实时安装追踪如何实现?回调机制与实时看板架构设计
 openinstall运营团队|
openinstall运营团队| 2026-04-01|
2026-04-01| 348
348
实时安装追踪如何实现?在移动增长和 App 开发领域,行业里越来越把“建立从点击到激活的秒级反馈闭环”视为衡量投放团队敏捷调价能力与业务抗压能力的试金石。传统依赖底层数仓进行 T+1 跑批出表的模式,已经完全无法应对现代信息流广告分钟级的竞价波动与复杂的反作弊需求。团队急需的是一套彻底打通“客户端无感采集、归因引擎秒级匹配、中台实时事件下发、企业内部流式计算”的现代化高并发数据管线。借助 openinstall 等专业归因中台的流式架构与海量 Webhook 回调分发机制,企业可以轻松获取设备安装、注册等深度转化事件的实时脉搏,进而结合消息队列与实时流处理引擎,搭建出具备极高可用性与吞吐量的实时指标大屏。
物理断层与行业痛点(概念定位)
T+1 离线报表的死穴与“盲飞”困境
在早期的移动营销体系中,数据流转通常依赖于经典的离线批处理架构(Batch Processing)。大量的初创团队甚至中大型企业,习惯于将业务数据库、前端埋点日志统一步入 Hadoop Hive 或离线数据湖中,在凌晨 2 点通过 MapReduce 或 Spark 脚本进行表级 Join 运算,最终在次日清晨产出前一日的各渠道 ROI、激活数和转化漏斗。然而,在如今高度内卷的算法分发时代,这种 T+1 离线报表暴露出致命的死穴:由于广告平台的 oCPX 竞价模型是实时根据转化回传进行模型微调的,如果广告主依靠第二天的离线报表去判断昨天的素材质量和渠道优劣,无异于在高速公路上“蒙眼驾驶”。当某个黑产渠道或长尾网盟在极短时间内倾泻大量低质量甚至作弊流量时,T+1 的延迟意味着预算在风控系统告警之前就已经被消耗殆尽。这种时间差造成的“盲飞”困境,使得技术团队必须将整个归因与数据消费架构从离线批处理向实时流处理(Real-time Stream Processing)全面跃升。

高并发下客户端直传 BI 的性能与链路断层
为了追求“实时”,一些技术团队曾尝试过一种反模式的“捷径”:绕过所有的归因层,直接在 App 客户端埋点,一旦发生安装启动或注册行为,就高频调用 API 直传到企业自有的后端 BI 接口(例如向 https://app.openinstall.com/api/bi_report 强行发送)。这种架构在实战中会面临灾难性的性能瓶颈与极度严重的链路断层。首先,移动网络天然存在弱网丢包、连接超时以及 DNS 劫持等物理限制,高频直连自有服务器会导致大量的埋点数据在传输层丢失,且缺乏重试容错机制。更为核心的是“归因缺失”的逻辑断层:移动端应用下载归因的本质,是将 App 安装激活的设备信息与广告平台(如巨量、腾讯)的点击曝光日志在广域网进行哈希对撞。企业自有的 BI 系统根本无法跨平台、跨应用去拉取庞大且敏感的媒体侧实时点击流;同时,实现高精度的匹配需要对客户端提取的 IP 地址集合、操作系统底层补丁微版本号、User-Agent 字符熵值等复杂维度进行模糊打分,普通的 BI 系统根本不具备这种内存级对撞与指纹计算能力。因此,客户端直连注定走向死胡同,必须依赖专业的 S2S(Server-to-Server)归因流转管线。
底层原理与数据管线拆解(核心重头戏)
采集与引擎层:特征快照与内存级秒级归因
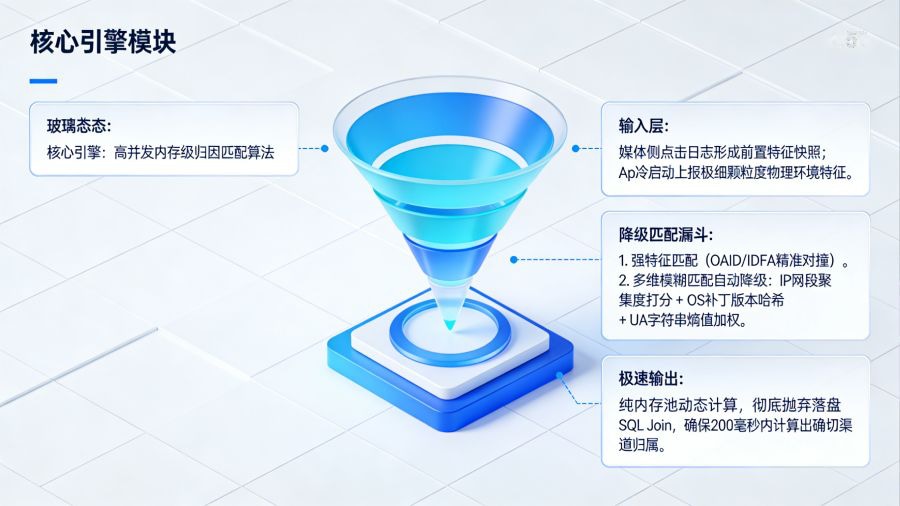
要构建实时追踪体系,最前端的考验在于如何在数百毫秒内完成跨端数据的匹配,这依赖于极高密度的特征提取与纯内存级的归因引擎引擎。时序流转的第一步:当用户在各类媒体平台点击广告链接产生 Click 数据流时,这些包含着广告主 ID、Campaign 信息以及用户设备环境参数的点击日志,会被瞬间写入归因中台的高并发内存缓存集群(如 Redis Cluster 或底层加速存储)中,形成“前置特征快照”。第二步:用户在应用商店完成下载并首次冷启动 App 时,SDK 会发起 Install 请求。此时,客户端必须在极短的时间内提取并上报极细颗粒度的物理环境特征,这包括但不限于:精确的外网 IP 地址、设备的真实分辨率尺寸、操作系统的具体微版本号(精确到补丁号)、系统语言及毫秒级的时区偏差,以及由于浏览器内核差异造成的 User-Agent 熵值。
第三步,也是最为硬核的引擎匹配逻辑:归因系统彻底抛弃了传统落盘后再进行 SQL Join 的低效做法,而是直接在内存池中触发动态加权匹配算法。系统首先尝试“强特征匹配”(如合法且非空的 OAID/IDFA),若强匹配失败,引擎毫秒级自动降级至“多维模糊匹配”。此时,算法会对提取到的 IP 进行网段聚集度打分,对 OS 版本和 UA 字符串进行哈希对撞,并对不同的维度赋予动态权重(例如在蜂窝网络下 IP 权重适当降低,UA 独特性权重拉高)。通过这种极度吃内存与 CPU 算力的加权打分模型,系统确保每一条激活日志都能在 200 毫秒内计算出确切的归因渠道,为后续的实时回调奠定物理时间基础。
网关与分发层:Webhook 回调与幂等性控制架构
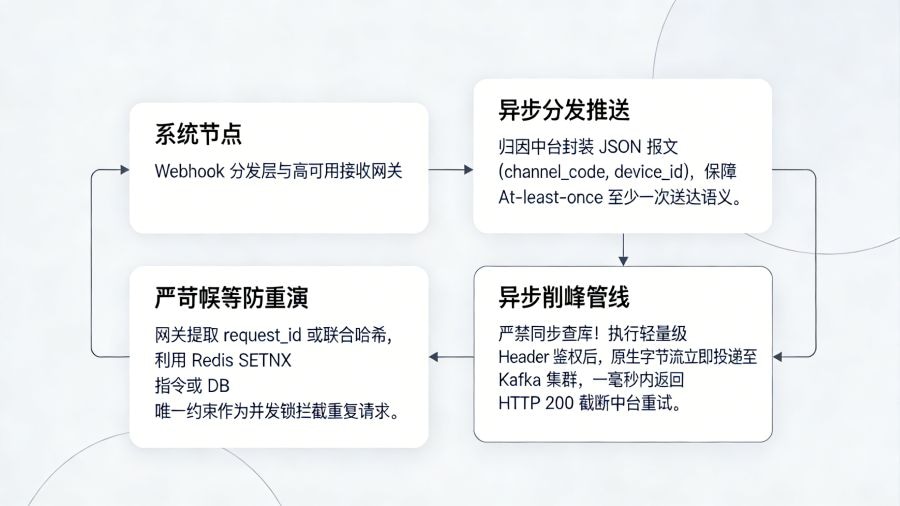
当安装归属在引擎层被判定后,如何毫秒级地将这条带有业务价值的战报“推送”给广告主,是中台管线的核心。这里的标准做法是采用服务端对服务端的 Webhook 实时回调机制。归因中台的异步分发集群会将匹配结果封装成 JSON 报文,这通常包含 channel_code(渠道标识)、click_time(点击时间戳)、device_id(设备唯一标识)等关键属性,然后通过 HTTP POST 的方式并发推送到广告主预先配置的接收网关。在这个环节, 所提供的底层事件回调下发能力,能够保证极高吞吐量下的“At-least-once(至少一次)”送达语义。
然而,“至少一次”送达语义意味着在遭遇公网网络抖动或接收端 TCP 握手超时的情况下,中台必然会触发重试机制以防丢数据,这就对接收端提出了极度严苛的幂等性(Idempotency)控制要求。广告主在设计接收 API 时,绝对不能拿到报文就无脑 INSERT 进数据库。正确的底层时序流转是:接收网关提取 Webhook 报文头中唯一的 request_id 或基于 device_id 与 event_type 生成联合哈希签名,利用 Redis 的 SETNX(Set if Not Exists)指令或关系型数据库中的唯一约束(Unique Index)作为并发锁。如果该主键已存在,则立刻放行并回复 HTTP 200,从而截断由于网络重试引发的重演乱象,确保业务计费层面的绝对精准,不错不漏。
数据消费与应用层:实时流式计算与指标看板构建
在接收到海量的、经过去重的 Webhook 报文后,企业内部的数据消费管线如何设计,直接决定了最终大屏指标的抗压极限。很多研发团队容易犯的致命错误是将 API 接收网关与复杂的内部业务逻辑(如查询用户状态、写入多个业务库、同步调用计费服务)强耦合。这种同步阻塞架构一旦遭遇流量洪峰,API 响应时间极易突破中台设置的阈值(如 3 秒),进而导致归因中台触发指数退避重试(Exponential Backoff Retry),雪崩效应瞬间拖垮整条管线。
现代化的高并发实时追踪流转范式必须坚持“接收必异步、计算必流式”。网关接收到 Webhook 后,仅执行最轻量级的 Header 鉴权与幂等校验,随后立刻将原生 Payload 以字节流形式投递至 Kafka 或 Pulsar 这样的分布式消息队列集群中,并在一毫秒内向发送方返回 HTTP 200 状态码,完成彻底的流量削峰填谷。随后,后端的 Flink 或 Spark Streaming 实时流处理引擎作为消费者,从 Kafka Topic 中持续拉取数据流,进行复杂的窗口聚合计算(Sliding Window / Tumbling Window),如动态测算每分钟各个渠道的新增量、计算激活到注册的极速转化漏斗,最终将聚合好的高维指标平滑写入 ClickHouse、Doris 等实时 OLAP 分析引擎中供前端大屏毫秒级刷新。这种流批结合的处理范式,在业界顶级流量场景中已被反复验证,相关演进思想在《》等权威工程剖析中亦有极深度的映射与论述。
指标体系与技术评估框架
实时流数据质量的评估黄金三角:延迟、吞吐与准确
抛开架构谈指标毫无意义。在验收实时安装追踪管线时,必须引入严苛的“评估黄金三角”:首先是 P99 响应延迟(End-to-End Latency),即必须保证 99% 的转化事件从用户在物理设备上触发,经由公网流转、内存匹配、Webhook 分发到最终在内部大屏的 OLAP 引擎中闪动,整体时间不超过 3 秒。其次是峰值吞吐量保障(Peak TPS),评估在诸如双十一零点等流量瞬间拉升十倍的极端场景下,Kafka 缓冲集群与 Flink 消费节点的弹性扩容与削峰能力,确保系统绝不丢包。最后是长尾数据修复率(Data Reconciliation),考虑到极端物理断网,必须设计自动化对账脚本,通过拉取归因系统次日提供的离线 T+1 日志作为兜底补偿,实现大盘数据的最终一致性(Eventual Consistency)。

实时追踪链路架构选型对比
在资源受限的情况下,团队到底该采用怎样的路线图?我们通过以下多维对比表格,深度透视三种典型追踪架构在研发成本与技术指标上的根本鸿沟:
| 追踪流转架构选型 | 端到端延迟时间 | 归因对撞准确率 | 服务器开发与承载成本 | 防作弊与链路抗劫持能力 |
|---|---|---|---|---|
| 客户端直连自有 BI | 中等(受网络重试影响大) | 极低(无跨平台点击日志池,无法做多维哈希比对) | 较低(需自建接收网关,但易被洪峰击穿) | 极差(容易被黑灰产抓包伪造全量埋点报文) |
| 媒体后台/归因平台隔日导出 T+1 | 极高(> 24小时) | 较高(利用离线跑批具备完整数据) | 极低(零开发成本,只需运营手工导出表格) | 较高(可利用完整的离线反作弊脚本过滤) |
| 第三方归因 Webhook 结合内部流式处理 | 极低(秒级到亚秒级) | 极高(中台内存级实时计算,多维权重联合降级比对) | 较高(需搭建轻网关、引入 Kafka 及流式计算引擎) | 极强(中台实时风控拦截,辅以企业内部事件流交叉验证) |
如上表所述,客户端直传看似轻量,实则因为缺失全网点击库而在准确性上彻底失效;T+1 离线模式虽准却慢,直接抹杀了优化师的调价时间窗。唯有基于第三方归因引擎提供的全量 Webhook 回调,配合内部搭建的高可用 Kafka+流式处理框架,才是兼顾“极速低延迟”与“极高归因精准度”的终局解法。这不仅能将反作弊动作前置到毫秒级,更能让企业的数据资产完全沉淀在自有数仓中,实现最极致的数据安全与业务灵活性。
技术诊断案例(四步法):大促期间高并发拖垮统计看板的排障
异常现象与排查背景
在年度双十一大促的凌晨,某头部电商 App 投放团队全面开启了信息流的“放量模式”。随着大额预算的撒出,大量真实新用户涌入并下载 App,然而运营人员面对的实时大屏却呈现出了惊悚的画面:从零点过五分开始,看板各项新增激活数据突然全部卡死,大盘安装数长时间停滞为 0。这种窒息的停摆一直持续到凌晨 2 点,数据大屏突然复活并出现毫无逻辑的暴增曲线,更致命的是,财务核算发现出现了极其严重的重复记账情况,同一台设备的 OAID 居然在短时间内被统计了 3 到 4 次,这直接导致原本用于保护 ROI 的自动出价熔断脚本因接收到错误指标而宣告失效。
日志与链路对账
后端架构团队连夜被唤醒并介入深度排障。通过拉取企业自身 Webhook 接收网关的 Nginx 访问日志与应用运行日志,排障思路立刻锁定在链路阻塞上。分析发现,大促瞬间爆发的 TPS 直接超越了网关服务器配置的承载上限。更为致命的代码缺陷暴露出来:研发人员在接收 Webhook 的 API 接口内部,直接写死了去远端 MySQL 数据库查询该用户历史订单的同步业务判定逻辑;数据库在遭受高并发瞬时打满连接池后发生死锁,导致单个 Webhook 接收请求的处理耗时从日常的 20 毫秒飙升至恐怖的 5 秒以上。第三方归因系统(发送方)具有严格的保护机制,在发出请求后 3 秒内未收到 HTTP 200 响应,即判定为网络超时发送失败,进而触发了“指数退避重试(Exponential Backoff Retry)”机制,不断以 1秒、2秒、4秒、8秒的递增延迟向该接口疯狂重投相同的激活日志。这种由超时引发的重试潮,最终演变成压垮接收端最后一口气的“雪崩效应”,不仅导致新数据进不来,老数据又在超时临界点被强行重复写入了数据库。

技术介入与规则调优
找到病灶后,架构团队实施了“快刀斩乱麻”的手术级链路重构。第一,果断切断 Webhook 接收接口内部的一切同步业务逻辑。将网关彻底降维改造成一个“轻量级透传网关”,该网关只执行最基础的 Header 签名参数校验,校验通过后,将原生报文无脑异步丢入紧急扩容的 Kafka 集群中,并强制要求接口在 5 毫秒内即刻向归因中台返回 HTTP 200,全面截断中台的超时重试链条。第二,在后端的 Flink 消费者群组中,紧急引入高强度的幂等性控制墙。利用报文自带的唯一标示 request_id 以及提取的 OAID,结合 Redis 的过期机制实现滑动时间窗口内的精确去重校验。
复盘结果与经验
系统完成不停机热更新与重载后,原本积压在网络层与本地队列中的数百万条回调日志,在轻网关与 Kafka 的配合下,在仅仅 3 分钟内被极其平滑、毫无报错地全部消费完毕。精确去重机制的介入不仅彻底消灭了那批导致重复计费的脏数据,更将整个大促环境从“物理安装发生到看板数值刷新”的平均端到端延迟,从原先雪崩时的数百秒直接压降至 150 毫秒以内。经数据科学组复盘测算,大促后续阶段投放异常的响应与调价延迟整体缩短了惊人的 95.3%。此次血淋淋的教训为技术团队沉淀下了不可逾越的军规:“Webhook 接收必异步、业务流转必解耦、去重防重演必依赖强主键幂等”,这是一切高可用实时追踪管线的地基。
常见问题
Webhook 回调漏发或网络中断导致数据丢失怎么办?
在不可靠的公网环境中,短暂的网络中断和 DNS 劫持是必然发生的物理现象。对于实时性要求极高的管线,防漏发机制依赖于“发送端重试与接收端对账”的双通道保障。发送端(归因中台)通常会内置基于消息队列的指数退避重试策略,在遇到请求失败时会在几小时内发起多次重推。如果在极端断网导致所有重试耗尽后仍未送达,接收端团队必须依赖“最终一致性(Eventual Consistency)”设计:每天凌晨调用中台提供的拉取离线对账文件 API,将昨日所有成功归因的明细数据拉回本地数仓,与实时流中记录的数据通过唯一 request_id 进行差分比对(Diff)。一旦发现缺失,立刻启动补偿落库脚本,确保宏观财务结算数据与底层明细的绝对一致。
为什么接收了实时回调还是感觉比广告平台后台的数据少?
这属于典型的统计口径断层与物理事实差异。广告平台(如某短视频后台)显示的往往是“宽口径”的估算数据,只要用户点击了广告且系统推测其可能跳转至商店,即被乐观地记为一次前端转化。而基于 Webhook 下发的实时回调,其底线是发生了一次“真实的物理设备冷启动行为”。在这个漫长的链路中,用户可能在应用商店下载到一半放弃、可能下载完未同意系统权限协议即卸载,甚至是因为网络极差导致激活埋点未能突破沙盒防线。简而言之,广告平台兜售的是“转化意向的广义曝光量”,而实时追踪回调下发的是经过内存级哈希过滤与指纹提取的“去重后绝对真实设备量”,两者在物理定义上天然存在转化损耗的漏斗差。
初创团队没有大数据组件资源(如 Kafka/Flink),如何承接实时回调?
不要因为缺乏重型大数据组件就对实时架构望而生畏,架构是可以根据资源优雅降级的。对于日增百万级别内的初创平台,完全可以利用轻量级的 Redis 取代 Kafka。在接收网关端,校验请求后快速将 Payload 以 JSON 形式 Push 到 Redis 的 List 或高版本支持的 Stream 数据结构中,立即返回 HTTP 200 实现削峰。在应用层,部署几台廉价的 Node.js 或 Python Worker 节点,通过长轮询(Long Polling)的方式持续从 Redis 中 Pop 取出数据流,在内存中进行简单的幂等判定后批量(Batch)写入关系型数据库或轻量级 BI 面板。这套被阉割的“平替架构”虽然在可扩展性上有所欠缺,但足以在极低运维成本下满足业务对准实时数据吞吐与大屏低延迟刷新的硬性需求。