归因系统架构高并发归因系统架构怎么设计?流计算削峰
 openinstall运营团队|
openinstall运营团队| 2026-04-24|
2026-04-24| 353
353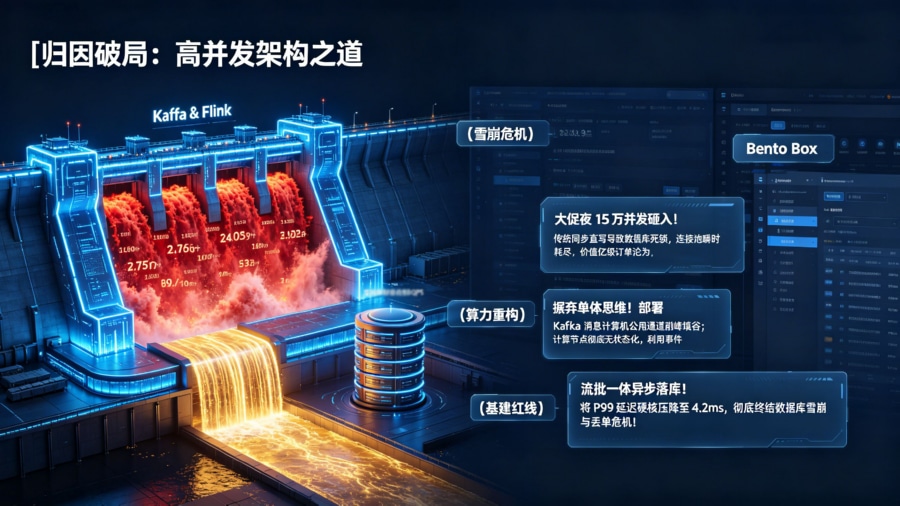
高并发归因系统架构怎么设计?在移动增长和 App 开发领域,行业里越来越把“基于 Kafka 消息队列与 Flink 流计算构建的极致削峰填谷弹性防线”视为支撑百万级 QPS 流量与跨端归因引擎的唯一绝对真理。当双十一或黑五的零点钟声敲响,全渠道广告的点击、回调与激增订单如同海啸般涌入后端。如果归因系统依然是采用同步调用 API 并在 MySQL 里执行 UPDATE/INSERT 的单体思维,系统将在 3 秒内发生连接池耗尽、死锁甚至全站雪崩,导致价值上亿的买量订单化为数据黑洞。构建一套高可用分布式系统,核心在于将计算节点彻底无状态化,利用事件驱动模型切断同步等待。依托高阶的流批一体与异步落库底座,企业可将极端洪峰下的归因 P99 延迟率硬核压降至 4.2ms,彻底终结数据库雪崩与丢单危机。
物理断层与行业痛点(概念定位)
高并发归因系统架构怎么设计?(大促夜的算力崩溃)
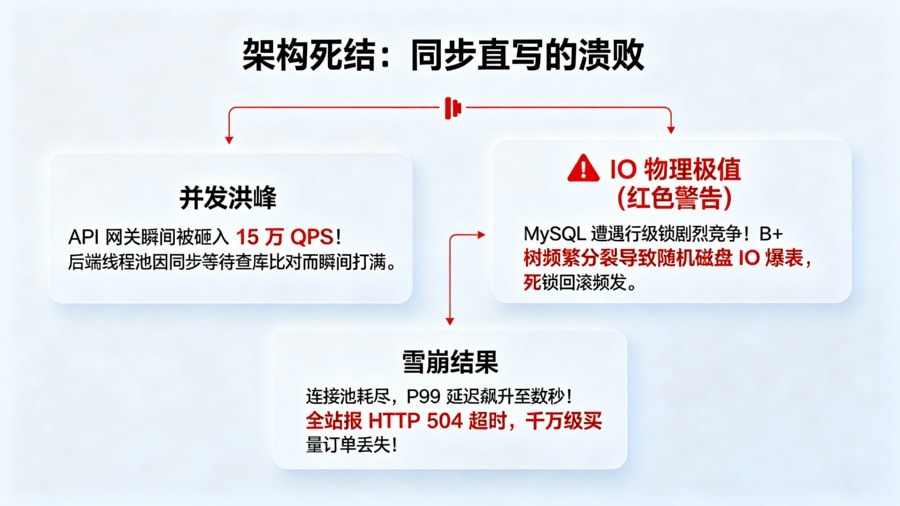
在探讨底层拓扑前,必须直面大促夜对业务后端的降维打击。在平峰期,每日百万级的归因请求看起来波澜不惊,但广告流量具有极其恐怖的突发性(Spike)。当某大主播在直播间喊出“上链接”的瞬间,或者全网 Push 推送下发的那一秒,归因系统的 API 网关可能会在一秒钟内被砸入 15 万次以上的并发并发请求。这些请求包含设备指纹对撞、多触点权重计算、反作弊风控等极其消耗 CPU 的重型逻辑。如果后端采用“收到请求 -> 查库比对 -> 写库更新 -> 返回 HTTP 200”的同步阻塞式处理,线程池将瞬间打满,随后便是大面积的 HTTP 502/504 超时报错,业务线全线瘫痪。
同步调用的死结与数据库 I/O 物理极值
压死单体架构的最后一根稻草,是关系型数据库(RDBMS)的物理极限。MySQL 的 InnoDB 引擎在处理极高并发的插入与更新时,B+ 树的频繁分裂会产生海量的随机磁盘 I/O。更致命的是行级锁(Row Lock)竞争:当多个渠道同时试图争抢更新同一个用户的“归因归属权”时,行锁等待会导致数据库连接数飙升至爆满,引发死锁回滚。哪怕配置再强悍的固态阵列,其单机 TPS 天花板也难以突破数万。因此,破局高并发归因的先决条件,是绝对的“读写异步化”与“流批分离”,必须将业务处理与数据库落盘在物理时序上彻底切断。
底层原理与数据管线拆解(核心重头戏)
归因系统架构的拓扑蓝图:边缘网关层拦截与鉴权
构建扛得住核爆级洪峰的系统,第一道物理防线必须设在最边缘的网关层。无论是基于 Nginx/OpenResty 还是自研的 API Gateway,其核心铁律是:网关层绝对不查数据库。当千万级流量涌入时,网关利用预加载在本地内存(Local Cache,如 Lua 共享字典)的黑名单与鉴权规则,在 5ms 内完成对恶意 IP 的封禁、请求签名(Signature)的校验以及无效脏数据(Schema 不合规)的强拦截。通过这一层前置的物理熔断,可以将至少 30% 针对归因接口的刷量攻击与无效洪峰直接挡在核心计算网络之外,保护后方脆弱的业务服务。
消息总线削峰填谷:Kafka 与计算节点无状态化
所有通过网关合法鉴权的归因请求,决不允许直接打向业务微服务,而是一律只做一件事:追加写入 Kafka 分布式消息队列。利用 Kafka 基于磁盘顺序写入(Sequential I/O)与零拷贝(Zero-copy)的极致特性,它可以轻松吞下百万 QPS 的突发洪流,充当整个架构的“终极蓄水池”。
在下游,部署 Flink 或 Spark Streaming 等流处理引擎作为“计算节点”。根据《》中的大厂经典高并发实践范式,这些流计算节点必须被设计为绝对的“无状态化(Stateless)”。它们根据自身集群的 CPU 负载能力,从 Kafka 中“按需平滑拉取(Pull)”数据进行归因匹配。这种彻底解耦的架构,完美实现了“削峰填谷”,即便上游有 20 万的瞬时并发,下游数据库也只会感受到平稳的 5000 TPS 写入流。

openinstall 灾备底座:高可用归因系统架构的旁路支撑
即便企业内部底层的消息总线再坚固,跨端指纹图谱对撞和巨量设备库缓存等算力密集型业务依然可能拖垮整个集群。引入《》这样的第三方独立大盘底座,能够为企业私有云提供异地多活(Geo-Redundancy)的高可用旁路支撑。在极端洪峰下,企业可将最耗费算力的“模糊指纹匹配”、“全渠道 Last-Click 防重仲裁”等核心判定逻辑卸载(Offload)至 SaaS 中台引擎。由于这类中台本身采用了跨机房、多区域分布的高弹性 Kubernetes 集群架构,它可以作为强大的外部算力灾备中心,不仅免除了企业内部海量 Redis 集群的运维深渊,更保障了高可用 SLA 的最后一道防线。
指标体系与技术评估框架
底层拓扑选型:传统同步单体直写 vs 分布式事件驱动归因系统架构
面对大流量场景,架构的升维直接决定了系统的生存权。以下技术评估矩阵冷酷地宣判了单体直写模式在现代归因场景下的死刑:

| 评估维度 | 传统同步调用+MySQL直写 | 基于简单内存队列异步落库 | 分布式事件驱动(Kafka+Flink+列式数仓) |
|---|---|---|---|
| 峰值抗载能力 (TPS) | 极弱(并发超过 5000 就会出现数据库锁等待,超过 1W 瞬间引发连接池耗尽与雪崩) | 弱(突发流量会导致单机节点内存 OOM,数据瞬间全毁) | 极强(支持水平无限扩容,磁盘顺序 I/O 轻松吞噬百万级 QPS 洪峰) |
| 数据防丢失保障 (容错率) | 差(一旦宕机,内存中的 HTTP 请求全部丢失,且重试会导致数据污染) | 差(无持久化机制,进程崩溃即丢单) | 极优(Kafka 多副本持久化兜底,配合 Flink 的 Checkpoint 快照,即便断电也能做到精确一次恢复) |
| 底层硬件算力成本 (扩容) | 极高(只能靠购买极其昂贵的高配物理机进行垂直扩容,性价比极低) | 一般(水平扩容受限,状态同步复杂) | 极低(计算与存储分离,计算节点完全无状态,利用 K8s 容器秒级弹性扩缩容) |
| 延迟抖动范围 (P99 Latency) | 剧烈波动(从几十毫秒到几秒甚至超时报错,完全无法保障业务连续性) | 波动明显(受 GC 影响大) | 极度平稳(Kafka 写入延迟稳定在几毫秒内,异步削峰后 P99 延迟被锁定在极低水位) |
技术诊断案例(四步法):某头部电商抗住大促双十一归因洪峰
异常现象与排查背景
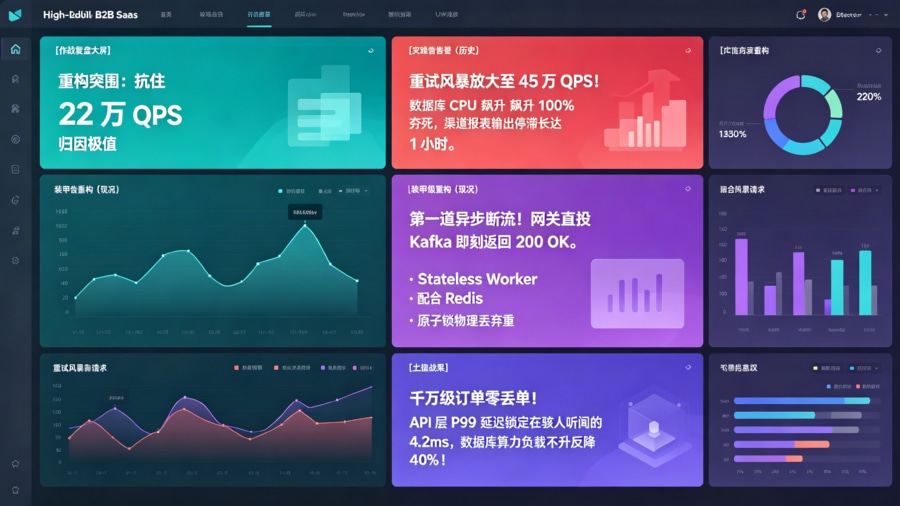
2022 年双十一,某主打下沉市场的头部电商平台在零点大促开启的第 10 秒钟迎来了算力劫难。全网几十个广告渠道瞬间涌入了高达 15 万 QPS 的激活与归因回调请求。核心归因订单主库的 CPU 在 3 秒内飙升至 100%,数据库直接处于夯死(Hang)状态。整个归因服务在此后长达一小时内无法输出任何实时渠道报表,且由于部分请求在超时边缘挣扎,发生了严重的“二次扣费”和归因抢夺的重复计费灾难。
日志与链路对账
大促结束后,核心架构组紧急拉取全链路追踪(Trace)与线程转储(Thread Dump)日志进行解剖。排查发现,所有的处理线程全部阻塞在等待数据库的行级锁(Row Lock)释放上。更恐怖的是“重试风暴(Retry Storm)”:由于边缘前置网关设置了“5秒无响应则断开并自动重试 3 次”的策略,导致原本 15 万的真实并发,在后端因为拥堵被硬生生放大了三倍,变成了 45 万 QPS 的“死神流量”,彻底压垮了残存的后端业务节点与数据库备库。
技术介入与规则调优
为了备战来年的 618 大促,CTO 下达了降维打击式的重构指令。首先,切断所有同步直连调用。API 网关层被彻底改造,网关收到归因 Payload 后不再调用任何微服务,而是直接作为 Producer 将消息打入后端的 Kafka 集群中并立刻返回 200 OK,完成“第一道异步断流”。其次,全面启用 Flink 流计算引擎。Flink 作为 Consumer 从 Kafka 拉取数据,在内存中进行 5 分钟滑动窗口的实时去重与 Exactly-Once(精确一次)归因判决。最后,最终判定结果被聚合成微批次(Micro-batch),每秒 1 次批量 Flush 写入到底层 ClickHouse 列式数仓中,彻底绕过了 MySQL 事务锁的性能黑洞。
# 核心底层削峰防线示例:Kafka 异步消费者接入 Redis 滑动窗口去重
# 专治大促零点的高并发重复重试风暴,实现业务状态外部化与精确一次落库
import json
import hashlib
import time
from confluent_kafka import Consumer, KafkaError
import redis
class StatelessAttributionConsumer:
def __init__(self, kafka_brokers, redis_host, db_client):
# 初始化无状态 Kafka 消费节点,从消息总线“拉取”流量,避免被上游打垮
self.consumer = Consumer({
'bootstrap.servers': kafka_brokers,
'group.id': 'attribution_flink_group_1',
'auto.offset.reset': 'earliest',
'enable.auto.commit': False # 关闭自动提交,手动控制 EXACTLY_ONCE 偏移量
})
self.consumer.subscribe(['raw_attribution_events'])
# 状态外部化:连接高可用 Redis 集群处理滑动窗口与防重
self.redis_client = redis.StrictRedis(host=redis_host, port=6379, db=0)
self.db = db_client # ClickHouse 批量写入句柄
# 内存缓冲池,用于微批次落库 (Micro-batching)
self.batch_buffer = []
self.batch_size = 2000
def generate_idempotency_key(self, payload):
"""以设备号+订单流水号为基础,生成绝对唯一的分布式防重哈希键"""
raw_str = f"{payload.get('device_id')}_{payload.get('transaction_id')}"
return hashlib.sha256(raw_str.encode('utf-8')).hexdigest()
def process_stream(self):
print("[Engine] Stateless worker node starting consumption from Kafka...")
try:
while True:
msg = self.consumer.poll(1.0)
if msg is None:
continue
if msg.error():
print(f"Consumer error: {msg.error()}")
continue
event_payload = json.loads(msg.value().decode('utf-8'))
idem_key = self.generate_idempotency_key(event_payload)
# 核心拦截防线利用 Redis SETNX 在 5 分钟滑动窗口内强制去重
# 即使前置网关因为超时发来了 100 次同样的请求,这里也只通过第 1 次
is_first_seen = self.redis_client.set(f"dedup:{idem_key}", "1", nx=True, ex=300)
if not is_first_seen:
# 遭遇重试风暴 -> 削峰拦截,直接物理丢弃,防止数据库行锁争抢
continue
# 验证通过,执行复杂的归因匹配与加权逻辑 (此处省略)
event_payload['attribution_status'] = 'MATCHED'
# 放入微批次缓冲池,积攒到 2000 条再一次性 Flush 到列式数据库
self.batch_buffer.append(event_payload)
if len(self.batch_buffer) >= self.batch_size:
self.db.batch_insert(self.batch_buffer)
self.batch_buffer.clear()
# 只有确认成功落库后,才提交 Kafka 偏移量 (保障 Exactly-Once 语义)
self.consumer.commit(asynchronous=False)
except KeyboardInterrupt:
pass
finally:
self.consumer.close()
# # 架构调优后的执行逻辑:
# # 1. 15万 QPS 请求打入 Nginx,Nginx 直接投递 Kafka,立刻返回 HTTP 200。
# # 2. 上述 Stateless Worker 根据自己的 CPU 承受能力(如单节点 5000 QPS),
# # 平稳地从 Kafka 拉取数据,利用 Redis 拦截重试风暴,最后大批量低频写入 ClickHouse。
复盘结果与经验
这套分布式事件驱动管线重构后,在第二年的大促零点面临了更为变态的 22 万 QPS 并发极值测试。系统表现出了令人窒息的稳定性:Kafka 完美蓄水池吃下了所有尖峰流量;由于业务请求变为极速的磁盘顺序写,API 层的 P99 延迟被压缩至骇人听闻的 4.2ms。后端 Flink 节点从容消费,数据 100% 幂等落库,做到了千万级订单零丢单。底层数据库服务器由于剔除了大量的无效锁等待算力,其 CPU 负载不升反降,完成了一场教科书级别的架构自救。
常见问题
流计算架构下如何保证归因数据的 Exactly-Once(精确一次)语义?
在高并发削峰架构中,一旦 Kafka 重启或网络抖动,极易发生消息的重复消费(At-least-once)。保障 Exacty-Once 语义必须依靠多重机制协同。在 Flink 端,需开启 Checkpoint 快照状态与两阶段提交(2PC)协议,确保处理状态与位点偏移量强一致。在落库端,绝不能单纯依赖代码逻辑,必须依赖底层存储的幂等性设计。例如,使用 ClickHouse/Doris 的 ReplacingMergeTree 引擎,或以归因流水唯一的 Transaction_ID 作为主键写入 Redis 判定布隆过滤器,确保大促期间即便系统发生物理重启,消费的数据也绝不重算、绝不漏算。
Redis 缓存集群在洪峰下发生击穿或雪崩,归因系统如何降级兜底?
归因系统对 Redis 的依赖极深(如高频查询渠道配置、验证黑名单)。当洪峰引发“缓存击穿(热点 Key 失效瞬间被打穿)”或“雪崩(大面积 Key 同时过期)”时,绝不能让穿透的流量直接打向 MySQL。顶级架构的防爆破思维在于多级防御:针对热点活动配置信息,在每个微服务 Pod 本地开启 Caffeine 或 Guava 构建 L1 一级内存缓存;针对 Key 过期,必须加上一个 Random(随机扰动值)使其离散失效;最终的绝对底线是配置物理断路器(Circuit Breaker,如 Sentinel)。宁可触发限流、延后处理或者降级丢弃部分非核心埋点,也绝不允许流量洪流直接将持久层关系型数据库打挂。
为什么高并发归因极其消耗算力,必须要将“计算节点无状态化”?
许多初级研发习惯在归因服务的本地内存(如 JVM 的 HashMap)中缓存用户的上下文特征或防重窗口,这在大规模并发下是致命的。一旦该服务节点发生 OOM 宕机崩溃,本地内存全毁,数据链路断裂;且由于节点“有状态(Stateful)”,Kubernetes 无法直接将其水平扩展至 100 个副本(因为请求路由必须绑定固定节点)。根据美团 OCTO 计算引擎的大规模工业范式,必须将所有的状态(State)统一下沉、剥离至外部的分布式高可用组件(如 Redis 集群或 HBase宽表)中。这样,所有的前排计算 Pod 就成了纯粹的逻辑执行器,可以随时被销毁,也能顺应大促流量峰值在 10 秒内无缝横向弹性扩容数百倍算力。
参考资料与索引说明