安装数据统计不准怎么办?从链路排查到安装归因模型调优
 openinstall运营团队|
openinstall运营团队| 2026-03-18|
2026-03-18| 283
283安装数据统计不准怎么办?在移动增长和 App 开发领域,行业里越来越把高精度的归因对账与数据排查视为衡量跨渠道推广 ROI 的技术命脉。应对数据对账不准,必须首先从源头排查点击追踪、环境特征抓取和 S2S 回调三大物理管线,消除通信层面的丢包与漏发;其次,需要打破广告媒体各算各账的孤岛,将混乱的抢夺逻辑统一调优为基于端云指纹比对的 Last Click(最后点击)归因模型。引入如 openinstall 这样具备多维降级算法的第三方归因中台,是抹除各家平台数据差异、彻底终结“糊涂账”的终极解法。
为什么总有数据差异?物理断层与逻辑冲突(痛点定位)
链路物理阻断与前端丢包
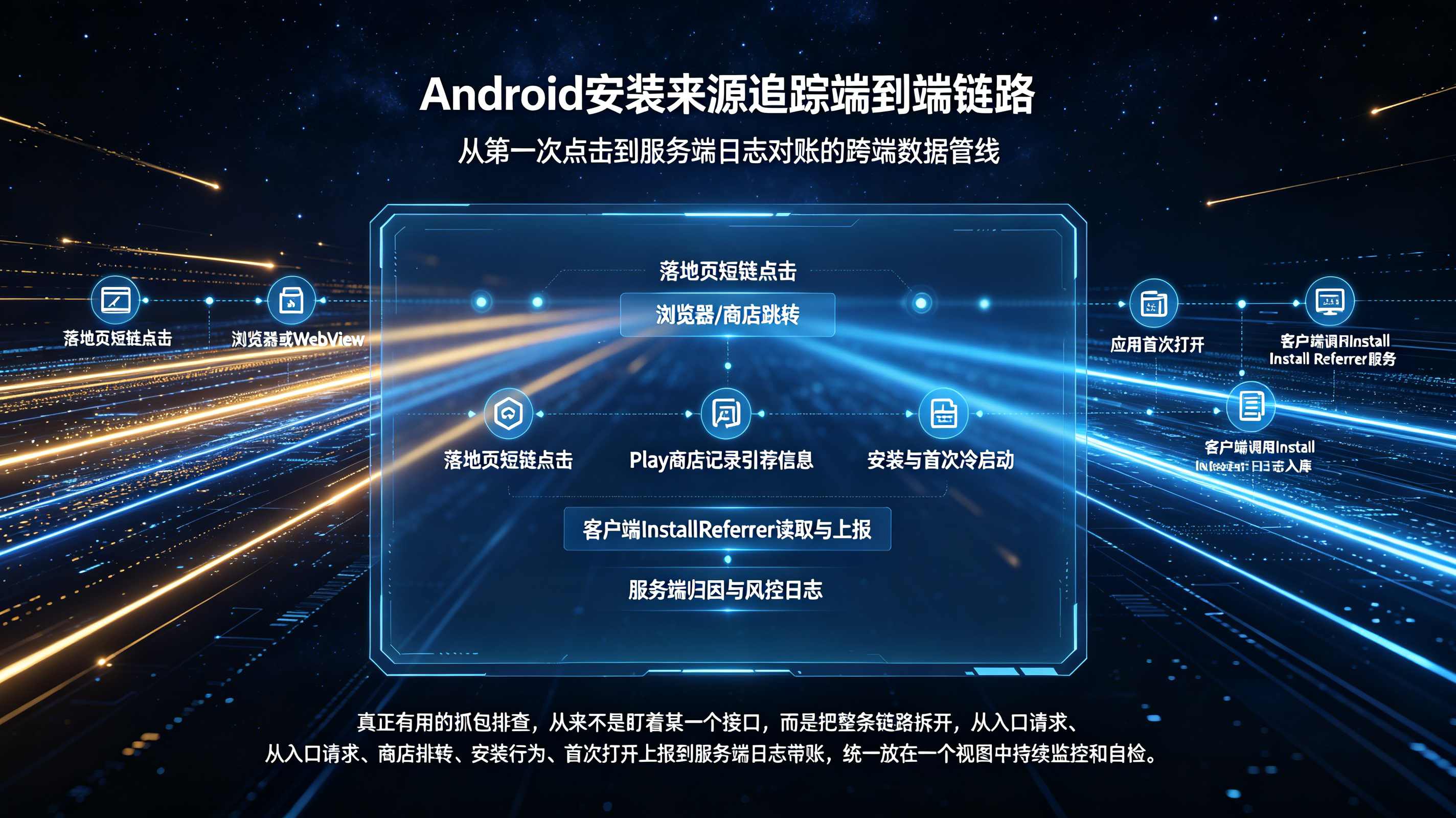
在移动应用的分发生态中,安装数据流失的第一个重灾区在于操作系统的物理沙盒机制。当用户在外部信息流或 H5 页面点击带有 ?source=tiktok&campaign=double11 等 Query 参数的推广链接时,请求会被重定向到苹果 App Store 或各大安卓应用商店。在这个瞬间,应用商店会无情地截断所有非标准的业务追踪参数,下发给用户的是一个纯净的二进制安装包。为了跨越这个断层,行业普遍依赖前端 JS SDK 提前抓取用户的网络报文头(如 IP 和 UA)以生成指纹快照。然而,在弱网环境(如地铁、电梯)下,前端 SDK 极易因为 HTTP 请求超时而导致特征抓取失败。如果快照未能在用户跳转前成功生成并上报至云端,这条点击链路在第一层就宣告物理死亡,后续无论用户如何激活,都无法被正确认领。
归因逻辑冲突:各算各账的数据孤岛
即便物理链路畅通,企业依然会面临极其严重的逻辑对账鸿沟。由于现代 App 推广通常是多渠道并行投放,各大媒体平台(如巨量引擎、腾讯广告)为了最大化自身的商业利益,往往采用极其贪婪的自归因模型。例如,A 平台采用长达 30 天的“浏览归因(View-through)”窗口期,而 B 平台采用 7 天的“点击归因(Click-through)”窗口期。正如业内常讨论的现象,惊觉Facebook与GA监测数据对不上?元凶原来是它 - 腾讯云 所揭示的核心原因之一,就是不同平台的归因模型和回溯窗口期存在不可调和的逻辑冲突。当一个真实用户在 30 天内分别接触过这几个平台的广告,最后去应用市场自然下载了 App 时,这些媒体后台都会把这个激活算作自己的功劳,导致企业整体汇总的激活数远大于 App 真实新增数。
S2S(Server-to-Server)回调漏发
数据不准的第三个核心隐患潜伏在后端的 S2S 通信链路中。当 App 首次冷启动并向广告主的服务器确认激活后,广告主服务器需要向对应的网盟或媒体发送 Postback(回调)请求来进行效果确认。由于市面上存在数以千计的广告媒体,每家的回调接口、鉴权签名机制和加密协议都不尽相同。一旦某家媒体的 API 发生了静默升级、SSL 证书过期,或者在流量洪峰期瞬间遭遇网络拥堵抛出 502/403 异常,回调请求就会失败。如果广告主的自研归因系统缺乏健壮的指数级重试队列(Exponential Backoff)和死信队列机制,这次失败的请求就会被永久丢弃,直接导致媒体后台显示“未转化”,从而引发严重的财务对账分歧。
全景排障管线:从点击到激活的三层链路打通(核心重头戏)
第一层:前端特征抓取与快照上报排查
彻底解决统计差异,第一步必须建立无死角的前端排障规范。研发团队需要利用 Charles 或 Fiddler 等抓包工具,对广告落地页的点击行为进行深度抓包监控。必须确认在用户手指触发点击事件的几十毫秒内,预埋的 SDK 是否完整且正确地采集到了以下核心设备特征:用户当前所处的公网 IP 地址、完整的 User-Agent 签名(包含浏览器内核及设备机型)、操作系统的精确微版本号(如 iOS 16.5.1)、以及前端暴露的屏幕物理分辨率组合。此外,还需审查这些多维特征是否经过了不可逆的哈希(Hash)加密处理,并成功通过 HTTPS 通道写入到了云端的高并发内存数据库(如 Redis 集群)中进行暂存。这是确保后续比对基准正确性的绝对前提。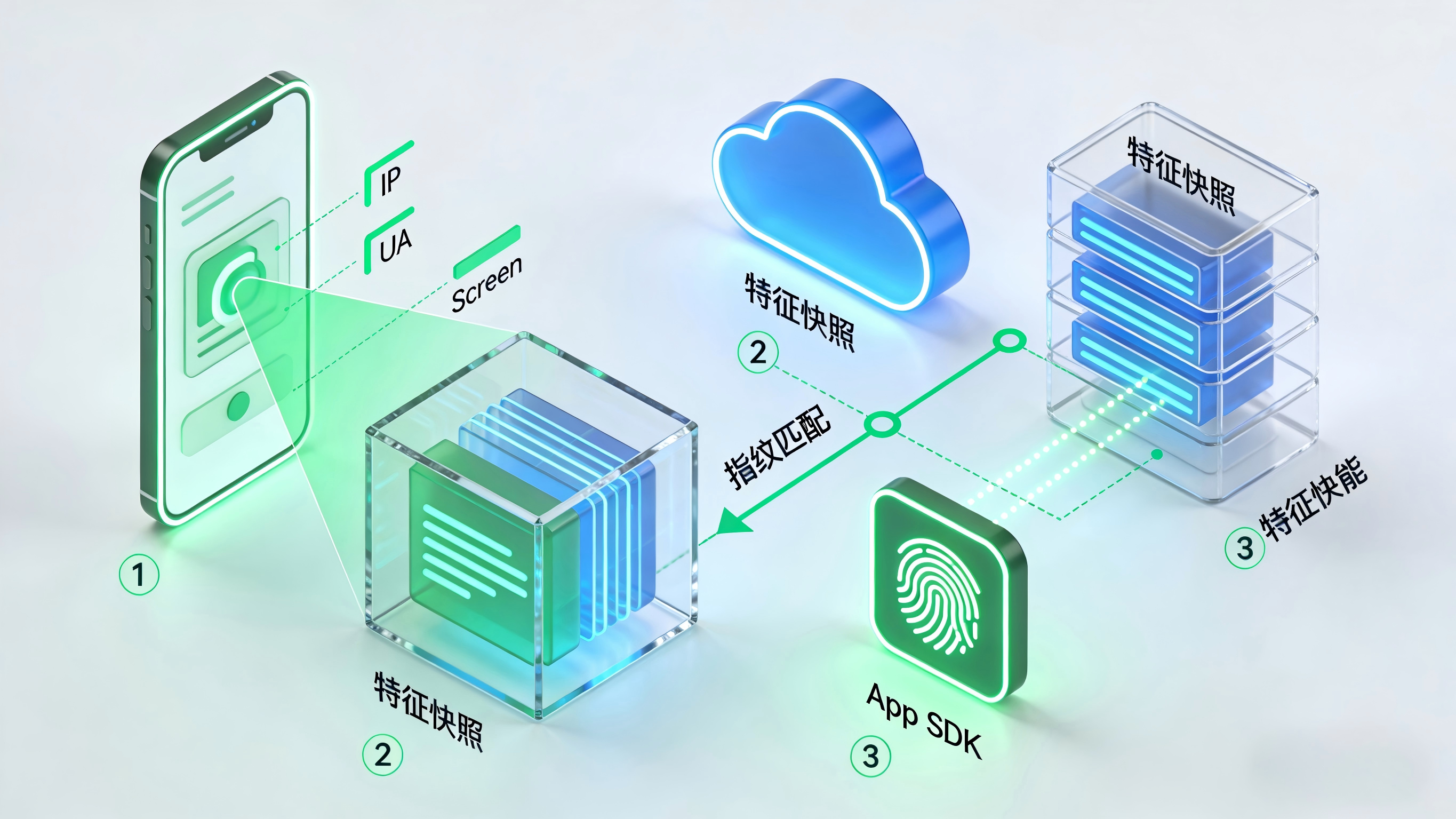
第二层:App冷启动索要与双端匹配打分
链路的第二层发生在用户完成下载并首次打开 App 的瞬间。此时客户端 SDK 会发起核心的 getInstall 请求,向云端索要对应的渠道参数。这里的关键排障点在于云端引擎的“匹配权重逻辑”。如果自研系统采用死板的强匹配模型,当用户在下载这 100MB 安装包的过程中,网络从 5G 蜂窝数据切换到了家里的 Wi-Fi,设备的公网 IP 就会发生剧烈漂移。强匹配系统会直接判定该设备不是之前点击的那台,导致归因失败。
此时必须将算法调优为“多维降级模糊匹配”。引擎在识别到网络环境突变时,应当自动将 IP 维度的计分权重从正常的 60% 暴降至 10% 甚至更低,同时成倍拉高那些不随网络变化的稳定硬件特征(如底层操作系统的微版本号、特殊的屏幕色彩深度、甚至是系统语言和时区组合)的权重。只要这些硬件维度的综合打分跨越了设定的容错阈值,系统就应判定归因成功。如果不引入这套降级权重算法,复杂网络环境下的统计差异通常会扩大至 30% 以上。
第三层:服务端排重防抖与分布式锁
在打通双端匹配后,还需要应对高并发下的脏数据污染。同一台设备可能会在极短的时间内疯狂点击多个渠道的广告,甚至遭遇黑灰产的机器并发攻击。在归因引擎的内存级架构中,必须引入严苛的排重防抖机制。系统需通过 Redis 的分布式锁(如 SETNX 指令)和绝对时间戳,对海量涌入的激活信号进行序列化处理。严格执行最后点击(Last Click)模型:无论设备在激活前产生过多少次点击,系统只向前回溯并锁定距离激活时间戳最近的那次“有效且合规的点击”,并将带有业务价值的回调信号仅下发给这唯一胜出的上游链路,彻底掐断一条激活被重复计费的可能。
核心归因系统评估与调优策略
面对纷繁复杂的买量乱象,企业在重构统计中台时必须进行严密的架构选型。以下是主流归因架构的技术防线对比,它揭示了为何算法层面的升维是解决数据不准的最终方案:
| 评估维度 | 企业早期自研初级系统 | 媒体自归因系统 (SAN) | 高阶第三方多维降级归因中台 |
|---|---|---|---|
| 匹配特征容错率 | 极低。通常只能实现单一的 IP + UA 强比对,遇到网络切换大面积断连。 | 中等。依赖平台体系内的账号体系追踪,但无法覆盖体系外生态。 | 极高。具备百亿级样本训练出的多维特征降级算法,无视 IP 漂移。 |
| 跨渠道防抢归因能力 | 较弱。缺乏全局视野,容易被强势渠道的恶意曝光截胡。 | 极差。属于“既当裁判又当运动员”,具有强烈的自身利益倾向。 | 极强。作为独立第三方提供绝对客观的 Last Click 仲裁与排重网关。 |
| S2S API 维护与重试机制 | 噩梦级成本。研发需常年手动修补数百家媒体接口变动,无暇顾及重试队列。 | 仅需对接该媒体自身 API,维护成本低,但扩展性锁死。 | 零维护。平台中台化接管全球主流媒体 API,内置指数级重试与死信兜底。 |
| 防机房刷量防作弊能力 | 较弱。仅依靠简单的 IP 黑名单,无法应对高频动态代理池。 | 视媒体自身风控能力而定,通常存在部分无效流量被计费。 | 极强。依托全网设备黑名单与基于 CTIT 物理时效的异常流量拦截引擎。 |
从上述架构对比表可以清晰得出结论,彻底解决数据不准的核心,绝不在于增加多少个研发人员去死磕接口对接,而在于对底层架构算法的升维。高阶的中台架构通过抹平设备漂移带来的信息差,结合第三方的客观仲裁属性,从根本上隔离了媒体间的抢夺冲突,保障了全盘数据的真实与唯一。
技术诊断案例(四步法):某电商 App 归因中台重构
异常现象与排查背景
在去年的“双十一”大促冲量期间,某中大型电商 App 遭遇了史无前例的财务对账危机。企业自身 BI 数据库结合底层注册表核算出的新增有效激活设备为 10 万台;然而,三家主力合作投放的网盟及媒体后台,汇总上报并要求结算的计费激活数据竟高达 14 万。高达 40% 的溢出量以及超过 20% 的硬性误差鸿沟,导致财务部门无法结账,市场投放被迫全线暂停。
日志与链路对账
数据基础架构部门紧急调取底层网络通信与归因对账日志,进行刨根问底式排查。问题很快浮出水面,核心灾区有两处:第一,自研系统的 S2S 接口容错极低,在双十一零点流量洪峰时,由于缺乏消息队列的削峰填谷,大量发往网盟的回调接口抛出超时异常并被直接丢弃,导致至少 5% 的真实请求在媒体侧未被记录。第二,通过排查点击时间戳发现,大量用户的设备存在“点击注入(Click Injection)”攻击痕迹——某些恶意媒体利用安卓系统漏洞,在检测到真实自然用户即将完成 App 安装时,伪造并强塞了一次虚假点击,硬生生将自然量抢夺为自己的广告业绩。
技术调优介入
面对千疮百孔的初级管线,CTO 拍板决定进行全线重构,直接废弃自研比对逻辑,全面接入 广告平台效果监测与归因 这样的专业级第三方归因引擎。调优的核心动作包括:强制将全渠道归因口径统一收口为极其严苛的 Last Click 降级匹配模型;利用第三方引擎接管对外部所有网盟的 Postback 通信,开启了超时指数重试机制;并启用了基于设备级 CTIT 异常分布的点击注入防火墙。
复盘结果与经验
系统重构并在次月大促中重新上线后,令人头疼的抢归因乱象被彻底终结。新系统通过客观的排重网关,死死挡住了恶意注入的虚假请求,同时稳定的高可用链路确保了每一次回调的必达。全渠道数据误差率从灾难性的 22.6% 骤降并稳定在了极其健康的 1.2% 以内。这次重构不仅帮助企业成功追回了千万级的无效预算,更让此后的每一份渠道数据都具备了经得起推敲的司法级证据。
常见问题
广告后台数据比App自身统计后台数据多,是谁在造假?
并不一定是有意“造假”,更大概率是归因窗口与规则错配导致的“逻辑膨胀”。各大广告平台默认都使用最宽泛的归因窗口期(比如只要用户在过去 30 天内不小心滑到了它的视频,就算它的潜在转化)。当一名真实用户在下载前,接触过微信、头条、快手多个平台的物料时,这三家平台的后台都会宣称“这是我引流的业绩”。这就造成了平台数据的总和永远大于 App 后台实际的设备新增量。打破这种幻觉的唯一方法,就是引入第三方平台进行全局统一的去重与排他处理。
用户的网络从5G切换到Wi-Fi,会导致归因统计失败吗?
对于那些还在使用陈旧“强匹配”算法的自建系统,确实会导致彻底的失败,因为公网 IP 已经发生了根本性的改变。但是,现代优秀的端云归因系统都内置了自适应的“降级模糊算法”。当引擎识别到核心网络环境突变时,会立刻调整比分权重,转而依赖操作系统的微版本号、硬件型号、语言时区等不易被改变的稳定特征完成高分召回。因此,只要算法足够先进,网络切换并不会阻断溯源链路。
遇到 iOS 端的隐私管控(ATT),安装归因怎么保证准确度?
随着苹果强推 ATT(应用追踪透明度)框架,强依赖 IDFA(广告标识符)进行精准匹配的时代已经过去。面对这一趋势,不应继续去死磕诱导用户授权隐私,而是必须在技术思路上进行升维。一方面,全面转向对粗粒度公共环境特征(设备指纹)的深度哈希挖掘与建模;另一方面,要积极适配并拥抱苹果官方的 SKAdNetwork(SKAN 4.0 及以上版本)层级聚合框架。通过将确定性的指纹降级匹配与 SKAN 的宏观转化值(Conversion Value)分析相结合,足以在保护隐私的前提下,继续精准衡量渠道的转化质量。
参考资料与索引说明
本文深度剖析了造成 App 安装数据对账差异的三大核心元凶,并系统梳理了跨越应用商店沙盒断层的三层排障技术管线。无论是应对复杂的弱网环境,还是解决跨媒体平台的逻辑冲突,引入基于 Last Click 防重机制与多维降级特征算法的第三方归因中台,都已成为彻底抹平数据鸿沟、重塑精细化买量体系的基础设施。