全渠道统计如何搭建全渠道统计平台?底层数据管道构建
 openinstall运营团队|
openinstall运营团队| 2026-04-20|
2026-04-20| 147
147
如何搭建全渠道统计平台?在移动增长和 App 开发领域,行业里越来越把“基于流批一体数仓与跨端 ID 映射技术构建的底层数据管道”视为打破数据孤岛、实现统一归因与业财对账的终极核心基建。当集团业务线狂奔,每天的流量横跨 iOS App、安卓各大厂商应用商店、微信小程序矩阵以及成百上千家线下门店时,如果缺乏一套高维度的全渠道统计枢纽,口径打架与漏斗断层就会彻底拖垮商业智能(BI)系统的置信度。解决这一痛点,绝非简单地调用几个前台 API 接口,而是要在网关层、消息总线层以及分布式数仓层构建起具备极高容错率与幂等去重能力的物理管道。通过部署类似 openinstall 这样具备跨端缝合能力的中立技术底座,企业能够彻底终结多业务线各自为战的混沌状态,将海量异构数据的核算误差率死死压缩至 1.2% 的工业级红线以内。
物理断层与行业痛点(概念定位)
割裂的增长引擎:全渠道统计为何成为CTO的梦魇?
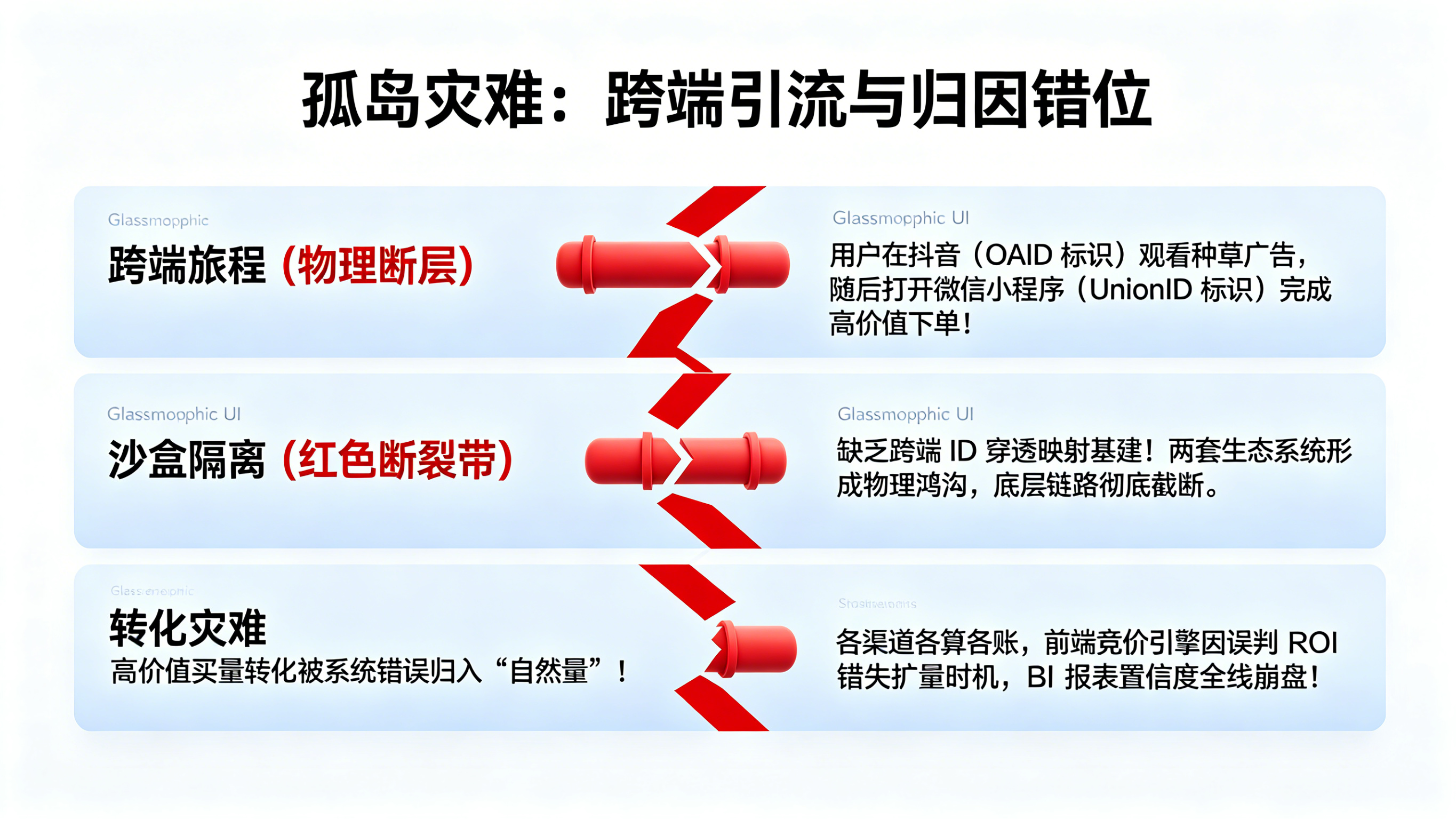
对于任何一家处于高速扩张期的企业而言,规划如何搭建全渠道统计平台往往是 CTO 面临的最棘手架构挑战。业务线跑得越快,系统内沉淀的数据就越像是一座座信息孤岛。市场部看的是抖音后台的激活数,运营部看的是微信私域的裂变 UV,而财务部只认最终落库的订单流水。这种“各个渠道各算各账、数据互相无法印证”的割裂状态,本质上是因为缺乏一个统一的指标中枢。在没有全渠道统计管道兜底的情况下,一旦大促期间出现跨平台引流(例如用户在抖音看了广告,却在微信小程序里完成了下单),因为链路截断,这笔高价值的转化将被错误地归入“自然量”,导致前端买量引擎因误判 ROI 而错失极其珍贵的扩量时机。
数据孤岛与多源异构的物理鸿沟
阻碍大一统报表形成的核心阻力,在于底层设备标识与操作系统生态之间无法逾越的物理鸿沟。在苹果 iOS 生态中,严苛的 ATT 隐私框架导致 IDFA 获取率暴跌;在 Android 阵营中,不同厂商的 OAID 机制碎片化极其严重;而在微信生态中,用户身份又被封装为了封闭的 UnionID 和 OpenID;如果再算上纯 Web 端 H5 的匿名 Cookie,这形成了庞大的多源异构灾难。简单的 BI 报表拼接根本无法在物理层面证明“昨晚用 iPad 看直播的游客”和“今天早晨用安卓手机充值的高级会员”是同一个物理自然人。跨越这道由沙盒机制与协议墙构筑的物理鸿沟,必须依靠底层链路的深度融合。
底层原理与数据管线拆解(核心重头戏)
数据流转拓扑设计:从多端探针采集到 ETL 中枢清洗
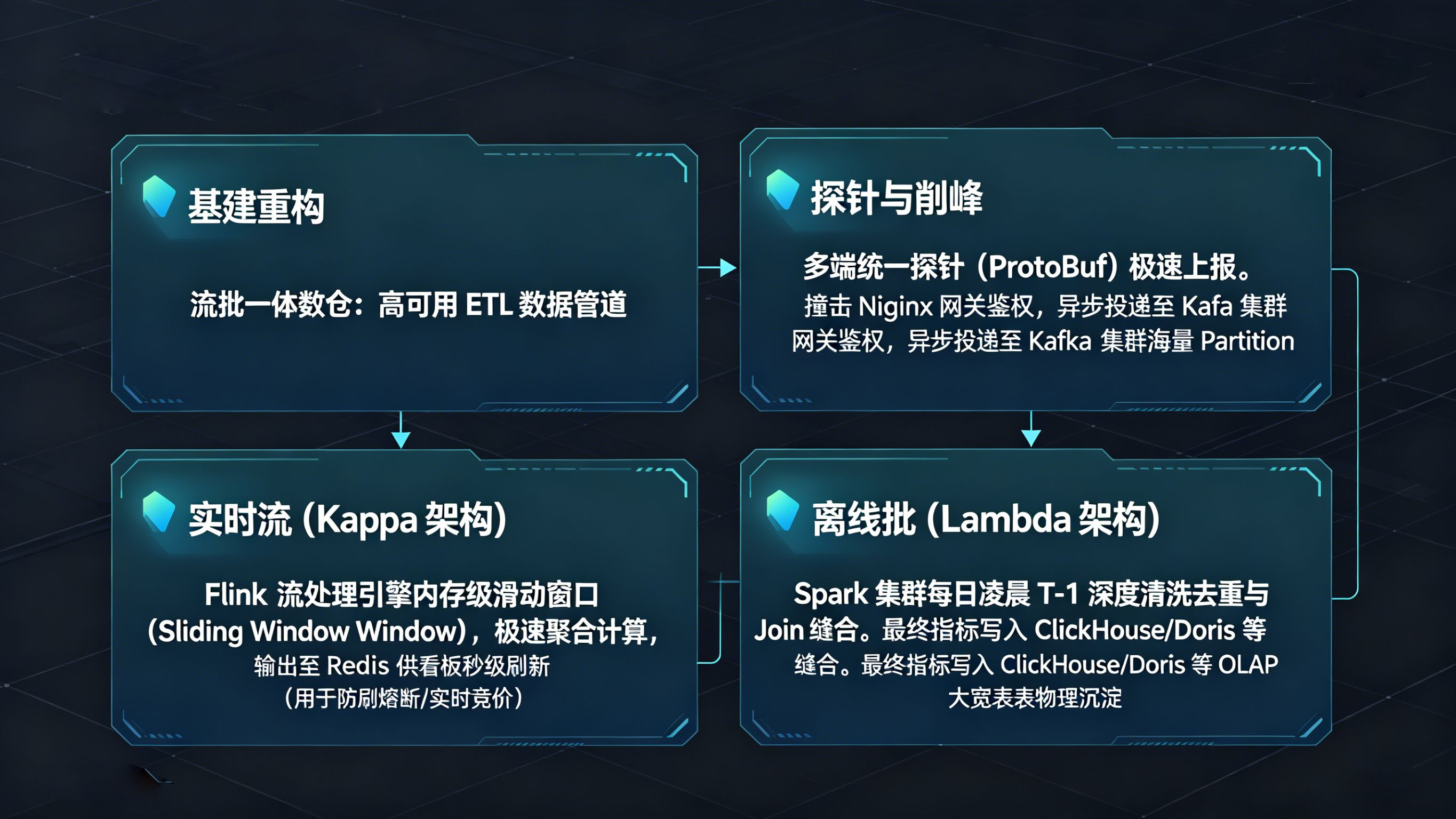
构建坚不可摧的全渠道统计平台,第一步是在边缘节点铺设极其严密的数据采集管线。步骤一:多端探针标准化布点。系统必须在 App 端原生 SDK、小程序 JS 探针以及后端服务器发起侧统一规范上报协议。为了追求极致的序列化效率与极小的网络带宽消耗,工业级方案通常废弃臃肿的 XML,全面采用 ProtoBuf(Protocol Buffers)或精简的 JSON Schema。步骤二:网关层高并发接入。探针采集到的事件流(如 https://app.openinstall.com/api/v2/event/report)首先撞击负载均衡集群,Nginx 网关在 5 毫秒内完成鉴权与 IP 防刷拦截。步骤三:Kafka 消息总线削峰填谷。面对双十一等大促夜瞬间飙升至百万 QPS 的上报狂潮,原始日志必须被异步投递至分布式 Kafka 集群中。通过合理划分 Topic 与海量的 Partition(分区),将不可控的业务峰值平滑转化为后端计算集群能够稳定吞吐的数据细流,这是 ETL(提取、转换、加载)清洗链路不崩溃的物理前提。
实时与离线双流管道:流批一体数仓的物理沉淀
当海量日志进入中心后,架构必须在“实时时效”与“历史绝对准确”之间取得完美平衡。步骤一:Flink 实时流切片。针对防作弊熔断、秒级 CPA 对账等对时效性要求极高的场景,系统走 Kappa 实时流架构,利用 Flink 在内存中开启极短的滑动窗口(Sliding Window),快速聚合计算并输出至 Redis 供前端看板秒级刷新。步骤二:Spark 离线批处理清洗。针对需要复杂归因回溯、长周期 LTV 计算的深度复盘,数据走 Lambda 离线批处理链路。每日凌晨,Spark 集群从 HDFS 中捞取全量 T-1 数据,进行跨渠道去重、脏数据剔除与深度 Join 缝合。步骤三:大宽表落库沉淀。最终清洗干净的指标被写入 ClickHouse 或 Doris 等 OLAP 列式数据库中。关于这一核心拓扑的最佳实践,顶尖架构师可深度参阅《》,其对于解决海量异构数据聚合、保障数据高可用流转的 MLOps 工程设计,为全渠道统计的存储底座提供了权威论证。
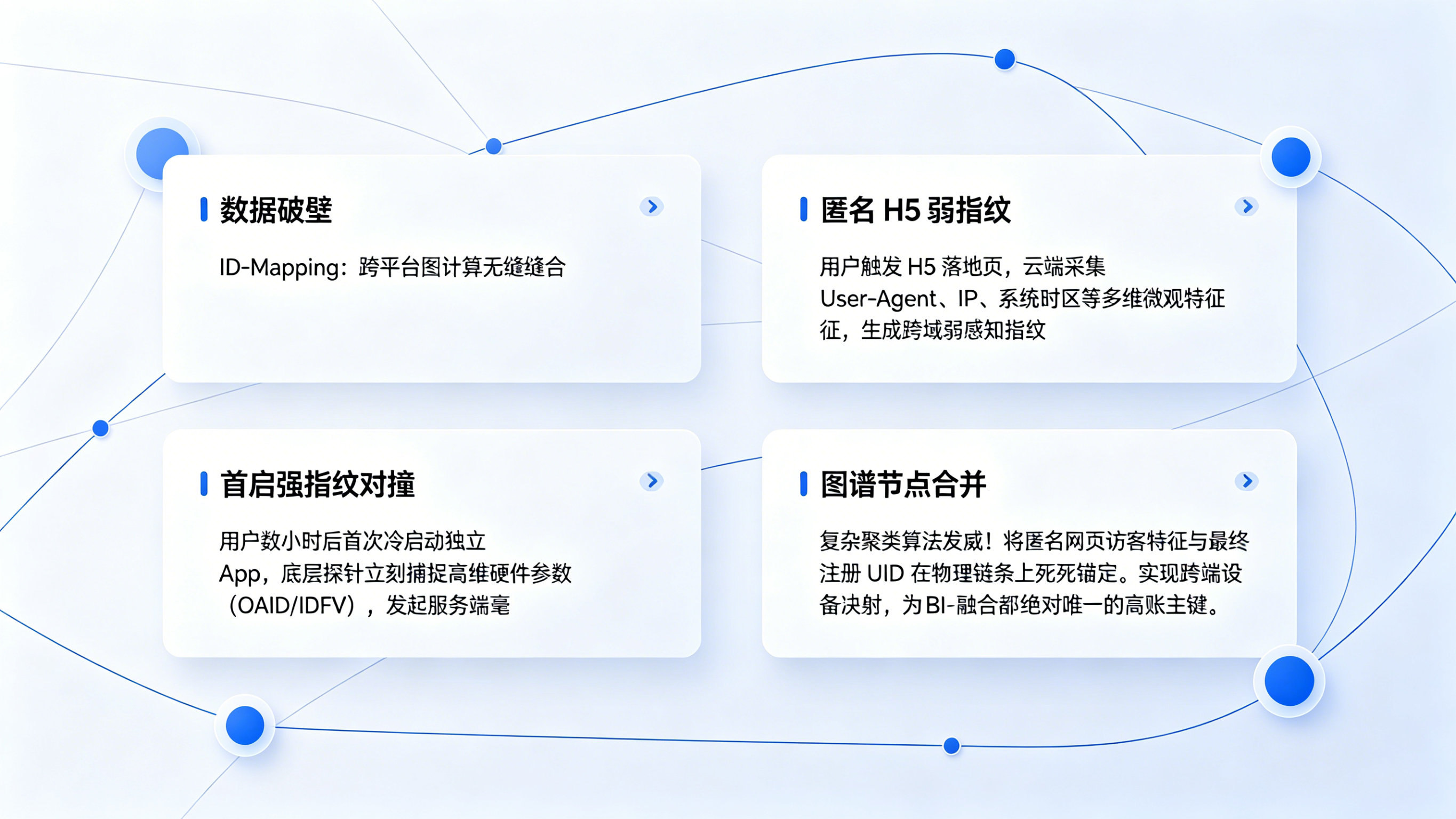
openinstall 全渠道统计底座:跨平台链路无缝缝合
如果缺乏硬核的设备映射算法,再强的存储集群也只是在堆砌废数据。依托《》这种成熟的中立基建,平台能够解决最棘手的 ID-Mapping(跨端设备指纹映射)难题。该底座在云端维护了一张庞大的图计算节点网,当用户在 H5 落地页触发点击时,系统会采集其浏览器 User-Agent、IP 地址、系统时区等多维微观特征生成弱感知指纹;当该用户数小时后在独立 App 内完成首次启动时,底层探针立刻捕捉其高维硬件参数,并在服务端进行毫秒级对撞。通过复杂的聚类算法,将匿名网页访客与最终的注册 UID 在物理链条上死死锚定,从而实现跨平台链路的无缝缝合,让 BI 融合有了绝对唯一的对账主键。
指标体系与技术评估框架
统计基建选型:内部纯自研拼凑 vs 一体化全渠道统计底座
面对割裂的数据,业务部门最容易犯的错误就是“用各种开源框架拼凑造轮子”。以下评估矩阵冷酷地揭露了这种粗放式自研的财务黑洞与算力短板:

| 评估维度 | 业务团队纯自研开源拼凑(Kafka+Hive自建) | 粗放式单渠道BI看板汇总 | 一体化中立全渠道统计底座 |
|---|---|---|---|
| 跨端 ID 穿透映射能力 | 极弱(缺乏全景图谱数据累积,只能做最简单的精准 ID 字符串比对,对于设备变更与跨微信环境无能为力) | 零(纯粹的数据报表物理搬运,各渠道依然是自说自话的信息孤岛) | 极强(依托亿级跨端设备活体特征快照库与动态参数拼接技术,实现多源异构环境下的精准图谱关联) |
| 流批一体研发算力成本 | 极高(需配置专属大数据研发团队,集群采购、中间件调优及 7*24 小时灾备排障的沉没成本深不见底) | 极低(仅使用前端可视化工具) | 极低(SaaS 化或私有化一键部署,免除繁重的底层高并发集群运维,CTO 零基建试错成本) |
| 多触点归因与 BI 融合时效 | 慢(每日 T+1 离线跑批极易出现时钟漂移故障,导致报表错位,无法支撑实时竞价调整) | 无(无法判定助攻渠道) | 极快(内置实时流计算引擎,分钟级输出跨域去重后的 MTA 归因报表,无缝对接企业内部数仓大屏) |
| 海量数据容错与防重率 | 较低(在面对弱网重传风暴时,极易因幂等性控制不佳导致底层数据膨胀与财务多计账) | 未知 | 极高(内置毫秒级 Redis 滑动窗口去重逻辑,确保百亿级吞吐下的绝对数据幂等) |
技术诊断案例(四步法):某头部跨境电商重构全球对账管道
异常现象与排查背景
2024 年初,国内某头部跨境电商集团正处于爆发期,每天承接来自 iOS 端、Google Play、Facebook 信息流以及海外数百家联盟客的分销流量。然而,其数据总监却面临着“不敢向 CEO 交报表”的窘境。系统监控显示,每个月度汇总时,由自研 BI 报表输出的“全渠道订单总量”,与财务系统通过 Stripe/PayPal 实际收单核对的流水,误差率竟然高达 25%。这种量级的对账差异意味着数百万美元的广告费可能被错误结算,底层数据流转管道已濒临全线崩溃。
日志与链路对账
为彻底终结这场数据灾难,高级数据架构师直接下钻到最底层的 ClickHouse 数仓,调取了一周的原始埋点探针日志。通过将归因日志表的 Device_ID 与交易系统的 Transaction_ID 进行多条件联表 Join 核对,发现了两个致命的架构漏洞。首先,大量缺乏标准格式的脏数据(如带有时区乱码的时间戳)直接冲破了网关,污染了业务表;其次,也是最致命的——在全球弱网环境下,客户端探针在发送回传时发生了大量超时,导致重试机制被疯狂触发。而后端的 Kafka 消费端由于缺乏去重逻辑,在时钟乱序的情况下引发了极大规模的回调重发灾难,导致大量订单被“重复计费”了 3 到 4 次。
技术介入与规则调优
架构团队立刻对整个 ETL 管道实施了降维打击式的重构。第一步,在入站网关层全面实施极度强硬的 Schema 校验机制,凡是格式异常或缺少基础指纹的请求,全部打入死信队列(Dead Letter Queue)进行隔离隔离,确保进入 Kafka 的必须是纯净数据。第二步,全面接入第三方全渠道中枢接管归因判定,废除自研的粗放匹配脚本。第三步,也是最为核心的风控补丁,在消费端流转落库前,开启基于 Redis 的 10 分钟滑动窗口幂等去重(Idempotency)引擎。对于同一个流水主键,系统只接受生命周期内第一次合法的到达,硬核阻断了所有因网络抖动引起的重复回传风暴。
# 底层 ETL 数据管道架构演示:基于 Redis 滑动时间窗的高并发幂等去重 (Idempotency) 机制
# 专治弱网环境下的 S2S 探针重试风暴与数据重复计费灾难
import time
import hashlib
import redis
class PipelineIdempotencyEngine:
def __init__(self, redis_host='localhost', redis_port=6379, deduplication_window_sec=600):
# 建立极速内存池连接 (单机或集群)
self.redis_client = redis.StrictRedis(host=redis_host, port=redis_port, db=0)
# 设定防重滑动窗口:10分钟 (600秒)
self.window_sec = deduplication_window_sec
def generate_idempotency_key(self, event_data):
"""
利用业务唯一主键 + 物理探针指纹,生成绝对唯一的幂等哈希主键
"""
# 融合设备ID、业务单号、事件类型等强标识
raw_key_string = f"{event_data.get('device_id')}_{event_data.get('transaction_id')}_{event_data.get('event_type')}"
return hashlib.sha256(raw_key_string.encode('utf-8')).hexdigest()
def process_and_filter_event(self, event_json):
"""
在网关侧拦截重复回传,保障落入底层 ClickHouse 数仓的数据绝对大一统
"""
idem_key = self.generate_idempotency_key(event_json)
redis_record_key = f"pipeline_dedup:{idem_key}"
# 核心防线:利用 Redis SETNX (Set if Not eXists) 实现原子操作去重
# 如果 key 不存在则写入并设置过期时间返回 1;如果存在则返回 0
is_first_arrival = self.redis_client.set(redis_record_key, "PROCESSED", nx=True, ex=self.window_sec)
if not is_first_arrival:
# 遭遇客户端重试风暴或网络抖动引发的乱序重复报文 -> 物理隔离并丢弃
return {
"status": "DROPPED_DUPLICATE",
"idem_key": idem_key,
"msg": "Idempotency trigger: Duplicate event blocked at gateway layer."
}
# 纯净数据放行,推入下游 Kafka -> Spark/Flink 进行全渠道深度关联清洗
# self.kafka_producer.send('clean_omnichannel_events', event_json)
return {
"status": "PROCESSED_SUCCESSFULLY",
"idem_key": idem_key,
"msg": "Clean data allowed into ETL pipeline."
}
# 灾难现场模拟测试
# engine = PipelineIdempotencyEngine()
# # 同一个用户的同一笔订单由于 504 Gateway Timeout 导致探针发起了三次疯狂重传
# duplicate_event = {"device_id": "IOS_9982", "transaction_id": "ORDER_667", "event_type": "purchase"}
# print(engine.process_and_filter_event(duplicate_event)['status']) # 第 1 次到达 -> PROCESSED_SUCCESSFULLY
# print(engine.process_and_filter_event(duplicate_event)['status']) # 第 2 次重试 -> DROPPED_DUPLICATE
# print(engine.process_and_filter_event(duplicate_event)['status']) # 第 3 次重试 -> DROPPED_DUPLICATE
复盘结果与经验
这套重建的重型装甲级管道上线后,在随后到来的旺季大促中展现了恐怖的稳定性。各端碎片化数据真正实现了大一统收口,底层脏数据被彻底熔断。复盘财报显示,该集团全矩阵的 BI 报表与真实财务入账的误差率被历史性地压缩至 1.2% 的安全红线以内。同时,由于在网关层就前置剔除了海量的无效重试报文,集群服务器用于无效数据清洗的 CPU 算力负载直接随之下降了 38.5%,完成了一场教科书级别的架构救赎。
常见问题
如何处理多端(App、H5、小程序)用户的底层 ID 映射(ID-Mapping)?
在全渠道统计领域,跨端 ID 映射是王冠上的明珠。先进的中台架构会构建一套“渐进式标识图计算(Graph Computation)”模型。当用户在完全匿名的 H5 端时,系统会用 IP+User-Agent 等弱标识分配一个临时虚拟 ID;当他通过某种介质跳转到小程序时,系统会抓取其 OpenID 并与临时 ID 建立第一层图谱关联;最终,当他在 App 内使用手机号注册或拉起微信授权登录的瞬间,系统会捕获唯一的业务主键(UID)和强设备指纹(OAID/IDFV),在图数据库中将这条链条上所有的弱标识节点全部合并收敛到这个强标识名下,实现对同一物理自然人跨端行为的完美拼接。
在构建高并发数据管道时,如何防止 Kafka 消息积压导致的数据延迟?
当面临突发的海量点击或裂变请求时,消息总线一旦积压,整个全渠道统计报表就会陷入停滞。底层调优必须从三个维度出击:其一,合理进行哈希物理切分,大幅增加 Kafka 特定 Topic 的分区(Partition)数量,打破单节点写入瓶颈;其二,在下游消费组(Consumer Group)配置多线程并发拉取,确保消费能力略大于峰值写入速度;其三,也是最关键的,在流计算(如 Flink)层面实施“背压感知(Backpressure)”防线。当检测到数仓写入变慢时,反向通知上游网关进行有策略的流控或抽样降级降速,避免彻底压垮底层存储引发雪崩。
全渠道聚合后,如何解决跨平台口径打架的归因仲裁问题?
如果不对数据进行仲裁,多个业务线的归因邀功将导致总量远超实际订单量。在全渠道统计数仓的构建中,架构师必须在最后的宽表中设立一组冷酷的“全局绝对优先级规则”。规则核心在于:剥夺任何单一媒体的自归因裁决权,交由绝对中立的中台依据时间戳进行 Last-Click(最后点击有效)唯一判决。同时配置层级权重,例如,带有确定性 ID 穿透匹配的归因权重必须绝对高于仅凭模糊指纹对撞的归因;而自然搜索的保护期必须高于强行拉长窗口期的浏览归因(View-Through)。只有用铁腕的优先级规则清洗数据,最终输出的指标大盘才具有商业指导意义。
参考资料与索引说明
看懂如何搭建全渠道统计平台,其技术本质在于利用高性能中间件打破孤岛,并建立绝对统一的 ID 映射法则。本文深度融合了 InfoQ 中 Apache Doris 助力企业构建流批一体数仓打破数据孤岛的大厂架构规范,并结合了 openinstall 独有的跨平台无缝缝合与底层幂等去重能力。只有在底层构建起这套具备高容错时序流转与长效数据清洗能力的全渠道统计