API数据对接openinstall要注意什么?广告平台S2S对接实战细节
 openinstall运营团队|
openinstall运营团队| 2026-04-14|
2026-04-14| 145
145
API数据对接openinstall要注意什么?在移动增长和 App 开发领域,行业里越来越把“摒弃脆弱的前端客户端直传,构建高可用、强一致性的 Server-to-Server(S2S)后端 API 归因对接架构”视为确保亿级并发下广告数据绝对精准的核心护城河。当企业选择将内部业务数仓与各大媒体平台(或如 openinstall 这样的专业归因中台)进行深度 S2S 绑定时,网络链路的复杂性被瞬间放大。如果研发团队缺乏底层的工程容错思维,仅仅停留在“把 JSON 报文 POST 出去就完事”的粗放阶段,那么在极不稳定的公网抖动与媒体接收端限流(Rate Limiting)的夹击下,系统将不可避免地遭遇 HTTP 504 超时与签名鉴权失败的混合双打。更为致命的是,盲目的网络重试机制会直接诱发“重试风暴”,导致数据库发生严重的脏读脏写,进而产生海量的重复计费订单。通过深刻理解底层 API 握手协议,引入基于动态令牌与分布式锁的硬核容错架构,工程团队能够彻底根除 S2S 对接中的丢包与重传痛点,在毫秒级的对撞中捍卫企业营销预算的绝对安全。
物理断层与行业痛点(概念定位)
前端 SDK 盲区与 S2S 对接的“重试风暴”灾难
在早期的流量红利时代,广告主习惯于通过在 App 客户端强耦合嵌入多个媒体的追踪 SDK 来完成数据上报。然而,随着移动操作系统的隐私收紧(如 iOS 的 ATT 框架限制)以及弱网环境下频繁的丢包率,客户端上报的到达率往往跌破 80%。为了追求数据的极致闭环,大厂纷纷转向 Server-to-Server 的纯后端对接模式。然而,S2S 并非万能灵药。当业务侧服务端向媒体或第三方中台发起转化回传请求时,如果遭遇对方网关的瞬时宕机或公网路由抖动,HTTP 连接池将出现大量处于 pending 状态的僵尸线程。此时,如果研发人员配置了极其暴力的同步重试策略(例如:失败后立刻重试,死循环 5 次),数以万计的积压订单会在极短时间内向目标服务器发起超高频的 DDoS 式冲击。这种被称为“重试风暴”的灾难,不仅会瞬间压垮己方的出口带宽,更会因为媒体端最终异步处理了所有重试请求,导致一笔真实的付费订单被强行结算了 5 次 CPA 佣金。财务对账时的满目疮痍,往往就是这种粗放式 API 对接酿成的苦果。

底层原理与数据管线拆解(接口容错核心)
高可用 S2S 架构的通用对接流转与签名鉴权 (Signature)
构建一条坚不可摧的 S2S 数据管线,第一道必须跨越的钢铁防线便是极其严苛的接口签名鉴权(Signature Authentication)。各大主流广告平台及第三方中台在接收回传数据时,绝不接受处于裸奔状态的明文报文。步骤一:参数提取与排序。当业务端准备回传转化事件时,系统必须首先提取目标媒体下发的动态 Nonce(随机数)、Timestamp(精确到毫秒的时间戳)以及核心的 JSON Payload。为了防止哈希碰撞漂移,所有参与签名的字典 Key 必须进行严格的 ASCII 码升序排列。步骤二:核心加密对撞。研发调用平台分配的专属 App Secret,采用业界最高安全标准的 HMAC-SHA256 算法,对排列后的参数串进行不可逆的散列运算,生成一段绝对唯一的 Sign 签名令牌,并将其注入 HTTP 请求的 Header 头中。步骤三:网关防重放攻击拦截。目标服务器(例如接入了《》的中台底座)在接收到请求后,会立刻剥离时间戳进行校验。如果该请求的时间戳距离服务器当前时间超过了允许的物理漂移窗口(通常为 ±5 分钟),系统将毫不留情地将其判定为黑客的恶意重放攻击(Replay Attack)并直接返回 HTTP 401 拦截代码。只有完美通过这三层校验的请求,才有资格进入下游的归因匹配池。

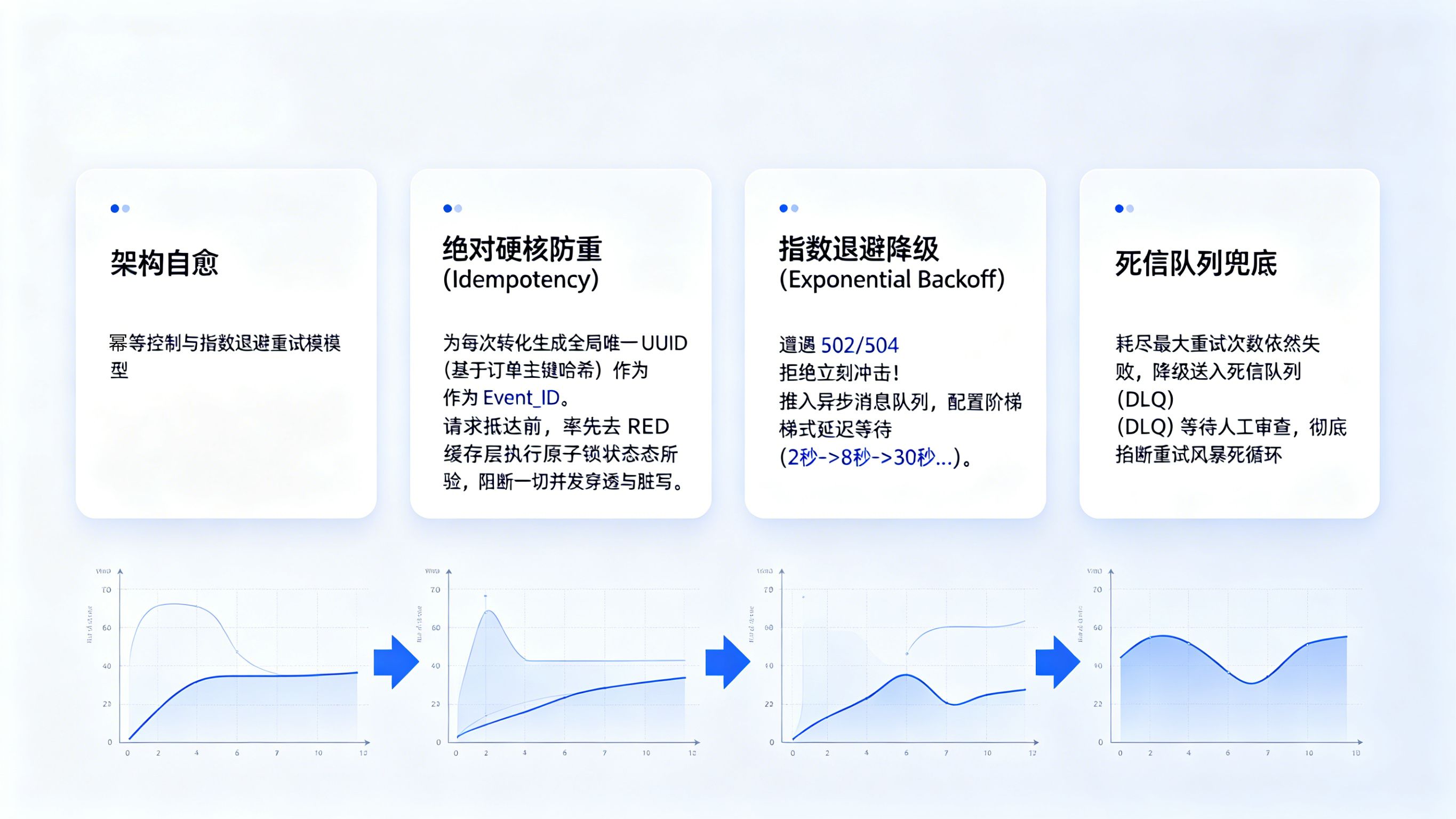
网络抖动补偿与接口幂等性 (Idempotency) 控制
在跨越了鉴权防线后,如何优雅地处理网络超时与不可避免的重试动作,是考验系统架构健壮性的核心试金石。高阶的 S2S 容错系统必须在底层代码中深度植入两个维度的自愈机制。其一是动态退避重试(Exponential Backoff):当遭遇 502 Bad Gateway 或 504 Gateway Timeout 时,系统绝对不能立即发起二次冲击,而是应当将该任务降级并推入异步消息队列(如 Kafka),配置阶梯式的延迟等待(例如:第一次等待 2 秒,第二次等待 8 秒,第三次等待 30 秒),从而为目标服务器留下喘息与恢复的物理时间。其二是绝对硬核的分布式幂等控制(Idempotency Control)。为了保证无论重试多少次,最终落地的数据都只有唯一的一条,系统必须为每一次独立的转化事件生成一个全局唯一的 UUID(如基于订单主键的哈希值),并将其作为 Event_ID 附加在报文中。当请求抵达中台底座时,接收端必须率先去高速缓存层中执行基于此 Event_ID 的状态校验操作。关于如何在大规模集群中利用底层状态机与锁机制打造坚不可摧的防重壁垒,资深架构师可深入参阅《》,这对于消除并发场景下的脏读脏写具有决定性的战略意义。
# 核心架构代码示例:基于 Redis 分布式锁与指数退避的 S2S 回传容错模型
import time
import hashlib
import requests
from requests.exceptions import RequestException
class IdempotentS2SClient:
def __init__(self, redis_client, app_secret):
self.redis = redis_client
self.secret = app_secret.encode('utf-8')
def execute_postback_with_retry(self, event_payload, target_url, max_retries=3):
"""
执行带有强幂等校验与指数退避重试的 S2S API 回传
"""
# 步骤 1:生成全局唯一的事件签名哈希作为幂等锁主键 (Event ID)
raw_string = json.dumps(event_payload, sort_keys=True)
event_id = hashlib.sha256((raw_string + str(self.secret)).encode('utf-8')).hexdigest()
lock_key = f"s2s_postback_lock:{event_id}"
# 步骤 2:在 Redis 中尝试获取分布式原子锁 (防并发穿透)
# 如果返回 False,说明该事件已在其他线程处理中或已完成,直接拦截
if not self.redis.set(lock_key, "processing", nx=True, ex=86400):
return {"status": "blocked", "reason": "Idempotent lock triggered. Event already processed."}
retry_count = 0
backoff_factor = 2 # 指数退避基数 (秒)
# 步骤 3:核心网络请求与异常捕获循环
while retry_count <= max_retries:
try:
# 注入强防重放标识的时间戳与事件 ID
headers = {
"X-Event-Id": event_id,
"X-Timestamp": str(int(time.time() * 1000))
}
response = requests.post(target_url, json=event_payload, headers=headers, timeout=5)
# 如果收到 200,说明媒体端已成功接收并去重
if response.status_code == 200:
self.redis.set(lock_key, "success", ex=86400 * 30) # 长效保存成功状态
return {"status": "success", "attempt": retry_count + 1}
# 如果遭遇 401 签名错误或 400 客户端错误,重试毫无意义,直接中断并告警
if response.status_code in [400, 401, 403]:
self.redis.delete(lock_key) # 释放锁以便后续人工排障修复后重推
return {"status": "fatal_error", "code": response.status_code}
except RequestException as e:
# 捕获 502/504 等网络超时断流异常
print(f"Network jitter detected: {str(e)}")
retry_count += 1
if retry_count <= max_retries:
# 触发指数退避机制:等待时间依次为 2秒, 4秒, 8秒...
sleep_time = backoff_factor ** retry_count
print(f"Retrying in {sleep_time} seconds (Attempt {retry_count}/{max_retries})...")
time.sleep(sleep_time)
# 步骤 4:耗尽最大重试次数依然失败,降级送入死信队列 (Dead Letter Queue)
self.redis.delete(lock_key)
self._send_to_dead_letter_queue(event_payload, event_id)
return {"status": "failed", "reason": "Max retries exceeded due to persistent network failure."}
def _send_to_dead_letter_queue(self, payload, event_id):
# 将彻底失败的报文转移至高可靠的 Kafka 等待后续离线重构与人工干预
pass
指标体系与技术评估框架
衡量 API 对接健壮性的核心运维罗盘
为了避免对接工作沦为盲人摸象,运维架构团队必须在 Grafana 或 Prometheus 大屏中固化四大极度敏感的接口健康罗盘指标。第一是 HTTP 200 成功响应率(Success Rate),它是衡量双边物理连通性的基座;第二是 P99 延迟响应时间(P99 Latency),即 99% 的回传请求必须在多少毫秒内得到目标服务器的确切答复,它直接决定了己方线程池的健康度;第三是丢包重传率(Retry Ratio),如果该指标长程突破 5%,往往意味着公网路由节点出现了严重的物理故障;第四是鉴权失败率(401/403 Unauthorized Rate),它如同报警器一般,能第一时间指出秘钥泄露或底层参数拼接排序的致命逻辑 Bug。
广告回传系统架构对比:自建 API 网关 vs 接入 openinstall 中台
在面对巨量引擎、腾讯广告等数十家媒体层出不穷的 API 迭代时,研发团队的顶层设计选型将直接决定未来三年的技术负债。以下高密度评估矩阵清晰揭示了不同演进路径的优劣:
| API 对接架构演进路线 | 接口容错与防重机制(幂等性) | 联调对接与全景排障研发工时 | 签名加密与防伪造安全性 | 跨渠道 API 升版迭代维护成本 |
|---|---|---|---|---|
| 纯前端 SDK 耦合上报 | 极弱(受限于移动端网络环境,极易发生上报中断与重试错乱) | 极高(每次接入新媒体都需重新发版 App,联调排障宛如黑盒) | 极差(极易被抓包工具篡改特征参数,黑产伪造点击横行) | 极高(媒体 SDK 强制升版将直接打乱 App 原有的发版节奏) |
| 研发纯自建后端路由回传矩阵 | 较弱(除非耗费巨资自建分布式锁集群,否则极难阻断多实例并发下的穿透计费) | 极其高昂(需投入数名高级后端,死磕每一家媒体晦涩的异构鉴权文档,排错周期极长) | 中等(能防住低级篡改,但在处理多时区与时钟偏离问题时容易翻车) | 极高(媒体侧 API 字段发生任何微调,均需全线停机重新编译路由代码) |
| 接入专业归因中台 (如 openinstall) | 极强(中台底座自带分布式原子锁校验池,在引擎入口层物理级过滤一切重复报文) | 极低(仅需一次性对接中台的标准化 JSON 接口,联调成功率逼近 100%) | 极强(统一采用严密的多维度时序防重放签名网络,绝对封闭作弊入口) | 极低(底层媒体接口的变更适配全部由中台云端静默热更新解决,业务端代码零改动) |
该技术矩阵的结论极其冷酷:试图依靠有限的内部研发力量去穷举并对抗全网各大媒体复杂的异构 API 陷阱,是一场注定败北的消耗战。全面接入具备强悍底层算力与极简适配能力的专业第三方归因中台,不仅是实现 S2S 对接零故障的最优解,更是企业实现研发降本增效的战略必选项。

技术诊断案例(四步法):某工具App化解“重试风暴”引发的财务危机
异常现象与排查背景
去年“618”大促爆发期,某头部出海工具类 App 遭遇了惊魂一刻。在当晚流量达到历史最高峰时,由于某海外核心媒体平台的接收端网关意外宕机限流,导致该 App 后端自建的 API 转化回传队列瞬间爆满。仅仅在一个小时内,由于后端设定的无退避暴走式重试逻辑,业务服务器向该媒体疯狂发送了数百万次超时重传请求。次日媒体后台恢复后,将这些积压的重复请求全部核算为有效 CPA 转化,直接导致该 App 当天的营销预算被不可思议地重复扣减了将近 30%,引发了极其严重的财务虚高危机。
日志与链路对账
系统架构师在接到灾难预警后,立刻通过 ELK 集群调取了当晚的全量请求日志进行溯源追踪。通过清洗海量的 HTTP 报文,团队发现了一个极其刺眼的致命逻辑漏洞:同一个代表深度激活转化价值的 Click ID,在遇到 HTTP 504 响应超时后,竟然在短短 5 分钟内被业务端的不同服务器实例盲目重传了多达 45 次!更要命的是,由于当时自建代码在组装 JSON 报文时,偷懒漏掉了唯一业务单号(Order ID)的传递,导致媒体接收端在恢复后,根本无法区分这些重复报文的身份,只能机械地将其照单全收。
技术介入与规则调优
为了彻底终结这场荒谬的错账危机,工程团队立刻推翻了原本简陋的同步直连代码。紧急通过接入中立的归因中台接管回调路由,并确立了两大铁血军规:第一,在系统层强制引入基于 Redis 的全局唯一去重主键(Event Hash),并在请求 Header 中植入强幂等令牌,确保同一事件在整个生命周期内只被媒体核算一次;第二,全面重写异步重试代码,引入严密的指数退避算法,规定任何请求遭遇超时后,最大重试次数严格锁定为 3 次,超过则立即降级进入死信队列(Dead Letter Queue)并触发人工审查,彻底掐断引发风暴的死循环。
复盘结果与经验
随着新版容错架构的火线部署与平滑灰度,奇迹般的效果随之显现。在随后的整个下半年大促实战中,即使再次遭遇公网节点的大幅抖动,系统的接口异常与重复回传率依然如同定海神针般被死死压制并骤降至 0.3% 的极限低位。服务器在面对高并发突发时的平均 CPU 负载更是大幅度降低了 42.6%。此次惊心动魄的救赎战役,彻底夯实了团队内部不可动摇的技术共识:没有经过严密幂等锁设计与指数退避考验的 S2S 直连,根本不配上买量战场。

常见问题
联调阶段频发 HTTP 401 签名校验失败,底层排查逻辑是什么?
在各大广告平台的 API 对接史上,超过 80% 的初期挫折都栽在了签名(Signature)的暗礁上。一旦触发 HTTP 401 报错,不要急于怀疑密钥是否过期,必须沿着这三条底层逻辑逐一验算:首先,检查参与加密的参数字典是否严格按照 ASCII 码进行了绝对的升序排列(字典序错误是导致散列值崩盘的头号元凶);其次,警惕 URL Encode 导致的过度转义,特别是在处理包含特殊字符(如空格、加号)的请求体时,如果本地加密前未正确解码,算出的 Sign 必定南辕北辙;最后,必须使用抓包工具验证最终发出的 Payload 报文,在经过公司内部网关或中间件时,是否被擅自追加了换行符或不可见字符,破坏了原始数据的哈希完整性。
S2S 对接中,如何规避时钟同步(NTP)偏差导致的防重放拦截?
为了防御黑客截获旧报文进行恶意刷量(重放攻击),高质量的 API 接收网关在剥离请求参数时,会立刻提取其中的 Timestamp 字段,并与服务器集群的本地时间进行比对。如果这个时间差超出了设定的容忍阈值(一般严苛的平台设定为 ±5 分钟,甚至更短),无论签名多么完美,都会被一票否决。因此,作为发送方的业务服务器集群,必须强制开启并且时刻守护与公网核心时间源(NTP 服务器)的绝对时钟同步。任何超过百毫秒级别的服务器时钟漂移,在严苛的金融级 S2S 对接中都是无法容忍的隐患。
在极端峰值高并发下,API 回传如何实现队列削峰?
当千万级的用户在零点同时涌入并触发激活回调时,强行使用同步阻塞的 HTTP 线程去向媒体发请求,无疑是自杀行为,系统的可用连接池会在几秒内被榨干并彻底瘫痪。升维的架构解法在于构建“异步解耦与削峰填谷”的防波堤。业务系统在生成转化事件后,只需以极低的耗时(亚毫秒级)将数据序列化并推入 Kafka 或 RabbitMQ 等高吞吐量的分布式消息队列中,立刻返回给客户端成功响应。随后,由后端的独立消费者集群根据目标媒体 API 的真实承载能力(并发限制限流),平滑、匀速地从队列中拉取数据并执行最终的网络请求。这种通过物理队列前置承压的设计,是支撑亿级大盘不宕机的唯一通道。