 424
424安装归因数据报表怎么设计?在移动增长和 App 开发领域,行业里越来越把归因指标体系和可视化看板视为量化渠道价值、终结各部门数据扯皮的最重要基建。很多人误以为做报表就是简单地把后台的激活数、注册数拉出来画个折线图,但这仅仅是数据的物理堆砌。一个真正能够驱动业务增长的报表,必须基于统一的数据清洗口径,围绕“曝光-转化漏斗-LTV”搭建一套立体的指标体系,并针对不同岗位(如高管看大盘、市场盯转化、运营查漏点)提供分层级的多维视图下钻能力。无论是自研数据仓库还是借助 openinstall 等专业中台控制台,设计安装归因报表的核心,永远是如何将散落于 Web 端、应用商店沙盒和 App 客户端的多维埋点,组装成能够精确定位渠道作弊与流失节点的决策仪表盘。
物理断层与行业痛点(概念定位)
数据孤岛与口径冲突:为什么很多团队的报表没法看
在缺乏系统性数据架构设计的公司里,到了月末做渠道结算时,会议室里通常会爆发激烈的争吵。市场投放部门指着广告平台后台的数据说:“我们这个月带来了 10 万个激活”;运营部门拿着服务端的数据反驳:“但我们后台只看到了 3 万个真实注册用户”;而数据开发(BI)团队则拉出日志表示:“从设备首启埋点来看,去重后只有 5 万台新设备”。
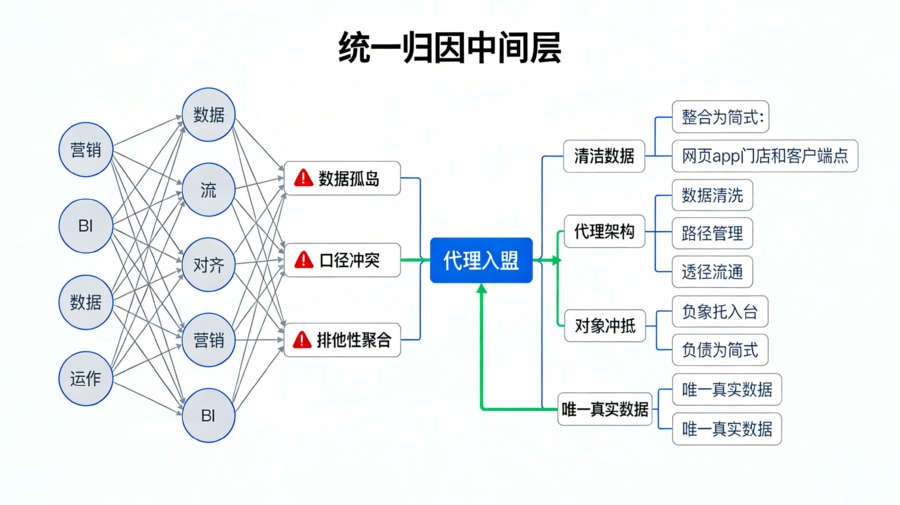
这种灾难的根源在于数据孤岛与口径的深层错位。由于从用户点击广告到最终在 App 内产生价值,中间跨越了媒体环境、应用商店和原生应用三个物理沙盒,数据没有在一个中立的“归因机制中间层”进行统一的排他性聚合与时间戳校验。各个部门都是基于对自己最有利的“单边视角”来自说自话,导致报表永远对不齐。此外,很多团队设计的看板过度沉溺于虚荣指标(如庞大却无效的点击量、粗口径的低防刷激活数),却完全忽视了真正能够拉开优质渠道与垃圾渠道差距的核心指标(例如 CTIT 归因耗时分布、设备指纹匹配度、渠道留存衰减率)。当报表无法反映真实的业务含金量时,它就成了一张毫无意义的废纸。
报表设计的底层逻辑必须是“业务驱动”
优秀的报表设计不是为了展示酷炫的可视化组件,其底层哲学必须是严苛的“业务驱动”。这意味着每一个被放进看板的指标,都必须能够回答一个极其具体的业务拷问。例如:“如果明天市场预算削减 30%,我应该砍掉哪条投放线?”“为什么某个信息流渠道带来的下载量极大,但次日留存率却惨不忍睹?”
为了支撑这种灵魂拷问,体系化的指标建设必须遵循“主干目标”与“枝干支撑”的逻辑结构。主干目标是你当前阶段的北极星(如“提升单个用户的有效转化价值”),而枝干支撑则是那些能够帮你排查问题的细分颗粒度参数(如网络环境、机型分布、地域时区)。如果脱离了这种树状结构去乱铺图表,必然会导致为了展示而展示,最终让所有人在庞杂的仪表盘中迷失方向。
底层原理与数据管线拆解(核心重头戏)
第一步:确保归因数据源的颗粒度与准确性
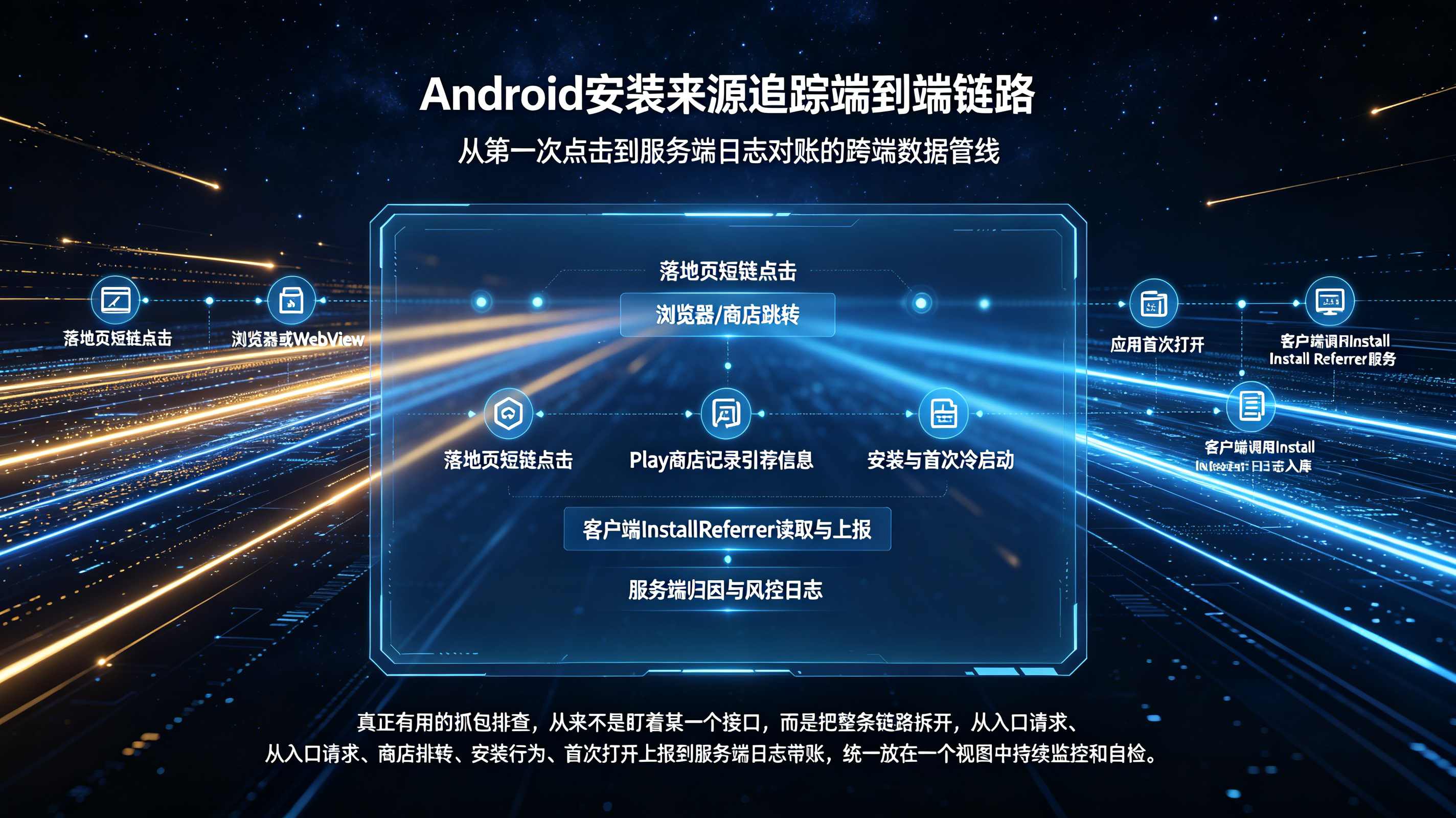
常言道“无数据不报表”,如果底层流入的数据源本身就是残缺或造假的,那么上层的任何高级算法与漏斗模型都将是空中楼阁。构建报表的第一步,是必须在数据管线的采集层建立极高密度的信息捕获机制。当一个用户点击推广链接(如 https://www.openinstall.com/landing?channel=wechat_A)时,系统不能仅仅简单地记录一个 channel=wechat_A 的粗粒度标记。
在时序采集的底层要求中:点击层必须瞬间捕获用户的环境特征快照,包括精确到网段的公网 IP 地址、操作系统主次版本号(如 iOS 16.6)、极具辨识度的 User-Agent 字符串以及屏幕物理分辨率;在链路层,必须强制计算并留存极其关键的 CTIT(Click-to-Install Time,点击到安装的时间间隔)字段,这是后续反作弊的命门;在结果层,则必须通过客户端 SDK 严密跟踪该设备是否真实完成了 App 首启、是否通过了注册验证逻辑。对于不具备庞大自研数据团队的企业,通常会选择接入如 openinstall 这类标准化的数据归因引擎,以确保流入业务报表的源数据在第一道关卡就被彻底洗净了残缺与噪声。
第二步:拆解经典转化漏斗(Funnel Analytics)
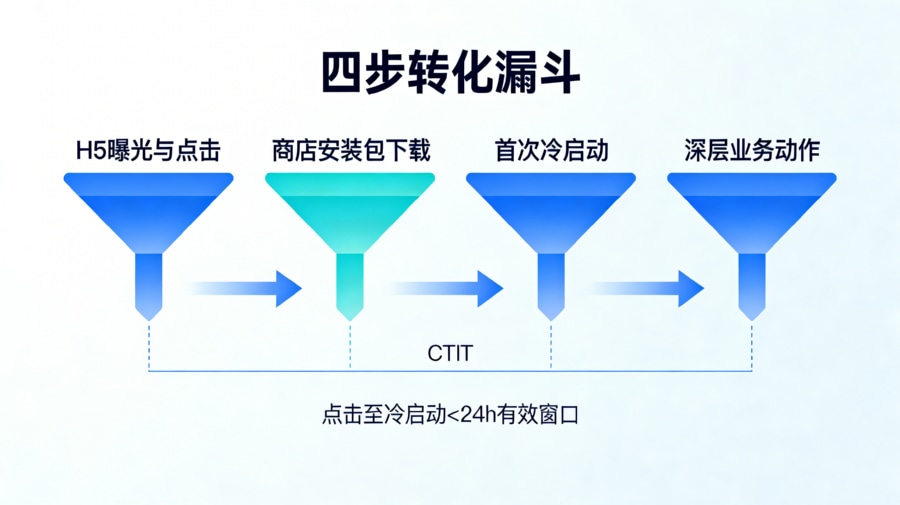
拥有了高颗粒度的数据源后,必须基于严格的时序逻辑将这些孤立的节点缝合成转化漏斗(Funnel)。一个经典的 App 渠道推广漏斗必须清晰地映射用户的真实流转路径。
节点 1 是 H5 访问曝光与点击:这决定了渠道流量的规模基盘。 节点 2 是落地页按钮点击到应用商店包体下载的转化:它衡量的是 H5 承接页的用户体验设计(UX)是否足够吸引人,以及文案是否造成了预期落差。 节点 3 是 App 安装完毕并完成首次冷启动:这一步是最凶险的跨端匹配期,它检验的是底层模糊匹配或强匹配算法是否成功将用户从网页端找回了原生端。 节点 4 则是冷启动后的关键业务动作(如完成首单或实名注册):它直接代表了渠道带来的用户质量。 在这条漏斗链路中,必须在系统规则中设置特定的转化时间窗口。例如,只有在点击发生后的 24 小时内完成首启,才被视为“有效强关联漏斗”;如果用户隔了 7 天才打开 App,其匹配权重将呈指数级衰减。这种精密的时间窗口锁定,能够极大地帮助运营团队判断流失究竟是发生在下载等待期,还是发生在 App 内的新手引导阶段。
第三步:从漏斗到留存的指标树构建(指标体系)
漏斗看的是流转效率,而留存看的则是生命周期价值。这就要求数据架构师将报表进一步升级为指标树。根据的核心原则,我们将“提升渠道 ROI”这一终极目标拆解为三大支撑模块: 首先是规模模块(拉新量):关注总曝光量、唯一设备点击量与新设备激活量; 其次是效率模块(转化率与成本):深度剖析 CVR(各漏斗层级的转化百分比)以及 CPA(单用户获取成本),将流量剥去伪装,还原为真金白银的投入产出比; 最后是质量模块(留存与 LTV):追踪次日、7 日、30 日留存率以及用户的长线生命周期价值(LTV)。为了防止各个业务线在解读时产生冲突,架构师必须在数据库层面编写一套不容篡改的“统一口径字典”(例如明确规定“激活”必须是带有合法设备特征的首启请求,且排除了越狱或 Root 设备的作弊流量),从而在根本上统一各部门的语境。
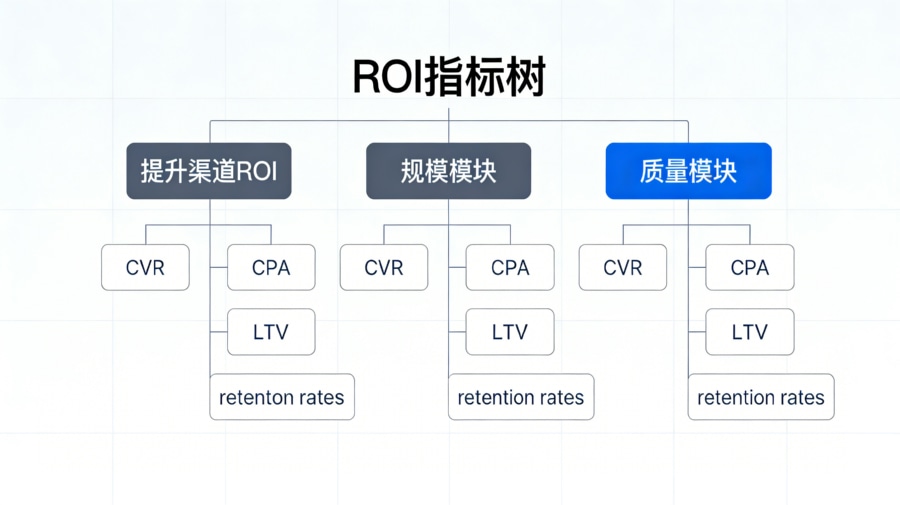
指标体系与技术评估框架
渠道归因效果评估的核心切片维度
有了大盘指标树,报表还需要能够被像手术刀一样层层切开,这就是下钻切片(Dimension Slicing)的意义。只有当你叠加了切片维度,那些隐藏在平均数背后的真相才会浮出水面。 从横向业务视角看,系统必须支持按照“推广方式”(如图文海报扫码、短视频信息流点击、短信直连跳转)以及“推广平台”(如抖音、微信朋友圈、线下电梯广告)进行交叉透视。 从纵向设备与环境视角看,报表必须支持按照“操作系统”(如对比同一条广告在 iOS 与 Android 端的转化落差)、“设备机型”(如区分高端旗舰机与低端入门机的最终付费率差异)、甚至精确到省市级的地理位置进行降维分析。只有维度足够立体,业务人员才能精准定位出“到底是广告素材不行,还是某个安卓小众机型的兼容性导致了白屏流失”。
数据看板三层视图设计参考
不同的岗位看数据的视角有着天壤之别,试图用一张大表满足所有人是不现实的。下面是一套在成熟企业中被验证过的高效看板层级架构对比:
| 视图层级 | 核心使用者 | 核心关注指标 | 时效性要求 | 常用下钻与切片维度 |
|---|---|---|---|---|
| 视图 A:管理层大盘(经营视图) | CEO、业务总负责人 | 整体新增规模、大盘次留、全渠道综合获取成本(CAC)、整体 ROI。 | T+1(日更),看长线趋势。 | 事业部、大区、核心渠道主干横向对比。 |
| 视图 B:市场投放看板(渠道漏斗视图) | 媒介采买、渠道优化师 | 单渠道曝光、点击率(CTR)、激活率、单激活成本。 | 准实时(分钟级/小时级),用于盯盘与调价。 | 具体 Campaign、落地页物料 A/B Test 批次、地域维度。 |
| 视图 C:异常诊断报表(归因复盘视图) | 数据分析师、风控安全专家 | 归因成功率、CTIT(点击到安装间隔)异常分布、同 IP 聚合度、指纹缺失率。 | 实时告警触发。 | 细分至 OS 微版本、设备指纹特征集、网段出口。 |
深度解析:如果强迫管理层去分析 CTIT 的秒级分布,不仅浪费其精力,也会导致决策失焦;反之,如果让一线的投放优化师只看 T+1 的大盘汇总,他们根本无法在流量暴雷的头几分钟内紧急踩下刹车(调整竞价或阻断无效的高耗费脏流量)。因此,严格遵循这种三层视图的分发逻辑,是彻底终结报表灾难的系统性解法。

技术诊断案例(四步法):如何利用看板定位渠道刷量作弊
异常现象与排查背景
某泛资讯类 App 正在大力推进其信息流采买业务。在某周二的上午,数据监控大屏显示“渠道 B”的激活量突然出现了极其陡峭的暴涨,单小时新增设备几乎是平时的 10 倍。然而,业务线负责人并没有感到喜悦,因为他们敏锐地发现:虽然激活大盘在疯涨,但当天的 DAU(日活)却宛如一潭死水,且新增用户的注册率与首日留存几乎跌至冰点。业务团队陷入两难:这究竟是某篇引流爆款文章真的击中了下沉市场,还是遇到了恶劣的黑产羊毛党在进行集群刷量?
日志与链路对账:看板多维下钻排查
数据风控团队迅速打开了内部的 BI 看板,启动了外科手术式的多维下钻排查。 第一步:切入“渠道漏斗视图”。数据赫然显示,渠道 B 的“点击-落地页-激活”漏斗转化率呈现出极其诡异的反常识状态:从日常行业平均的 5% 暴增到了违背物理规律的 45%。没有任何正常的广告素材能达到如此夸张的转化漏斗。 第二步:紧急打开专为防刷设计的“归因复盘视图”,重点调用 CTIT(点击到安装间隔)分析维度。图表无情地揭露了真相:该渠道有超过 60% 的所谓“激活匹配”,其发生时间距离点击操作还不到 5 秒钟。在真实的公网环境下,用户根本不可能在 5 秒内完成跳转应用商店、下载动辄上百兆的 App 包体、安装并完成首次冷启动。这是典型的“设备农场接口重放”攻击。 第三步:进一步叠加“设备分布维度”切片。系统发现,这批暴增的设备中,有 80% 极其诡异地集中在一两款过时的低端旧机型上,且它们的公网 IP 高度聚焦在某几个极其狭窄的偏远机房网段。
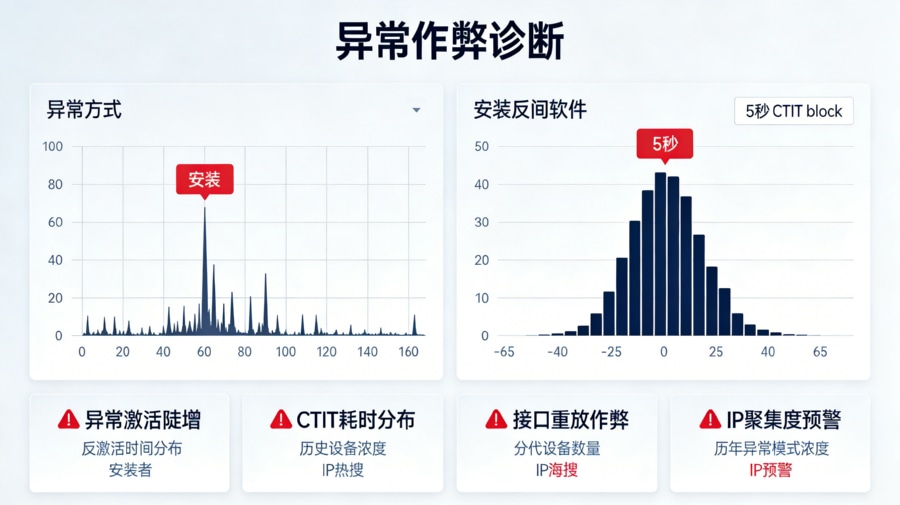
技术调优介入:阻断异常并优化看板预警
在确凿的证据面前,技术与业务部门果断采取了干预动作: 首先,在底层的归因数据源过滤层,立刻增加针对渠道 B 的阻断规则:凡是 CTIT 短于 15 秒、且落入那几个高危 IP 网段的请求,直接执行抛弃动作,不计入有效激活表。 其次,为了防止后续类似事件再次让人措手不及,团队将这次提取出的“作弊特征池”数据,直接固化为一个独立的“异常黑产拦截监控指标”,增设到了市场投放看板的醒目位置。 最后,为该防刷监控指标设定了严苛的自动阈值红线:一旦某个渠道的微小时间间隔激活占比超过 10%,系统将直接触发公司内部的飞书/钉钉群机器人进行强预警,甚至联动 API 直接掐断该渠道的归因回调接口。
复盘结果与经验沉淀
经过这一轮依靠多维报表开展的雷霆清剿后,大盘的有效激活统计精度得到了彻底修复。系统对于归因作弊特征的自动诊断与拦截覆盖率,从先前的漏洞百出,稳步维持在 98% 左右的真实且高可用监控水位。 这次风波为全团队沉淀了一条金科玉律:单纯只看一条不断向上的“激活数量统计图”是极其盲目且危险的。只有构建出基于时间切片、漏斗衰减特征以及底层设备环境特征切片的下钻结构,这套指标体系才算是真正长出了对抗黑产、挽救公司预算的獠牙。
常见问题
报表里有了点击数和安装数,为什么还需要算转化率指标?
单纯的绝对值数量极其容易被海量的曝光基数所掩盖或误导。比如渠道 A 带来了 1 万个安装,渠道 B 只带来了 2000 个安装,只看绝对值你会觉得渠道 A 更好。但如果渠道 A 的曝光基盘是 1000 万,渠道 B 的曝光只有 5 万,那么转化率(CVR)一算,渠道 B 的质量与效率将直接秒杀渠道 A。转化率是衡量路径流转健康度的杠杆指标,它无情地剔除了不同渠道因为采量规模不同而带来的评估偏见,是决定你下一步该把高昂的投放预算倾斜给谁的唯一科学依据。
搭建归因指标体系应该由研发还是业务主导?
这是很多公司会犯的路线错误。一套真正可用的归因体系必须由业务负责人和数据分析师(BI)来主导提出“业务视角的口径定义与观察维度”,研发同学仅仅是扮演技术实现的角色,通过前端埋点和底层数据建模来提供“火力支撑”。如果让技术团队闭门造车,很容易搞出一堆图表极其炫酷、堆满枯燥服务器字段、但业务人员根本看不懂也不想看的无用报表;反之,如果业务线不依靠技术去搭建系统化底座,他们永远只能深陷在每天依靠手工拼接 Excel 表格、在数字黑洞中相互指责的泥潭里。
为什么老板看到的总新增,总是跟我们后台每个渠道汇总起来的加总对不上?
这源于“去重策略”和“归因模型”的底层错位。高管看到的大盘总新增,本质上看的是基于 App 唯一设备 ID 的首次冷启动(这叫绝对物理级的硬去重)。而各渠道在抢功劳时,往往会发生重叠。例如,一个用户早上被抖音渠道 A 曝光点击,下午又被微信朋友圈渠道 B 召回并最终下载。如果没有在归因系统的中间层实行类似“Last Click(最后一次点击归因)”这种极其严苛的排他性策略,渠道 A 和渠道 B 的独立报表里都会把这个用户算作自己的业绩。只有通过归因中台执行了全局排他性清洗后,再落到最终的报表中,各个枝干渠道的累加值才能精准对齐那根主干大盘。
参考资料与索引说明
本文系统性地梳理了安装归因数据报表的深层设计逻辑,它指出优秀的指标体系绝不仅是数据的简单罗列,而是立足于无污染的底层源数据、通过精密的漏斗拆分与三层视图架构分发,最终指导业务决策的实战利器。在探讨从虚荣指标向规模、效率、质量三维一体的指标树演进时,本文参考了人人都是产品经理社区中关于 的深度结构化方法论。对于那些受困于数据孤岛、渴望一站式搭建出防刷反作弊、多维下钻看板的技术与运营团队,强烈推荐深入研究文中提及的 openinstall