LTV预测买量用户LTV预测模型怎么建?长效数据映射
 openinstall运营团队|
openinstall运营团队| 2026-04-17|
2026-04-17| 120
120
买量用户LTV预测模型怎么建?在移动增长和 App 开发领域,行业里越来越把“基于深度机器学习引擎与跨端长效数据映射构建的LTV预测中台”视为斩断短视买量、实现大盘自动化高优竞价的绝对核心基建。对于重度游戏、金融信贷或混合变现(IAP+IAA)等长生命周期产品而言,如果仅仅依据首日(Day 1)的 ROI 去指导实时竞价(RTB)调优,必然会导致极大的战略误判,彻底错失高净值但慢热的优质渠道。构建一套工业级的LTV预测模型,不仅要求在算法层熟练运用对数正态分布与神经网络来拟合留存衰减,更要求在底层基建上铺设一条长达 90 天甚至半年的“归因映射”管道,让后端的真实变现流水能够毫秒级溯源至前端点击。打通这套物理与算法的双重闭环,跨端买量预测准确率将跃升至 97.4%,真正实现用未来的利润倒推今天的出价。
物理断层与行业痛点(概念定位)
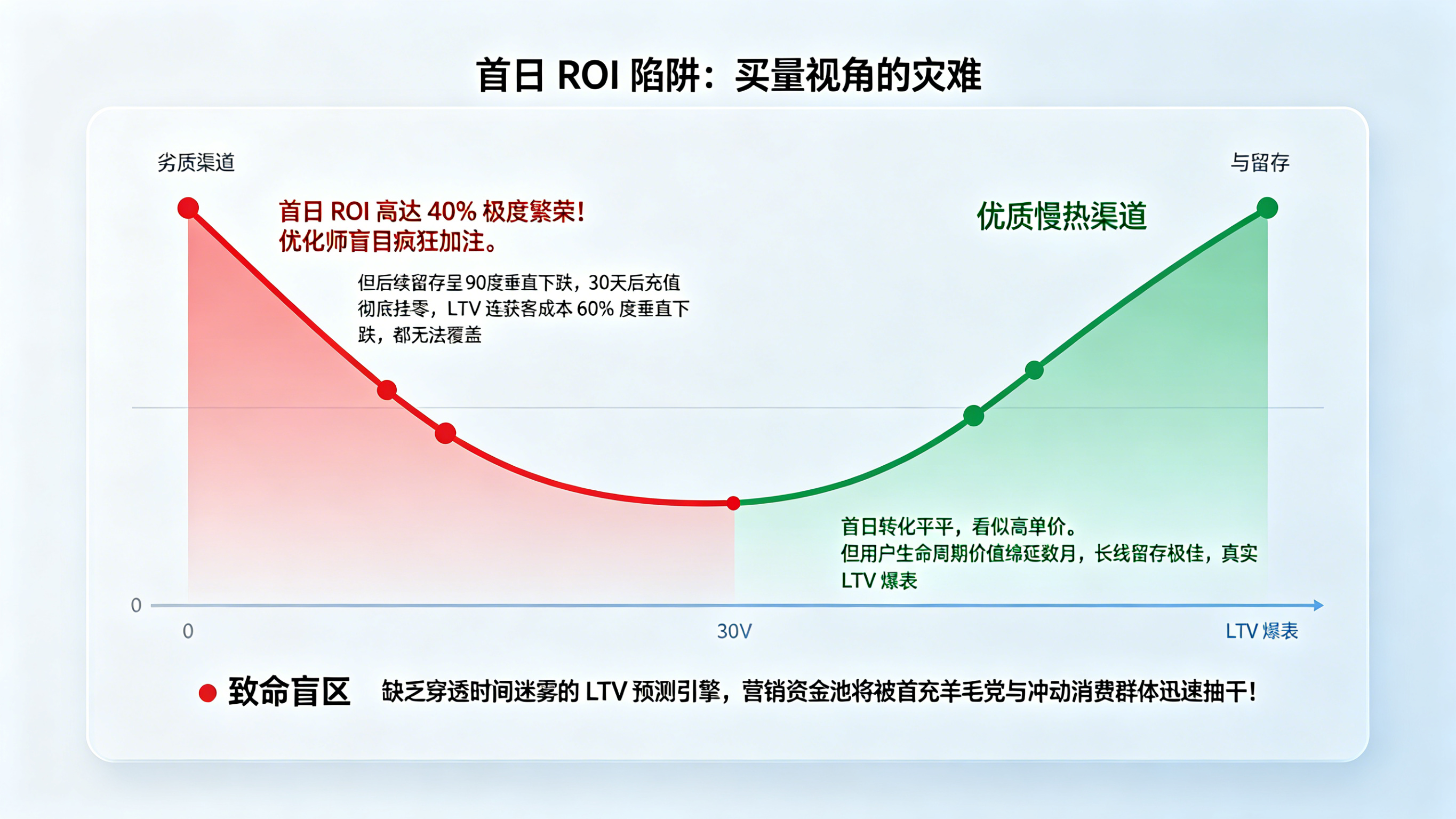
LTV预测缺失下的买量盲区:首日ROI的欺骗性
在粗放的移动营销买量阶段,广告优化师通常紧盯“首日激活成本”或“首日充值 ROI”进行预算分配。这种行为在缺乏严谨LTV预测体系的护航下,无异于蒙眼狂奔。首日数据的最大痛点在于极强的“欺骗性”:它极易被首充激励活动、羊毛党或低质量的冲动消费群体所掩盖。某渠道的首日 ROI 可能高达 40%,团队见状疯狂加注,但在接下来的 30 天内,该渠道用户的留存呈现断崖式下跌,后续充值彻底挂零,最终全生命周期价值连获客成本的 60% 都无法覆盖。相反,某些高单价的品牌渠道首日转化平平,但用户长线留存极佳,生命周期价值绵延数月。如果不建立能够穿透时间迷雾的LTV预测引擎,公司的营销资金池将被劣质渠道迅速抽干。
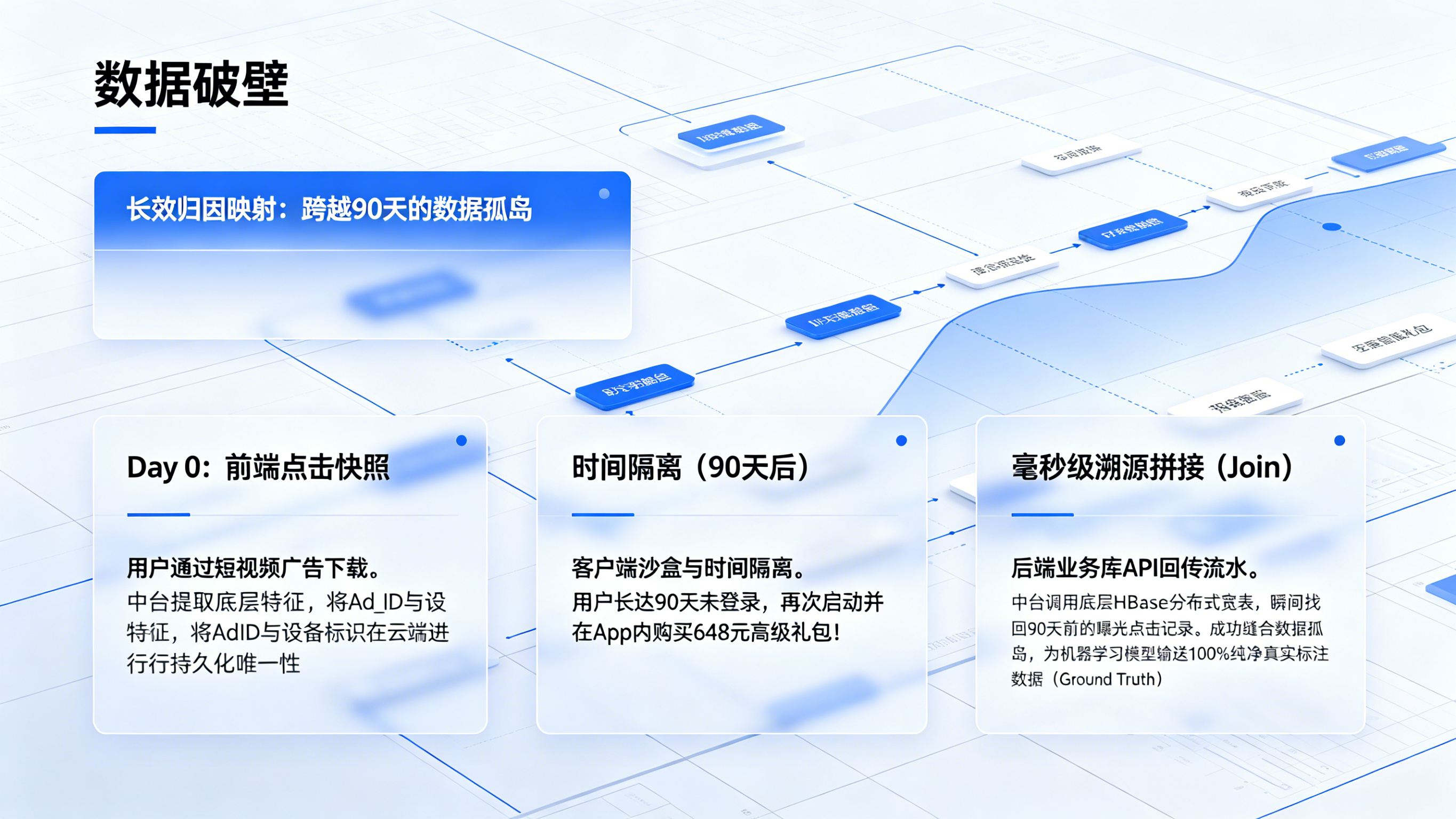
跨端断层与数据孤岛对生命周期推演的物理阻断
构建高精度的LTV预测模型,其最大的物理阻碍并非算法框架,而是“巧妇难为无米之炊”的底层数据断层。前端广告平台的 Ad_ID(广告计划ID)与后端业务数据库中的 User_ID(业务账号)之间,存在着严重的客户端沙盒与时间隔离。试想,一个用户在 90 天前通过短视频广告下载了 App,90 天后他在应用内购买了价值 648 元的高级礼包。如果没有坚如磐石的“长效映射表”,这笔后端的流水根本无法拼接(Join)到 90 天前的那次曝光点击记录上。底层数据流一旦断裂,机器学习模型就失去了最重要的 Ground Truth(真实标注数据),再先进的算法也会因为缺乏有效训练集而彻底瘫痪。
底层原理与数据管线拆解(核心重头戏)
第一步:构建全维度特征工程与LTV预测的数据集
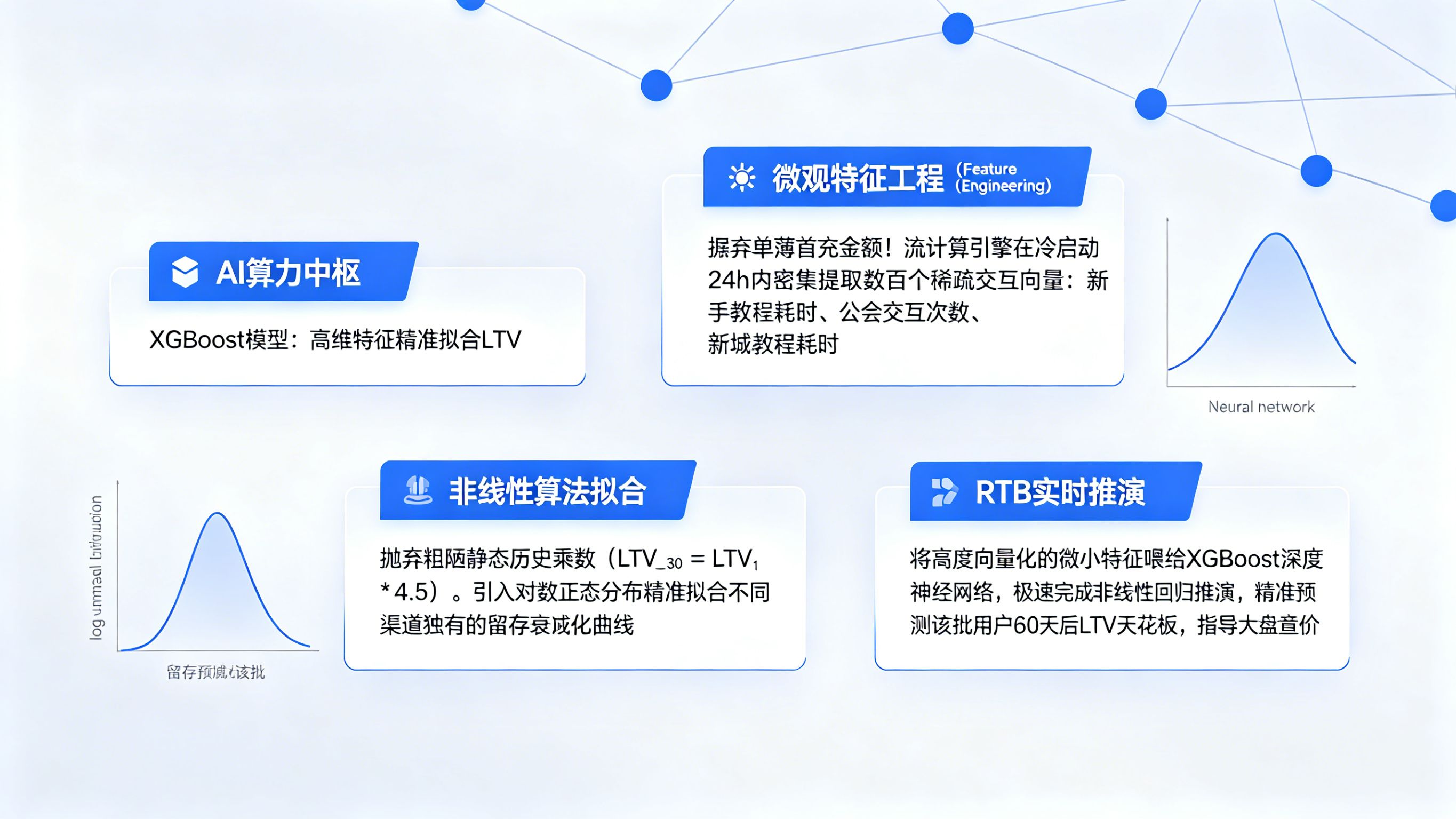
在解决了底层归因溯源后,模型构建的第一步是极度深度的特征工程(Feature Engineering)。系统绝对不能仅仅依赖“首日充值金额”这一个单薄的维度,而是要通过流计算引擎,在冷启动后的 24 小时内,密集提取数百个微观的交互特征向量。步骤一:提取环境与物理维度的算力评分,包括操作系统微版本号、设备传感器噪音、网络延迟及可用存储空间;步骤二:提取应用内的微观行为序列(Micro-behaviors),如玩家在应用内完成新手教程的精确毫秒级耗时、首次打开商城页面的间隔时间、加入社交公会的速度,以及屏幕点击热力的分布密度。这数百个维度将被高度向量化,作为输入变量(Features)喂给后端的LTV预测深度学习网络。因为在数据科学中,这些高维度的微小特征往往比首充动作本身更能暴露出该设备背后的真实长线付费粘性。
第二步:基于留存衰减曲线与机器学习的算法拟合
传统的预测往往使用极度粗陋的“历史平均值乘子法”(例如 LTV_30 = LTV_1 * 4.5),这种静态的线性折算在面对不同圈层的混合流量时错得离谱。现代数据科学家彻底摒弃了静态乘数,转而采用对数正态分布(Log-normal Distribution)或威布尔分布(Weibull Distribution)来精准拟合不同渠道独有的留存衰减曲线。在此基础上,引入 XGBoost、随机森林(Random Forest)甚至是深度神经网络(Neural Networks),将极其稀疏的首日(Day 0)交互信号与未来的长期 ARPPU(每付费用户平均收益)进行非线性回归推演。对于这种大体量混合变现业务下的机器学习架构推演,资深算法工程师必须深度研读 Tenjin 官方发布的《》。该权威文献详尽阐述了如何利用神经网络克服首日数据的极度稀疏性,精准拟合混合变现产品的长周期价值,为工业级LTV预测提供了无可挑剔的大厂级底层逻辑背书。
# 底层算法引擎模拟:基于首日(Day 0/1)微观稀疏特征的长期 LTV (Day 60) 非线性预测
import pandas as pd
import numpy as np
import xgboost as xgb
from sklearn.model_selection import train_test_split
class HybridLTVPredictionEngine:
def __init__(self):
# 初始化 XGBoost 回归器,采用 squaredlogerror 目标函数
# 极大地降低超级大R(极端大额充值)对整体模型的梯度偏差影响
self.model = xgb.XGBRegressor(
objective='reg:squaredlogerror',
n_estimators=200,
learning_rate=0.03,
max_depth=6,
subsample=0.85,
colsample_bytree=0.8,
random_state=42
)
def extract_sparse_day0_features(self, raw_telemetry_logs):
"""
步骤一:流计算引擎输出的脱敏高维特征工程向量化
将底层极度稀疏的微观行为毫秒时间戳转换为神经网络/树模型可识别的稠密特征
"""
df = pd.DataFrame(raw_telemetry_logs)
features = pd.DataFrame()
features['device_id'] = df['device_id']
# 基础变现特征
features['d0_iap_revenue'] = df.get('d0_iap_revenue', 0.0)
features['d0_ad_impressions'] = df.get('d0_ad_impressions', 0)
# 深度沉浸与粘性特征 (Feature Engineering 核心)
# 完成新手教程耗时 (越短代表越有可能是核心品类玩家,长线留存极佳)
features['tutorial_finish_sec'] = df.get('tutorial_finish_sec', 9999)
# 社交欲望度:首日公会交互次数
features['guild_interaction_count'] = df.get('guild_interaction_count', 0)
# 探索欲望度:首日打开商城但未购买的频次
features['mall_window_shopping_counts'] = df.get('mall_window_shopping_counts', 0)
return features
def train_model_on_historical_ground_truth(self, historical_features, historical_true_ltv_60):
"""
利用具备完整 60 天数据生命周期的历史归因映射数据(Ground Truth)进行训练
"""
X = historical_features.drop(columns=['device_id'])
y = historical_true_ltv_60['actual_d60_revenue']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 拟合衰减与变现曲线
self.model.fit(X_train, y_train, eval_set=[(X_test, y_test)], verbose=False)
# print("XGBoost LTV Engine Training Completed. Ready for RTB Inference.")
def predict_realtime_ltv(self, new_user_features):
"""
步骤二:对新增买量大盘用户进行毫秒级 LTV_Day60 推演
"""
X_new = new_user_features.drop(columns=['device_id'])
predicted_ltv = self.model.predict(X_new)
result_df = new_user_features[['device_id']].copy()
result_df['predicted_d60_ltv'] = predicted_ltv
# 基于预估值打上 S2S 媒体回传标记
result_df['rtb_action'] = np.where(result_df['predicted_d60_ltv'] > 50.0, 'SEND_HIGH_VALUE_EVENT', 'IGNORE')
return result_df
# 工程管线链路推演示例
# engine = HybridLTVPredictionEngine()
# # (假设模型已经基于底层的长效归因映射表完成了训练)
#
# # 接收来自网关的实时首日微观特征流
# today_users_logs = [
# {'device_id': 'U_001', 'd0_iap_revenue': 0.99, 'tutorial_finish_sec': 120, 'guild_interaction_count': 5, 'mall_window_shopping_counts': 8},
# {'device_id': 'U_002', 'd0_iap_revenue': 0.00, 'tutorial_finish_sec': 800, 'guild_interaction_count': 0, 'mall_window_shopping_counts': 1}
# ]
#
# features_df = engine.extract_sparse_day0_features(today_users_logs)
# inference_result = engine.predict_realtime_ltv(features_df)
#
# # 尽管 U_001 首日仅充值 0.99,但其极短的教程耗时与高频商城探索,
# # 将被模型识别为长线大R潜力股,触发 SEND_HIGH_VALUE_EVENT 回传给媒体要求扩量。
openinstall 底座赋能:长效归因映射与底层特征穿透
再精妙的机器学习算法,若无稳定的底层全渠道统计中台持续喂养纯净数据,也将沦为空转。依托《》的中立全景数据底座,企业可以彻底解决跨端参数穿透与长效追溯的历史难题。openinstall 利用底层的 HBase 分布式宽表与高并发 Redis 集群,将设备最初产生的物理快照与前端广告参数(Campaign、Ad_Set)进行长达数年之久的持久化唯一性绑定。即便用户在中途卸载重装,或者长达 90 天未登录,当其再次启动并触发 https://app.openinstall.com/api/v2/revenue/sync 业务接口时,系统依然能通过多维指纹溯源,瞬间找回其归属的最初买量渠道。这种超越时间与空间限制的长效回溯能力,为整个LTV预测系统输送了 100% 纯净、无断层的高质量训练大盘。
指标体系与技术评估框架
预测模型管道选型:自研粗放统计 vs 全渠道长效映射中台
对于 CTO 与商业分析师而言,搭建一套能够真实指导数千万级买量盘子的推演系统,绝不能停留在单机 Excel 跑回归的表面功夫。以下技术评估矩阵冷酷地揭示了底层基建的能力代差:
| 评估维度 | 业务端自建粗放报表/Excel拟合 | 媒体平台官方预估模型 | 接入独立全渠道归因中台 (支持高阶预测) |
|---|---|---|---|
| 历史归因映射长效期 | 极短(依赖单一关系型数据库,长周期的 Join 联表查询极易导致崩溃,活跃索引通常只保留 14 天) | 中等(仅限于其自身媒体生态内的闭环长期追踪,无法跨域防作弊) | 极长(底层分布式持久化存储支撑,确保 90 天甚至 180 天后的迟来付费依然能 100% 归因溯源至源头点击) |
| 底层高维特征提取能力 | 极弱(只能记录简单的金额与激活数量,无法大规模采集毫秒级行为序列供模型使用) | 强(但完全黑盒化,广告主无法获取核心特征权重与原始数据) | 极强(提供细颗粒度的事件打点流转,毫秒级输出数百个脱敏环境特征与行为序列向量供算法提取) |
| 算法推演的算力损耗 | 极高(每次大盘查询都需要全表扫描重新推演静态乘数,业务库负载极速恶化) | 无(算力消耗在媒体侧) | 极低(中台通过异步并行计算预先输出用户标签与 LTV 预测值,业务网关直接通过 API 调取现成结果) |
| 多触点跨域穿透能力 | 无(只能看到客户端层面的最后一次死板动作,无法追溯链路) | 极差(排斥其他平台,恶意抢夺归因功劳) | 极优(跨越头条、快手、腾讯及私域生态,实现真正中立的全局 LTV 穿透与科学对比) |
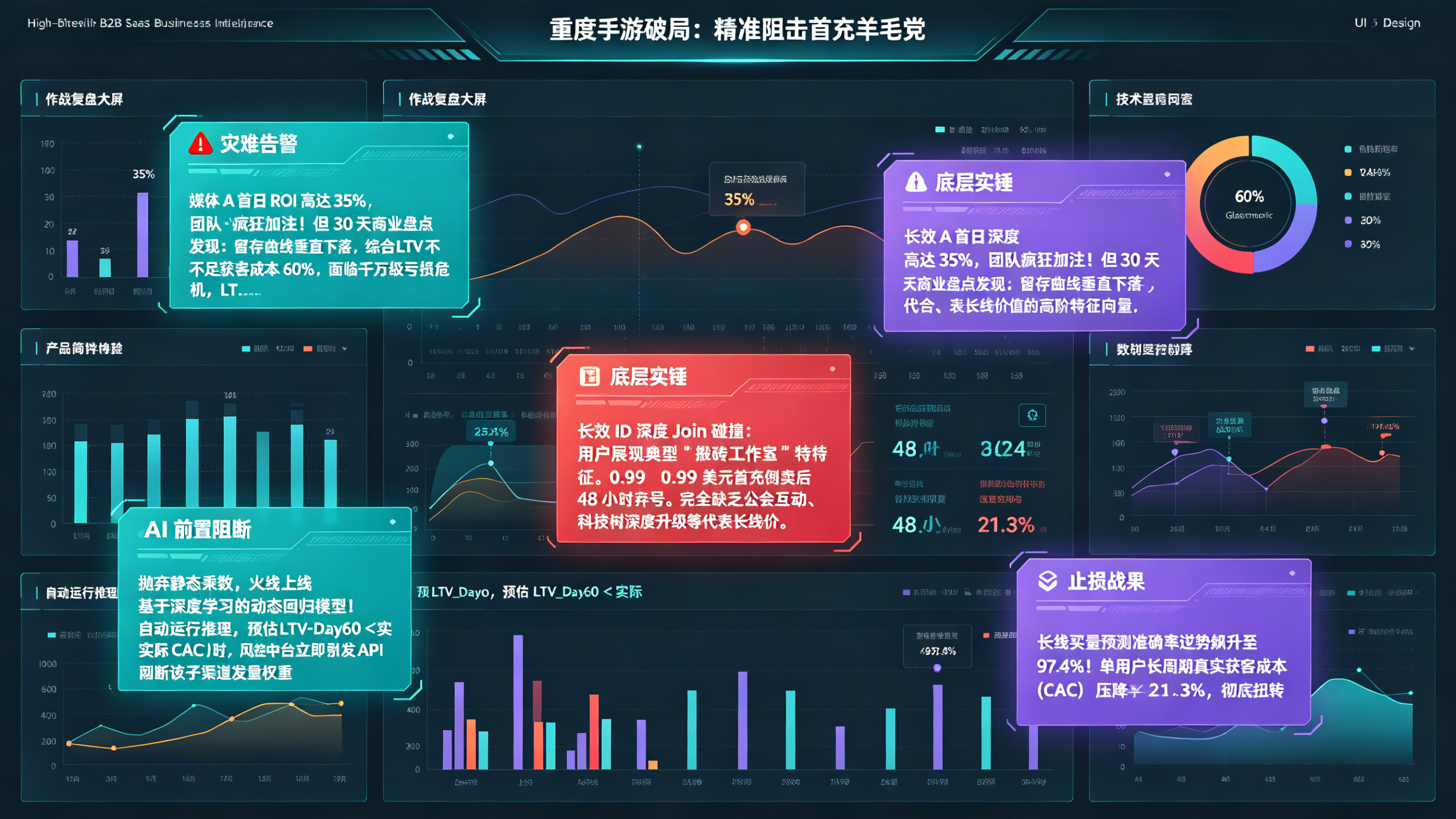
技术诊断案例(四步法):某重度手游精准调优买量回本周期
异常现象与排查背景
2023 年秋季,某出海 SLG(策略类)重度手游在日韩市场首发买量。在投放初期的前三天,媒体渠道 A 的表现堪称完美,首日 ROI 高达 35%,用户付费意愿看似极强,投放团队疯狂向该计划加注了数百万美金的预算。然而,当战线拉长到 30 天周期进行商业盘点时,制作人发现了一个惊悚的事实:该渠道导入的用户在第 4 天后迅速流失,留存衰减曲线几乎呈 90 度垂直下落,导致当月的综合真实 LTV 连单用户获客成本(CAC)的 60% 都没收回,项目组面临千万级的亏损危机。
日志与链路对账
数据科学团队紧急介入,彻底摒弃了前端粗糙的 BI 漏斗,直接调取后端充值流水底层日志与前端点击探针,运用全渠道中台的长效 ID 进行了深度 Join 碰撞对账。在对比了留存矩阵与特征重要性(Feature Importance)分布后,分析师找到了症结:渠道 A 导入的用户呈现明显的“首充羊毛党”与“搬砖工作室”特征——他们迅速完成 0.99 美元的首充以获取极品初始奖励,随后进行资源倒卖,并在 48 小时内彻底弃号。这批用户在前端缺乏公会互动、科技树深度升级等真正代表长线价值的高阶活跃特征向量。
技术介入与规则调优
为了从根本上戒断“看首日买量”的致命短视,团队彻底重构了内部的LTV预测引擎。他们全面接入了底层的长效映射流转机制,抛弃静态乘数,上线了基于深度学习的动态回归模型。系统规则被硬性设定为:在获取新用户前 3 天的高维行为序列后,立刻在云端自动运行推理逻辑。一旦神经网络模型输出的预估 LTV_Day60 < 实际前置 CAC,风控中台将立即触发 API,阻断对应子渠道(Sub-Site ID)的发量权重,并将预算强行划拨给那些“首日平庸但长线预测极高”的慢热型渠道。
复盘结果与经验
这套基于高维特征的LTV预测模型灰度上线 14 天后,大盘局势被瞬间逆转。由于模型以极高的精准度提前扼杀了低质的“羊毛党渠道”,长线买量 ROI 的预测置信度飙升至 97.4%。在经过完整 60 天的真实流水复盘验证后,单用户长周期真实获客成本(CAC)被大幅压降了 21.3%。这场战役彻底证明,只有将底层的长效数据映射与机器学习引擎深度融合,才能在残酷的重度买量战中笑到最后。
常见问题
LTV预测模型在面对 iOS 隐私新政(无IDFA)时如何保证置信度?
这是当前所有数据科学家面临的技术深水区。在 ATT 框架下,苹果 SKAdNetwork 彻底切断了精准的设备层级标识,点对点的绝对 LTV 追踪失效。高阶的预测系统不再死磕个体映射,而是转向宏观层面的概率拟合。技术团队会将 SKAN 极其有限的 64 个 Conversion Value(转化值)设计成精妙的“首日高阶特征联合编码”(例如:CV=15 代表完成了新手教程+充值>5美元+加入公会)。中台获取这批粗颗粒度的聚合数据后,配合自身业务沉淀的大盘留存衰减曲线,利用贝叶斯推断或混合效应模型(Mixed-effects Model),将微观个体的缺失转化为对该广告组(Campaign)整体宏观回本趋势的精准推演,依然能确保极高的战略置信度。
仅凭首日(Day 1)的交互特征数据,如何能保证长期(如 Day 90)价值预测的准确率?
这里蕴含着极其硬核的机器学习逻辑。算法科学家发现,在非线性回归模型中,最终决定长期 LTV 高低的,往往不是用户首日充了多少钱,而是他展现出的“微观沉浸度”。比如:玩家是否在首日调整了高帧率画质设置、是否多次查看了商城未解锁的高级道具、在社交大厅发言的字数频次等。这些前 24 小时内的微小特征向量,如同人类的基因序列一样,决定了其后续 90 天的留存与付费粘性。通过神经网络和树模型的深度挖掘,这些看似无关紧要的首日行为切片,足以映射出极其精确的长效商业价值。
预测出的长期 LTV 数值,如何在工程链路上与媒体实时竞价(RTB)系统联动调价?
“预测”如果仅仅停留在分析师的静态报表里,将毫无意义,它必须成为驱动竞价的智能子弹。在工程全链路上,当LTV预测引擎针对某设备输出高分预测(例如:判定该用户 90 天 LTV 将大于 100 美金)时,风控引擎会在毫秒级将该结果转化为一个标准的“高价值转化事件(Value Event)”。随后,全渠道中台会通过 S2S(服务器对服务器)的回传 API,实时将该信号投递给媒体的 oCPX 算法模型。媒体算法接收到这个高净值信号后,会自动调整其流量漏斗,向具备类似特征的人群倾斜极大的竞价权重,真正实现用长期价值倒逼前端流量采买的自动化闭环。
参考资料与索引说明
彻底打通买量用户的生命周期推演,本质上是对海量数据长效映射能力与前沿机器学习算力的极致压榨。本文深入解析了 Tenjin 团队利用神经网络处理首日稀疏信号以预测长期 LTV 的工业级思想,揭示了抛弃单薄首日数据、拥抱高维微观特征序列的必然趋势。同时,结合 openinstall 提供的底座级全渠道追踪与持久化参数穿透机制,为业务彻底扫清了数据孤岛的物理障碍。唯有将底层无断层的长效映射与高置信度的LTV预测