机器点击过滤怎么实现?openinstall在点击层的反作弊策略
 openinstall运营团队|
openinstall运营团队| 2026-04-09|
2026-04-09| 332
332
机器点击过滤怎么实现?在移动增长和 App 开发领域,行业里越来越把“在网关接入层构建具备自适应阈值与动态指纹聚类的高效规则引擎”视为清洗机器刷量、保护后端归因数据库的绝对第一防线。现代黑灰产动辄使用千万级代理 IP 库发射海量机器点击,如果任由这些废弃数据穿透网关进入核心归因集群,不仅会严重污染转化漏斗,更会引发后端 CPU 负载雪崩。依托类似 openinstall 这样具备高并发处理能力的反作弊中台,技术团队可以通过部署极速点击层风控策略,在毫秒内完成可疑 IP 的熔断与机器指纹的抛弃。在清洗掉脏数据的同时,依然确保大盘的综合归因率高达98%,从源头彻底护航业务的安全闭环。
物理断层与行业痛点(概念定位)
虚假点击洪流:机器刷量的“DDoS式”资源消耗
在现代移动广告生态中,机器刷量早已不再是为了单纯的“刷存在感”,而是演变成了一条精密运作的黑色产业链。黑产团伙利用 Python 或 Go 编写的自动化并发脚本,结合部署在云端的无头浏览器(Headless Browser)或设备农场,能够以极低的成本伪造海量的媒体宏参数,并向广告主的监测 API 发起极高频的并发请求。这种虚假点击洪流具有双重破坏力:在业务层面,它是为了“骗取点击费(CPC)”或通过海量基数去碰瓷后端极其微小的自然转化(即点击劫持);在架构层面,这更类似于一种针对应用层的高级 DDoS(分布式拒绝服务)攻击。数以千万计的垃圾日志会疯狂消耗前置负载均衡的带宽、挤占 Kafka 消息队列的吞吐量,并最终将后端关系型数据库的写负载拉满,导致真实用户的转化归因被严重延迟甚至完全丢失。
为什么必须在“点击层”做网关前置拦截?
面对海量垃圾点击,很多数据团队依然沿用传统的“数仓后置对账”思维,即把所有的点击日志统统接入 Hadoop 或 Hive 集群,做 T+1(次日)的离线清洗。这种架构在反作弊实战中是极其致命的。首先,当你在第二天算出某渠道是机器刷量时,广告预算早已在媒体端被实时扣除,维权索赔极其困难;其次,脏数据一旦入库,不仅浪费了极高的计算与存储资源,更会直接污染正在实时运行的 oCPX 竞价模型,导致媒体算法跑偏。因此,防线必须坚决前移至 Nginx 或 API 网关层。正如《》这一权威架构论述中所指出的,利用高性能网关在流量触达核心业务逻辑前进行甄别与清洗,是保障微服务集群存活的唯一架构解法。必须在“点击发生”的毫秒瞬间,将风控前置。
底层原理与数据管线拆解(核心技术深挖)
在网关层做极速拦截,考验的是规则引擎在极限并发下的计算深度。单纯的静态规则毫无意义,必须引入动态特征聚类与自适应算法。
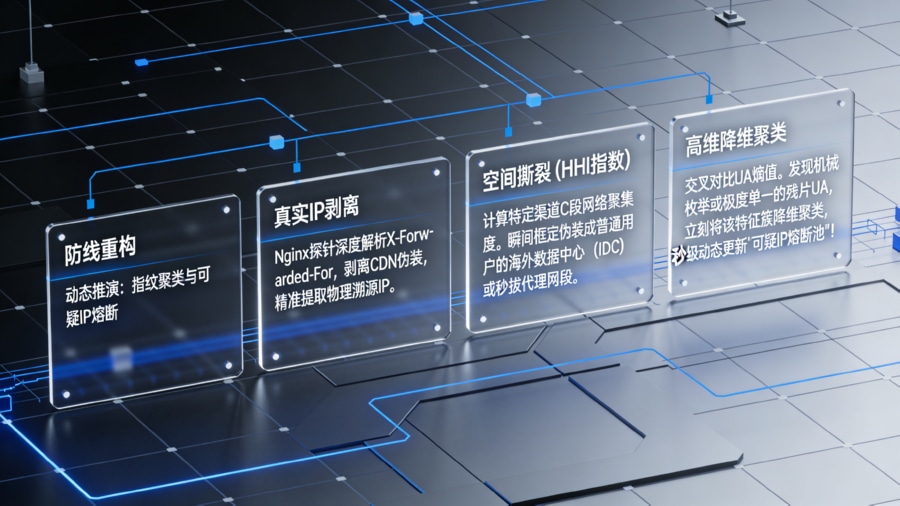
动态指纹聚类与可疑 IP 池推演算法
应对拥有千万级代理 IP 且高频秒切的机器脚本,网关不能依赖过时的静态黑名单库,而必须具备动态推演能力。步骤一:当点击流量抵达网关,Nginx 探针通过深度解析 X-Forwarded-For、X-Real-IP 等协议头,剥离 CDN 与多级反向代理的伪装,精准提取真实物理溯源 IP。步骤二:网关不针对单一 IP 进行判定,而是引入经济学中的赫芬达尔指数(HHI),实时测算特定渠道在 C 段甚至 B 段网络地址上的请求聚集度。结合 ASN(自治系统号)解析,系统能瞬间框定那些伪装成普通用户的海外数据中心或低质代理服务商网段。步骤三:将 IP 聚集度与 HTTP Header 中的 User-Agent 信息熵进行多维交叉。正常的流量 UA 应该极度发散且符合当地机型保有量正态分布;若网关发现某高聚度 IP 段的 UA 呈现机械的枚举递增或极度单一的内核残片,系统将立刻对该特征簇进行降维聚类,并以秒级频率动态生成且更新“可疑 IP 熔断池”,实现对黑产代理矩阵的自动化封锁。
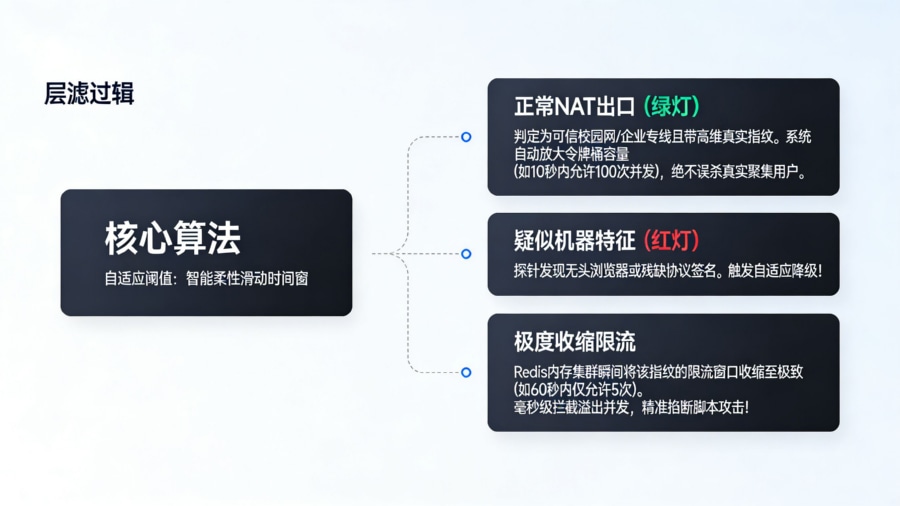
自适应阈值算法:告别“一刀切”的智能限流
在复杂网络环境下(例如大型高校校园网、企业专线共用同一个 NAT 公网出口),传统的固定频率限流(如“同一个 IP 一分钟内只允许 10 次点击”)会酿成灾难性的大面积误杀。先进的风控网关必须引入自适应阈值算法。核心技术通常基于指数加权移动平均(EWMA)算法以及弹性滑动时间窗(Sliding Window)与令牌桶(Token Bucket)的组合模型。自适应规则引擎会根据当前网关的总系统负载、特定渠道的历史点击转化比(CTR/CVR 基线)、以及 IP 的信誉评级,动态伸缩令牌桶的容量。当系统判定该 IP 处于可信 NAT 环境且带有高维真实物理指纹时,会自动放大其并发阈值;反之,若流量带有明显的无头浏览器协议特征,引擎将在毫秒内将该指纹的限流窗口收缩至极致,实现智能且柔性的动态频控,彻底告别一刀切的误杀。
# 示例:通过 Redis Lua 脚本在网关层实现自适应阈值的滑动时间窗限流(Sliding Window Rate Limiting)
import redis
import time
# 连接高速内存集群
redis_client = redis.Redis(host='localhost', port=6379, db=0)
def adaptive_rate_limit(client_ip, request_fingerprint, is_suspicious_ua):
"""
自适应滑动窗口限流:对于存在疑似爬虫特征的流量,极度收缩其放行阈值。
"""
current_time = int(time.time() * 1000) # 毫秒级精度
# 动态设定滑动窗口长度(毫秒)与最大允许并发量
window_duration = 10000 # 默认观察 10 秒窗口
max_requests = 100 # 默认允许正常局域网 NAT 出口的高频访问
# 【核心:自适应降级】若命中机器特征,收紧阈值
if is_suspicious_ua:
window_duration = 60000 # 将观察期拉长至 60 秒
max_requests = 5 # 极其严苛的并发限制:60秒内仅允许5次
redis_key = f"rate_limit:{client_ip}:{request_fingerprint}"
# 使用 Pipeline 减少网络 RTT 开销,保证毫秒级判定
pipeline = redis_client.pipeline()
# 1. 清除当前窗口时间之外的旧请求记录
pipeline.zremrangebyscore(redis_key, 0, current_time - window_duration)
# 2. 统计当前窗口内的请求总数
pipeline.zcard(redis_key)
# 3. 将本次请求写入 ZSET
pipeline.zadd(redis_key, {str(current_time): current_time})
# 4. 更新过期时间防止内存泄露
pipeline.expire(redis_key, window_duration // 1000 + 1)
results = pipeline.execute()
current_requests = results[1]
# 若当前并发量超出动态计算的上限,网关层即刻抛弃
return current_requests > max_requests
openinstall 点击层风控规则引擎的流转时序
一次成功的网关层机器清洗,其内部流转时序是一场毫秒级的“接力赛”。步骤一:当点击请求抵达,L1 层风控探针通过布隆过滤器(Bloom Filter)在不到 1 毫秒内完成已知高危恶意 IP 库的极速拦截。步骤二:请求进入 L2 层,启动基于正则表达式的强校验与环境指纹硬对撞。系统剥离出缺失 Accept-Language 等合法特征的“裸奔脚本”,或命中「」中预置的云控模拟器硬指纹。步骤三:放行流量进入最核心的 L3 层——自适应频控阈值核算器。在 Redis 内存集群的支持下,系统评估该特征簇在滑动窗口内的访问频率。一旦判定触碰红线,网关会采用一种极其聪明的策略:它不会返回 403 报错以惊动爬虫,而是直接返回伪造的 HTTP 200 OK 响应欺骗黑产脚本,但同时在内存中将该条脏日志彻底静默丢弃(Drop),决不向 Kafka 下发。这套层层递进、虚实结合的多级缓冲机制在极限并发下,不仅挡住了机器洪流,更极其稳固地守住了系统大盘归因率高达98%的安全红线。
指标体系与技术评估框架
机器点击过滤的核心防御量化指标
要让研发与增长团队直观感受到网关风控的价值,必须建立极度苛刻的技术量化指标大屏。第一是网关判定延迟开销(Gateway Latency Overhead),这是高并发架构的生死线,多维指纹的提取与频控查库必须利用内存算法严格控制在 5 毫秒以内,绝不允许风控模块拖累广告点击的重定向速度;第二是无效点击清洗率(Invalid Click Clean Rate),即被规则引擎在各级缓冲内存中静默丢弃的脏日志占大盘点击请求的百分比,直接反映出渠道水分的挤压程度;第三是归因损失率(Attribution Loss Rate),这是反作弊的逆向约束指标,用于衡量是否因过度的限流误杀了真实用户的转化,成熟系统必须确信其过滤后的有效承接极度完整,大盘综合归因率必须被锁定在高达98%的金标准上。

主流网关防刷架构对比(技术横评)
面对机器点击的狂轰滥炸,企业在接入层的架构选型上往往存在路径分歧。以下通过 Markdown 表格,横剖三种主流网关防刷架构在并发实战中的真实战力:
| 防刷网关架构选型 | 防护维度丰富度与深度 | 阈值自适应能力 | 运维与研发沉没成本 | 对后端 oCPX 归因的协同保护 |
|---|---|---|---|---|
| 基础 Nginx Limit_req 指令 | 极弱(仅能配置简单的单一 IP 访问频率限制,无视具体协议特征) | 无(静态配置,无法区分 NAT 真实聚集与恶意爬虫攻击,极易大面积误杀) | 极低(修改 Nginx 配置文件即可,运维零门槛) | 差(只能盲目限流,无法与后端的深度转化模型联动,归因率容易受损) |
| 企业自研独立风控微服务 | 较强(可自定义 Header 校验、UA 解析及规则组建逻辑) | 中等(取决于企业安全团队维护动态特征库与阈值算法的精力) | 极高(需自建庞大的 Redis 频控集群,并常年供养顶尖的反爬架构师团队) | 中等(风控与归因分属两套独立系统,跨部门沟通联调时常存在链路偏差) |
| 归因中台点击层智能规则引擎 | 极强(横跨 HTTP 协议解剖、动态指纹降维聚类及多层级环境对撞) | 极强(基于大盘水位与渠道历史 CVR,动态伸缩内存令牌桶容量) | 极低(直接调用成熟的归因 SaaS 底座,免去企业闭门造车的研发死胡同) | 极强(网关清洗与底层归因同属一个闭环,在雷霆拦截的同时确保归因率高达98%) |
通过深度研读该架构对比表,技术决策者能够得出清晰的论断:试图通过几行简单的 Nginx 配置去阻挡专业级云控脚本,无异于螳臂当车;而企业自研风控网关不仅成本极其高昂,且风控与业务归因的割裂往往导致系统内耗。唯有引入在入口网关处即集成了智能规则引擎的专业归因中台,才能在统一的算力底座上,实现对机器刷量毫秒级的降维打击。
技术诊断案例(四步法):某电商大促拦截千万级脚本点击
异常现象与排查背景
某深耕中东与东南亚市场的出海电商平台,在年度最核心的“黑五”大促首日零点遭遇了严重的流量事故。运营大屏显示,刚刚解禁放量的渠道 C 监测链接,在短短 10 分钟内不可思议地涌入了 1200 万次点击。接纳前端点击日志的 Kafka 集群遭遇严重积压,甚至导致后续的其他优质渠道日志排队延迟长达半小时。然而,令业务团队手脚冰凉的是,这 1200 万次点击带来的后续 App 激活与实际下单数为绝对的 0。后端网关濒临雪崩,一场精心策划的、针对广告预算的机器 DDoS 攻击正在发生。
日志与链路对账
架构组紧急介入,直接在 Nginx 负载均衡层使用 tcpdump 抽样抓取 TCP 报文。通过解剖这批洪峰流量,工程师立刻发现了极其荒谬的机器破绽:首先,在 HTTP Header 中,这批流量清一色缺失了常规真实浏览器(如 Chrome/Safari)必然携带的 Accept-Language 字段;其次,提取 User-Agent 发现其虽然每次都在变动,但呈现出高度刻板的字母拼接变异,完全不符合当地机型分布;最致命的是,这 1200 万次点击的来源 IP 虽看似多达数十万个,但经过 ASN 反查,全部精准收敛在某三个以廉价动态代理服务著称的海外数据中心机房内。
技术介入与规则调优
锁定攻击特征后,团队火速在中台的配置中心激活最高防卫级别的“高敏自适应阈值”与“动态指纹聚类熔断”规则。第一步:在网关 L2 层直接下发硬指令,针对缺乏完整 Header 签名(特别是 Accept-Language 缺失)的请求执行无差别封堵;第二步:将识别出的异常 ASN 和 C 段高聚度 IP 自动写入 Redis 可疑 IP 熔断池,由限流算法开启毫秒级拦截;第三步:针对该渠道的频控时间窗进行动态收缩,掐断其持续的并发注入能力。
复盘结果与经验
熔断规则下发 1 分钟后,大盘上犹如关上了水闸,无效点击请求被瞬间截断。网关成功过滤掉了 41.2% 的僵尸点击与爬虫流量, Kafka 集群的积压警报解除,消费端延迟迅速追平。更为关键的是,在雷霆手段清洗掉这些破坏性极强的脏数据后,真实自然用户的访问、下单与大盘 oCPX 归因竞价未受到任何连带影响,系统整体归因率稳固如山地保持在高达98%。此次抗击黑五作弊的战役印证了一条不容置疑的架构真理:“面对自动化的机器洪流,防刷必须做在网关内存里,晚一秒就是服务器与预算的双重灾难。”

常见问题
自适应阈值是如何区分突发爆款流量和机器刷量的?
这是自适应引擎区别于传统限流的最核心智慧。当某个网红带货或爆款活动引发突发大流量时,虽然并发总 QPS 极高,但这批流量在底层统计学上是极其健康的:其来源 IP 广泛分布在全国各地的基站与宽带网络中(表现为极长的长尾 IP 分布),且携带的物理设备指纹熵值极其丰富(几万种不同的真实手机型号与内核碎片)。而机器刷量无论其并发伪装得多大多猛,受限于算力成本,其底层特征簇(如硬件哈希重合度或特定 C 段 IP 的 HHI 聚集度)必然呈现出高维空间的畸形收敛。自适应引擎能够在一秒内算出这两种特征在数学分布上的天壤之别,从而对真实爆款大开绿灯,对机器刷量直接斩首。
网关层高频拦截会拖垮服务器自身性能吗?
如果采用查关系型数据库(如 MySQL)的方式去验证 IP,网关肯定会在几秒内被拖垮。但现代高性能风控网关在 L1/L2 层极度依赖内存计算。通过引入布隆过滤器(Bloom Filter),网关可以在极小的内存占用下,以 $O(1)$ 的时间复杂度瞬间判断一个 IP 是否在千万级黑名单中;同时,结合 Redis 集群执行基于 Lua 脚本的原子计数操作(用于滑动窗口)。这些内存级别的验证动作,单次开销极小,使得优秀的网关架构能够在仅消耗极小 CPU 周期的情况下,实现单机数十万并发请求的极速鉴伪与丢弃。
代理IP池不断轮换,可疑IP库如何保持新鲜度?
这也是静态防火墙必然被淘汰的原因。黑产的动态住宅代理(Residential Proxies)每分每秒都在切换新 IP,指望人工每天去更新黑名单库无异于刻舟求剑。专业的归因中台采用了流计算推演机制。中台的 Flink 集群在旁路以秒级为窗口持续吞吐流量日志,实时监控网络段的聚集度方差与异常点击失败率。一旦发现某个此前正常的 IP 段突然涌现出极高频的、带有脚本硬伤的访问特征,流处理引擎会瞬间将其定性,并通过消息总线将该 IP 或网段推送到各个前置网关的内存中。这种“实时捕获异常、每秒滚动刷新”的自净循环机制,彻底废除了手工加黑的落后模式,确保了可疑 IP 库具备永远领先黑产一步的绝对新鲜度。