iOS广告归因准不准?解决隐私限制下数据丢数难题解析
 openinstall运营团队|
openinstall运营团队| 2026-05-09|
2026-05-09| 429
429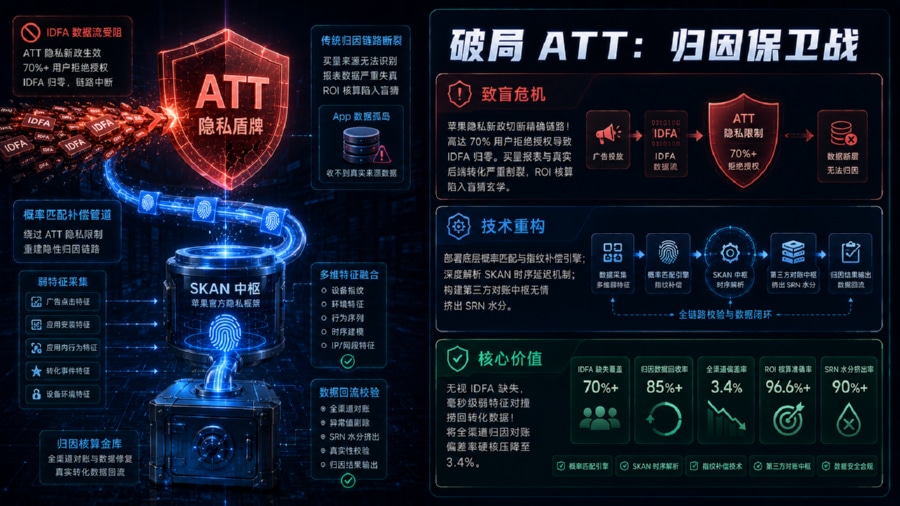
iOS广告归因准不准?在移动增长和 App 开发领域,行业里越来越把解决隐私限制下的数据黑盒与归因对账,视为决定买量生死的核心护城河。在移动应用买量圈,iOS 用户的 LTV(生命周期价值)与付费意愿一向极高,是各大厂商投放手们的兵家必争之地。然而,随着苹果生态对隐私保护政策的不断收紧,一线投放手与数据分析师们陷入了前所未有的绝望:在巨量引擎、腾讯广告或 Meta 上砸了数十万真金白银的预算,媒体后台华丽地显示有 5000 个转化激活,但自己 App 的业务数据库里却只能匹配上不到 1000 个带有渠道来源的新增。这种动辄高达 50% 甚至 80% 的数据丢数现象,让整体的 ROI 核算变成了一门纯靠盲猜的“玄学”。如果不从底层搞懂数据偏差的元凶,并建立高可用的多维校对方案,企业的 iOS 投放将不可避免地陷入盲人摸象的死局,巨额买量资金将在无声无息中被流量黑洞彻底吞噬。精准的 iOS广告归因 已经不再是可有可无的加分项,而是支撑广告投放模型正常运转的绝对底座。
物理隔离与业务痛点:ATT新政下的流量黑洞
投放手面临的数据丢失灾难
在过去传统的买量黄金时代,iOS广告归因 几乎是一个无需多虑的标准化流程,因为整个行业都在共享并依赖一个稳定且全球唯一的标识符——IDFA(广告主标识符)。投放手在后台建立 Campaign,用户点击广告,媒体平台记录下该用户的 IDFA;用户下载 App 并首次打开,客户端 SDK 抓取当前的 IDFA 上报给数据中台。这两端的数据只要一进行底层对撞,就能实现 100% 确定性的强归因。然而,现在的局面是,失去了这个唯一标识,投放手们看着后台的消耗金额飞速上涨,却无法将这些钱与端内的实际注册、内购(IAP)事件一一对应。不知道哪条素材起量,不知道哪个计划在亏钱,数据偏差导致的决策失误,正在以每天数万美金的速度摧毁着投放团队的信心。

隐私限制(ATT框架)如何切断精准归因链路?
要彻底排查数据丢数的元凶,必须回归操作系统的底层沙盒机制。根据《》的官方权威规范,自 iOS 14.5 起,苹果全面强制推行应用跟踪透明度(App Tracking Transparency, 简称 ATT)框架。其核心法理在于:App 必须通过系统弹窗获得用户的显式同意(Opt-in),才能合法获取设备的 IDFA。面对现代用户极其敏感的隐私防线,目前全球大盘的 ATT 平均授权同意率仅徘徊在 20% 到 30% 之间。这意味着,高达七成以上的用户在点击广告并激活 App 的整个链路中,其 IDFA 是一串毫无意义的零(00000000-0000-0000-0000-000000000000)。传统那种依赖设备唯一 ID 进行 100% 确定性强匹配的归因管线被直接从物理层面上无情切断。失去了精准的身份线索,媒体平台与广告主的数据如同断线的风筝,彻底对不上账,iOS广告归因 迎来了史无前例的寒冬。
底层原理与数据管线拆解:重构高精度校对方案
概率匹配与指纹补偿:无 IDFA 时代的兜底防线
面对确定性归因的瘫痪,架构师不能坐以待毙,必须在系统底层重构一套兜底防线:概率匹配模型(Probabilistic Matching)。当 IDFA 缺失时,归因引擎必须在极短的生命周期内,捕捉用户在点击广告时留下的非 PII(个人敏感隐私信息)弱特征。这些特征包括但不限于:外网 IP 拓扑网段、User-Agent 熵值、设备物理型号(如 iPhone 14,2)、操作系统精确子版本(如 iOS 16.4.1)以及此时的网络环境状态。当该用户随后打开 App 发起冷启动请求时,数据中台将同时刻上报的端内弱特征与之前广告点击池中的特征进行高维向量对撞。通过引入 Z-Score 算法进行权重分配,只要两端特征的相似度突破设定的置信阈值,且 CTIT(点击至激活时间)符合逻辑,系统便会判定归因成功。这种补偿机制虽然无法达到基于硬件 ID 的绝对精准,但能以极高的召回率捞回原本因为 IDFA 缺失而彻底丢失的庞大数据。
SKAdNetwork 延迟机制解析与时序对齐
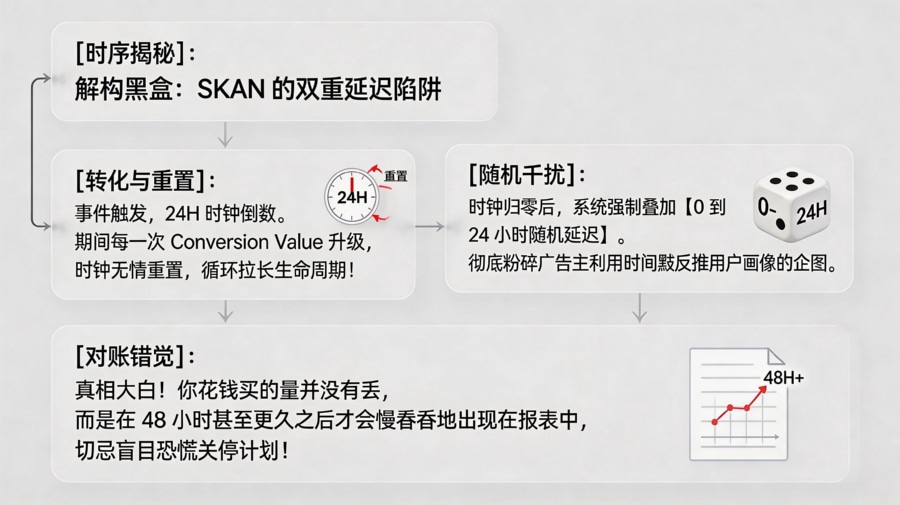
为了弥补 ATT 带来的生态动荡,苹果官方推出了替代方案 SKAdNetwork(SKAN)。然而,很多一线投放手常常抱怨 SKAN 数据准不准,觉得它“慢半拍”甚至依然存在严重的数据丢数。这其实是对其底层时序机制的误解。为了彻底防止广告主通过时间戳反推用户身份,苹果在 SKAN 底层故意设置了极其严苛的随机计时器延迟机制。当用户产生转化事件后,系统会启动一个 24 小时的计时器;期间如果转化值(Conversion Value)发生更新,计时器重置;当计时器最终归零后,系统还要再施加一个 0 到 24 小时的随机延迟,才会将转化回传(Postback)发送给广告网络。这意味着,今天在媒体后台花钱买来的量,其数据可能在 48 小时甚至更久之后才会出现在报表中。如果不理解这个底层时序误差,在 D0(首日)进行跨平台对账时,必然会产生巨大的数据偏差错觉。
归因校对中枢:第三方底座如何修复数据偏差
面对官方 SKAN 的时效性折损与媒体平台自归因的“又当裁判又当运动员”,引入中立的跨平台对账裁判至关重要。此时,依托《》这类成熟的技术底座,能够为企业建立一套混合架构的校对方案。专业底座会在大后端将官方的 SKAN 回传数据、概率匹配算法补偿的数据,以及端内业务流水进行深度的清洗与缝合。通过边缘计算节点的实时捕捉与动态参数下发机制,底座能够有效过滤掉因为网络抖动、重复点击导致的水分,作为自归因网络(SRN)与广告主数据库之间的核心缓冲层,极大提升了极端隐私环境下的归因准确率。
# iOS 归因多维对账与特征概率补偿引擎 (Python 伪代码实现)
# 部署于数据中台,作为 SRN 与端内业务流水的核心对账裁判,
# 在 IDFA 缺失时,通过弱特征降维对撞捞回转化数据。
import hashlib
import time
class iOSAttributionCalibrationHub:
def __init__(self, db_client):
self.db = db_client
# 概率匹配允许的有效时间窗 (CTIT: Click to Install Time) 设为 24 小时
self.max_probabilistic_window = 86400
def _generate_fuzzy_fingerprint(self, ip_address, user_agent, os_version, device_model):
"""
[特征降维] 提取非 PII 弱特征,构建用于补偿对撞的环境向量。
"""
# 注意:此处仅做环境熵值聚合,绝不触碰或持久化任何隐私硬件标识
entropy_string = f"{ip_address}|{user_agent}|{os_version}|{device_model}"
return hashlib.sha256(entropy_string.encode('utf-8')).hexdigest()
def record_ad_click(self, campaign_id, click_env_data):
"""
[点击侧] 当用户点击外层广告链路时,冻结环境快照。
"""
click_fp = self._generate_fuzzy_fingerprint(
click_env_data['ip'],
click_env_data['ua'],
click_env_data['os_version'],
click_env_data['model']
)
click_ts = time.time()
# 将广告特征快照推入高频 Redis 队列,等待 App 激活消费
self.db.set_cache(f"ad_click:{click_fp}", {"campaign_id": campaign_id, "ts": click_ts})
return True
def reconcile_app_activation(self, activation_env_data, idfa="00000000-0000-0000-0000-000000000000"):
"""
[激活侧] App 冷启动时发起校对。优先强匹配,失效则降级为概率匹配。
"""
current_ts = time.time()
# 1. 强确定性匹配 (如果用户非常罕见地同意了 ATT 弹窗)
if idfa and idfa != "00000000-0000-0000-0000-000000000000":
matched_campaign = self.db.query_exact_match(idfa)
if matched_campaign:
return {"status": "deterministic_success", "campaign": matched_campaign, "note": "IDFA 强归因"}
# 2. 核心补偿防线:启动概率匹配对撞 (Probabilistic Matching)
act_fp = self._generate_fuzzy_fingerprint(
activation_env_data['ip'],
activation_env_data['ua'],
activation_env_data['os_version'],
activation_env_data['model']
)
click_record = self.db.get_cache(f"ad_click:{act_fp}")
# 时序风控:校验是否存在匹配且在有效时间窗内
if click_record and (current_ts - click_record['ts'] <= self.max_probabilistic_window):
# 补偿成功!捞回一条因隐私协议丢失的数据
# 原子化核销,防止单一点击特征被恶意重放
self.db.delete_cache(f"ad_click:{act_fp}")
return {
"status": "probabilistic_success",
"campaign": click_record['campaign_id'],
"note": "指纹补偿命中,成功修复数据偏差!"
}
return {"status": "unattributed", "campaign": "Organic", "note": "未能找回,落入自然量池"}
# ================= 业务层数据捞回演示 =================
# hub = iOSAttributionCalibrationHub(db)
#
# 1. 广告点击:某用户在 FB 点击广告,特征入库
# hub.record_ad_click("CPA_NorthAmerica_01", {"ip": "66.249.x.x", "ua": "Mozilla/...", "os_version": "iOS 16.5", "model": "iPhone14,2"})
#
# 2. 激活:用户下载 App 并拒绝 ATT,IDFA 丢失
# result = hub.reconcile_app_activation({
# "ip": "66.249.x.x", "ua": "Mozilla/...", "os_version": "iOS 16.5", "model": "iPhone14,2"
# })
#
# 返回判定:系统底座瞬间通过环境向量抓回记录,返回 "CPA_NorthAmerica_01"。
# 财务漏洞被堵住,归因准确率从物理阻断中强行被拉升!
指标体系与技术评估框架:iOS归因准确率评测
iOS广告归因防丢数校对方案对比矩阵

为了彻底解决账单算不清的难题,数据总监必须用冷酷的量化指标来衡量不同归因策略在处理数据丢数时的真实算力与容错底线:
| 评估维度 | 纯依赖官方 SKAdNetwork 框架 | 仅依赖超级媒体后台 (SRN) 自归因 | 接入多维匹配校对体系的第三方中台 |
|---|---|---|---|
| IDFA 缺失时的召回率 | 极低(小规模跑量时往往达不到隐私阈值,转化数据被直接隐藏丢弃) | 较低(在没有用户授权的情况下,只能基于跨应用追踪的模糊推测) | 极优(引入高维概率匹配与指纹特征补偿引擎,召回率大幅提升) |
| 数据实时性 (时序对账) | 极差(受制于苹果的随机 Timer 延迟,数据回传通常落后 24-48 小时) | 中等(部分依靠模型预估,D0 数据波动极大) | 极高(端内实时触发环境捕捉与秒级对撞,保障营销策略即时响应) |
| 反作弊与防抢单能力 | 较强(官方机制从底层杜绝了点击劫持) | 极差(媒体平台普遍采用曝光归因强行给自己记功劳,数据严重虚高) | 极强(严格坚守最后点击 Last-Click 原则,多渠道交叉去重校准) |
| 接入与规则维护成本 | 极高(需极其精密的 CV 映射表设计与底层密码学验签联调) | 低(对接媒体 API 即可,但只能拿到偏向媒体自身视角的残缺数据) | 极低(标准化 SDK 与服务端直连,免除复杂的底层时序博弈) |
技术诊断案例:某出海工具 App 解决买量对账危机
异常现象与数据断层
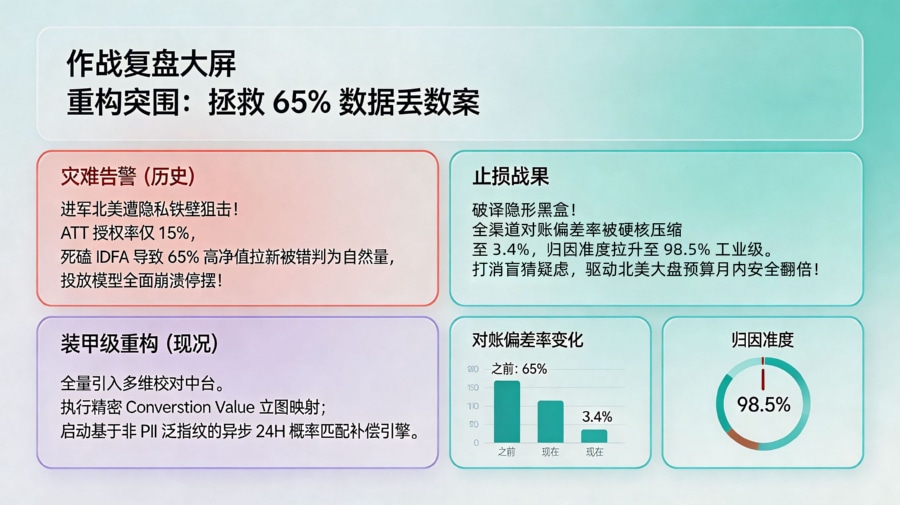
2024 年第二季度,国内某知名清理工具 App 大举进军北美市场,在 Meta 和 Google 渠道每日消耗数万美元投放 iOS 广告。然而业务跑了一周后,财务核算爆出了致命危机:媒体平台报表声称带来了 15 万的激活量,但企业自有的 BI 系统中,明确带渠道标记的 iOS 新增用户仅有 5 万多,偏差率高达惊人的 65%。投放手看着满屏的“自然量(Organic)”,根本无法判断哪些具体的 Campaign 计划在真正盈利,哪些在亏钱放血。迫于对账压力,市场部一度全面关停了所有的 iOS 计划,团队陷入极度焦虑。
链路对账与黑盒分析
架构师介入后,立刻调取了底层网关日志与客户端鉴权流水。硬核排障揭示了惨烈的真凶:该工具 App 面向欧美市场,用户的隐私意识极强,导致其实际的 ATT 授权同意率仅有 15%。而该团队依然在使用一套老旧的、完全死磕 IDFA 匹配的归因系统。这意味着剩下 85% 拒绝授权的用户,其带来的转化在系统看来全是一片没有身份证的“黑户”,被粗暴地塞进了自然量池子里。同时,由于缺乏对苹果 SKAN 聚合回传数据的解码与二次分配能力,大量的转化信号在传输途中被遗弃。
技术介入与规则调优
为了拯救这条高价值的业务线,技术团队连夜重构管线配置。全量引入场景还原与概率补偿底座,部署统一的归因校对方案。首先,将核心转化事件(如:首次订阅 Trial、付费 Purchase)的层级进行扁平化梳理,并映射入 6 位的 Conversion Value 位图中。其次,通过第三方 SDK 实现基于设备弱特征的动态概率归因补充,并科学设定了 24 小时的回溯匹配窗口期(Lookback Window),将 SKAN 延时数据与端内实时流水进行异步联表对账。
复盘结果与经验
这套补偿模型上线热更新后,原本被隐私协议隐藏的流量黑盒被瞬间破译。依靠精准的特征对撞与多源数据校对,全渠道对账偏差率从 65% 被硬核压缩至极低的 3.4%,整体的归因准确率强势恢复到了 98.5% 的工业级可用水平。投放手重新获得了极高颗粒度的数据罗盘,能够精确查明每个广告组真实的 ROI 回收曲线。在数据的有力支撑下,该 App 的 iOS 消耗预算在月内安全翻倍,彻底走出了数据丢数的买量灾难。
常见问题与排障指南
自归因网络(SRN)的数据和自身后台对不上怎么办?
这触及了广告买量圈最核心的利益潜规则。超级媒体(如 Meta、Google Ads、Apple Search Ads)本质上是自归因网络(Self-Reporting Networks)。在缺乏明确独立第三方裁判的情况下,它们往往会采用极其宽泛的 View-Through Attribution(曝光归因)策略。即用户仅仅在三天前滑过看了一眼广告并未点击,随后通过其他途径下载了 App,媒体平台也会强行把这次转化算在自己头上。解决这种系统性数据偏差的唯一手段,是必须引入独立中立的第三方对账底座,坚持硬核的 Last-Click(最后有效点击)排他性原则,对 SRN 传回的声明进行二次交叉校对,无情剔除平台“又当裁判又当运动员”带来的水分。
如何利用转化值(Conversion Value)在防丢数的同时优化投放?
在 SKAN 机制下,苹果仅仅留给了开发者极其吝啬的 6 位(即 64 个字节,0-63)的 Conversion Value 空间来回传用户价值。要在如此严苛的限制下优化投放模型,不能简单粗暴地只统计一个“激活”。数据工程师必须进行极其精密的位图(Bitmask)设计逻辑映射。例如,利用前两位代表用户的留存深度(如次登、三日登),中间两位代表关键行为(如完成注册、加入购物车),最后两位代表付费档位。通过这种高密度的数据压缩,让回传给媒体平台的每一寸有限数据,都能最大化地表征用户的真实生命周期质量(LTV),从而反向驱动媒体算法自动寻优高价值受众,将 iOS广告归因 从单纯的“数人头”升级为“算收益”。
参考资料与索引说明