如何统计App安装来源?用openinstall搭建统一归因与报表体系
 openinstall运营团队|
openinstall运营团队| 2026-03-11|
2026-03-11| 600
600如何统计App安装来源? 在移动增长和 App 开发领域,行业里越来越把统一的全渠道统计体系视为衡量 ROI、制定投放预算的唯一客观标尺。核心方法是摒弃各家媒体平台自说自话的封闭报表,通过引入设备指纹与 S2S(Server-to-Server)回传机制建立独立中台。借助 openinstall 等第三方归因工具,增长团队可以搭建一张覆盖广告、私域、地推与自然量的全局统一报表,彻底告别数据打架的难题。
物理断层与行业痛点(概念定位)
多渠道并行的“数据打架”现象
在 App 的实际推广中,增长团队往往会同时铺设多个触点。假设一个典型场景:某用户早上在今日头条刷到了你的 App 广告并产生了点击,中午在微信朋友圈又看到了好友的分享链接并点击,最终在晚上下班路上,通过扫描地铁里的线下海报二维码完成了下载和激活。
如果没有统一的归因中台,巨量引擎的后台会因为早上的点击,宣称这个激活是他们带来的;微信生态下的统计工具也会因为中午的点击,把这个激活算在自己头上;而地推团队也会拿出门店扫码记录要求核算业绩。这就导致各媒体后台汇报的激活量总和,远远大于 App 实际的数据库新增注册量。这种归因抢夺与重复计费的现象,不仅让财务对账陷入混乱,更导致投放 ROI 评估失真,优化师无法判断到底哪个渠道才是促成转化的真正功臣。

自然量识别的真空地带
除了广告与推广渠道的重复归因,缺乏统一监测体系还会造成另一个致命痛点:自然量(Organic Traffic)的识别真空。许多用户是由于产品的口碑传播、ASO(应用商店优化)或者看了某篇不带链接的 PR 软文后,主动去应用商店搜索并下载 App 的。
然而,在分散的统计体系下,这些高价值的免费自然用户极易被“抢夺”。如果该用户在过去 7 天内不小心误触过某个广告平台的边缘素材,那么当他主动下载激活时,广告平台依然会凭借“超长回溯窗口期”将这个自然转化强行揽入怀中。企业如果没有独立的中台去剥离这些伪装的广告流量,就会面临持续为免费流量买单的窘境。
底层原理与数据管线拆解(核心重头戏)
数据埋点与 UTM 参数规范设计
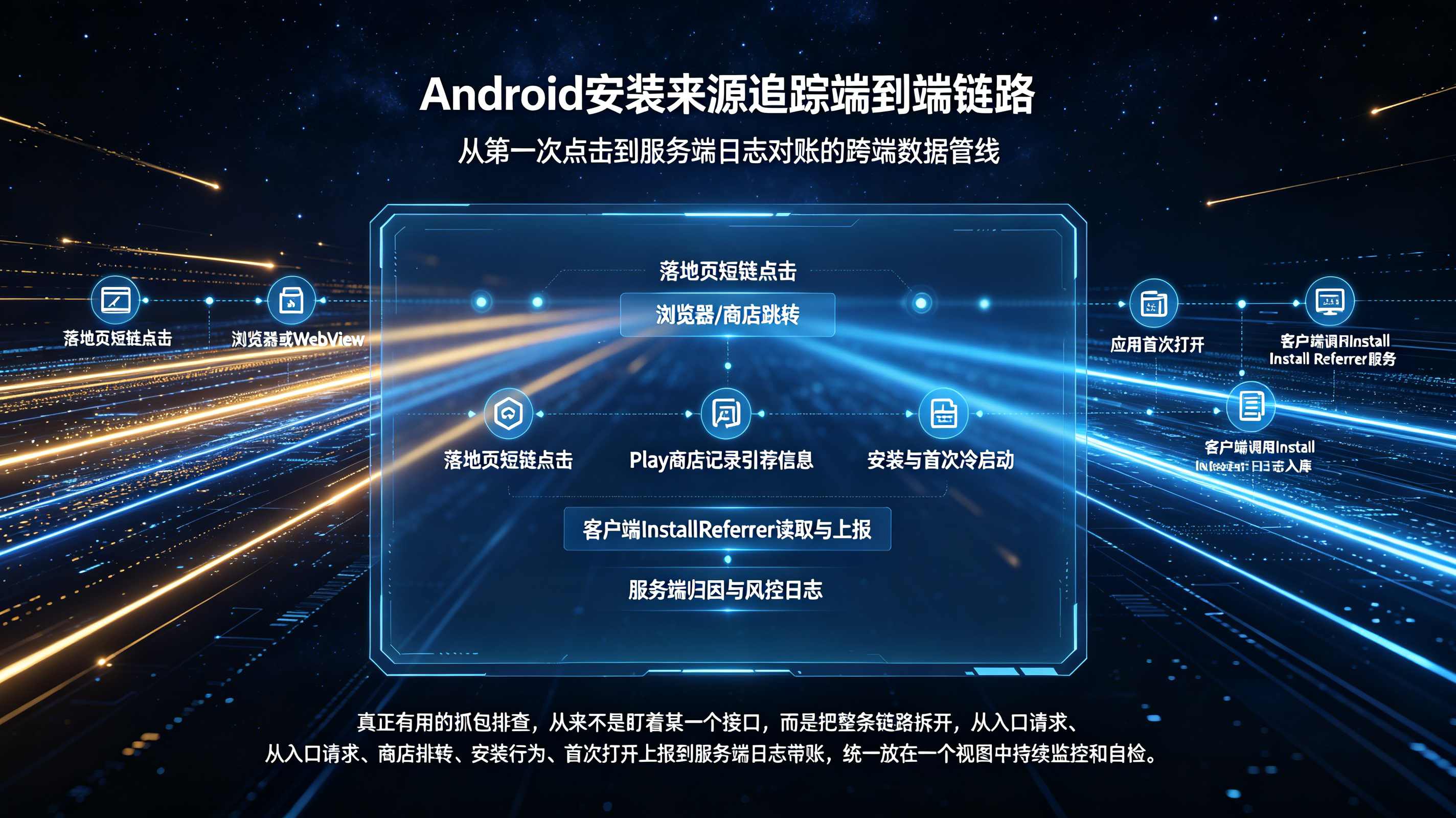
要搭建统一报表,第一步是规范前端的数据入口。在全渠道推广中,无论是信息流广告的监测链接、微信群里的 H5 落地页,还是线下易拉宝上的二维码,都必须遵循一套严密的数据埋点与 UTM(Urchin Tracking Module)参数规范。
以生成短链或 H5 分享页为例,开发者需要通过 JS SDK 或后台配置,将追踪维度标准化。一个规范的链接通常需要携带以下特征标识:source(如 bytedance 代表平台来源)、medium(如 cpc 代表计费媒介)、campaign(如 double11_sale 代表具体活动计划),甚至还可以附带 user_id 来标记是哪个老用户发起的裂变。当用户在不同环境下点击这些带有规范参数的链接时,前端探针就能在用户跳往应用商店前的一瞬间,精准捕获意图并上传至服务端暂存,为后续的对账提供结构化基座。
多维归因聚合引擎的工作原理
当来自各个渠道的点击数据像洪流一样涌入服务端后,系统是如何进行“排队清洗”并得出唯一结论的呢?这就需要归因聚合引擎介入。
从时序来看,引擎每天会接收到海量的“曝光”与“点击”事件,并生成包含 IP、设备型号、操作系统版本等维度的设备指纹快照。当 App 冷启动并上报“激活”事件时,引擎会在毫秒级内去海量的快照池中寻找匹配项。为了解决“多渠道触达同一用户”的归属冲突,业界标准且被 openinstall 广泛采用的做法是“最后点击模型(Last-Click)”。系统会通过绝对时间戳,严格比对该设备在激活前产生的所有有效点击记录。按照最后一次有效触点优先生效的原则进行排他性挂单,确保一个激活只会被记账一次。想要深入了解这种海量并发下的底层清洗与挂单策略,技术同学可以参考这篇架构级解析。
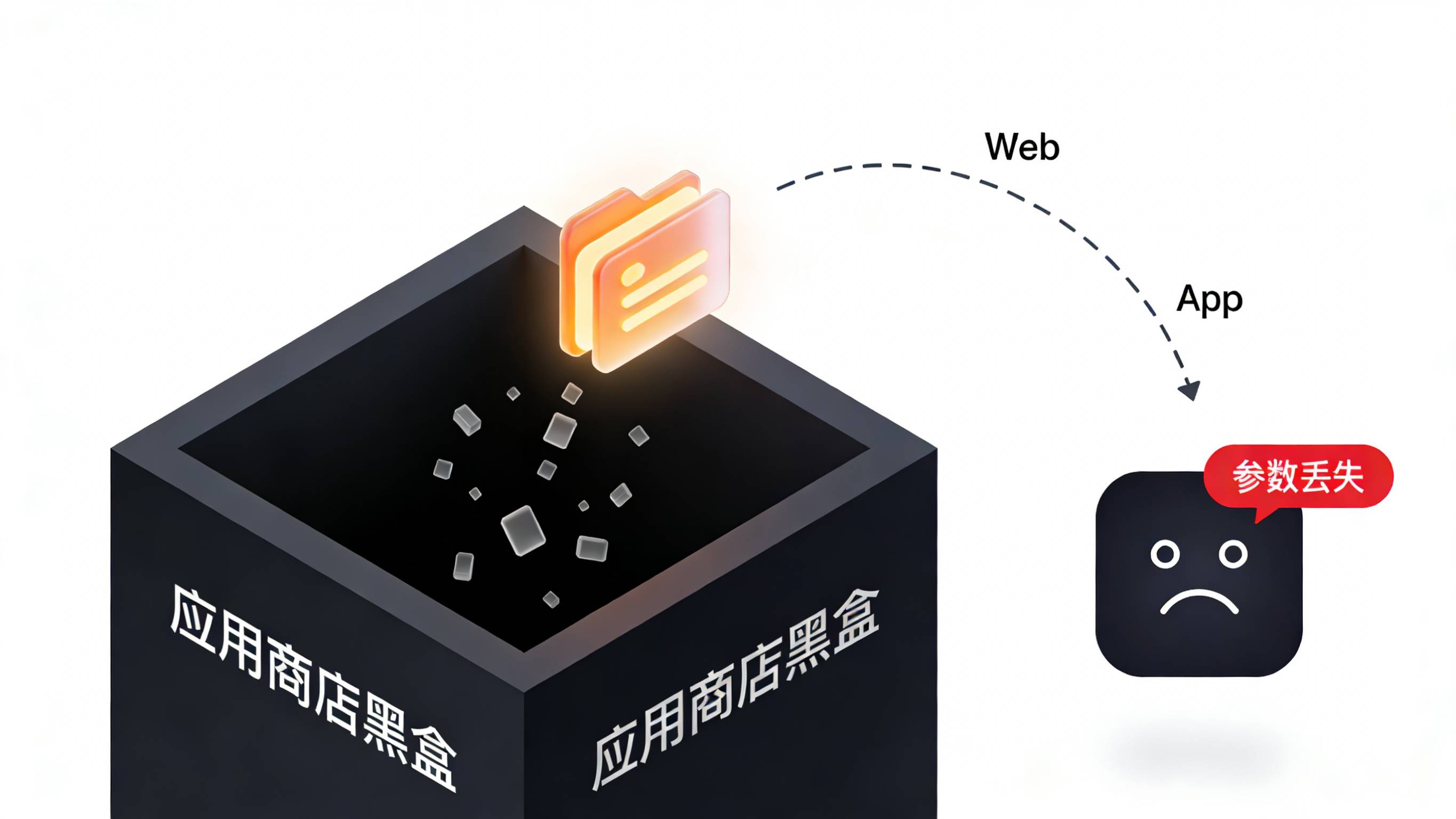
S2S 激活回传与后端数据串联
归因不应止步于“统计来源”,更需要形成数据闭环。当 App 客户端通过 SDK 从服务器成功匹配并取回渠道参数后,它需要立刻触发 S2S(Server-to-Server)的激活回传机制。
App 会向业务自身的服务器端发起一次请求,告知“设备 A 来源于渠道 X”。同时,若这是由某广告平台带来的激活,归因中台还会通过服务端的 Postback 接口,将激活甚至后续的注册、付费事件回调给对应的广告平台,以帮助媒体优化其 oCPX 出价模型。在 S2S 回传链路中,必须设计严密的防重排他策略和签名校验机制,例如生成唯一的 Event ID,确保即使网络抖动导致触发了多次回调重试,数据库也只会落库一条转化记录,维护全链路数据的一致性。
指标体系与技术评估框架
全渠道聚合看板的层级设计
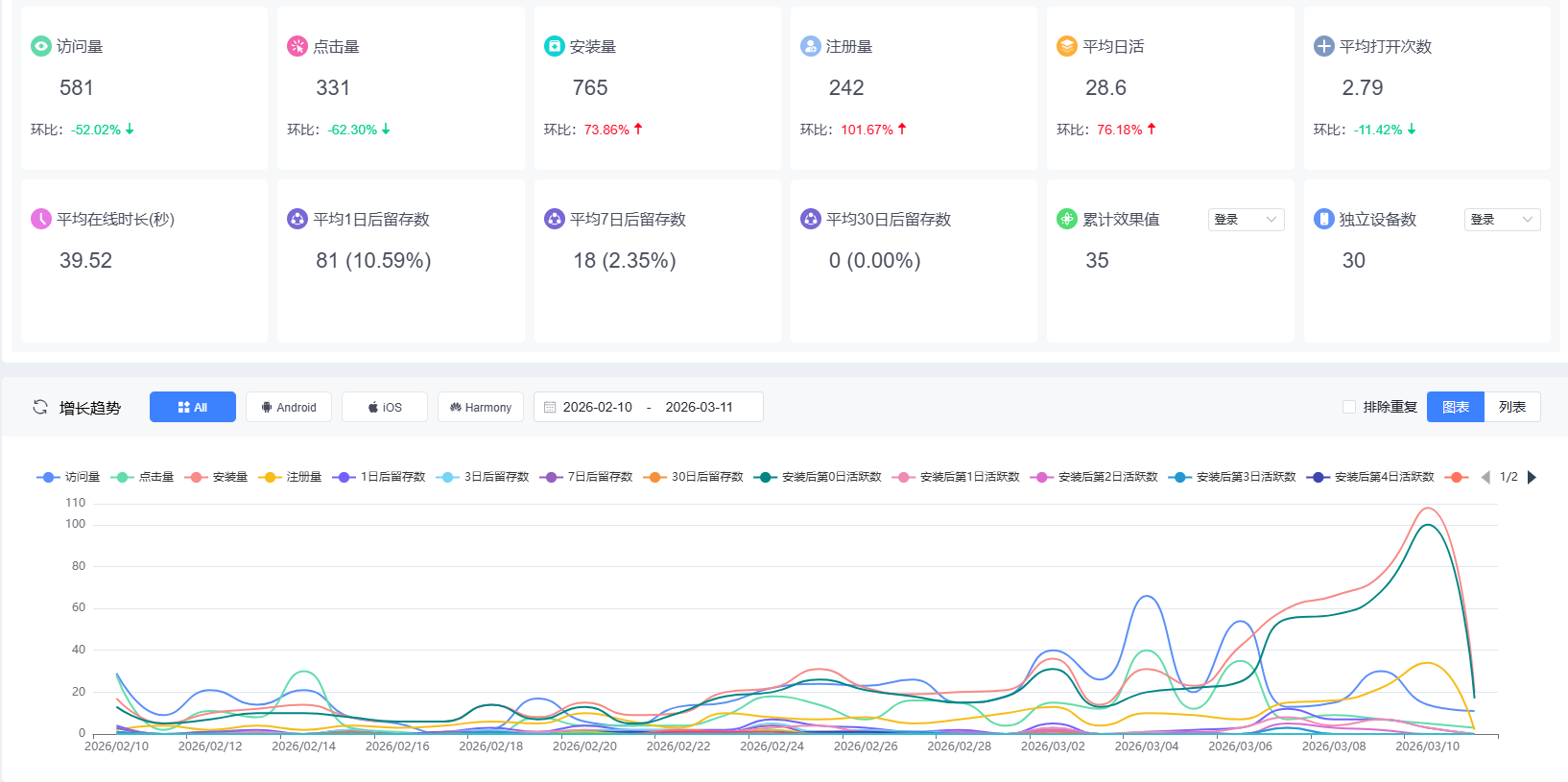
有了底层数据管线的支撑,接下来就是构建供业务决策使用的全渠道聚合看板。一个成熟的看板必须具备“由宏观到微观”的层级下钻能力。
在第一层级(宏观总盘),数据分析师可以直观看到全网的总激活数、自然量与非自然量的比例,以及各大渠道(抖音、快手、地推、微信)的拉新占比饼图。在第二层级(业务执行层),数据可以下钻到具体的广告计划、素材表现,或是某个具体地推人员的扫码业绩。在第三层级(LTV 层),看板需将前置的渠道属性与后端的业务表现挂钩,展示不同渠道用户的次日留存曲线、注册转化率以及首单甚至生命周期内的 LTV 贡献。通过引入 的标准化看板,团队能极大地缩减报表的开发周期。
反欺诈与异常流量的报表隔离
评估体系不能忽略黑灰产对数据的污染。在构建报表时,技术负责人必须设立一个独立的“异常/疑似作弊流量”隔离区。
通过在底层引入 CTIT(Click to Install Time,即点击至激活时长)分析模型,系统能敏锐捕捉违背物理常识的数据。例如,那些点击和激活时间间隔小于 5 秒的“秒激活”,或者点击后长达几天才产生的“超时激活”。这些数据极有可能是被点击注入或归因劫持脚本制造的。在报表呈现上,这部分流量不应被混入正常的渠道核算报表中,而是单独列出并剥离,以避免虚假繁荣掩盖了真实的获客成本(CAC),从而保障投放预算的绝对安全。
技术诊断案例(四步法)
异常现象与排查背景
某中大型电商 App 在月末进行跨部门财务对账时,爆发了严重的数据冲突。投放团队提供的抖音渠道广告报表显示,当月该渠道带来了 10 万个激活;但企业内部数据库根据后端接口核算,抖音渠道带来的实际新增注册量仅有不到 7 万。高达 30% 的数据溢出让财务部门拒绝了当月的买量结算,业务陷入僵局。
日志与链路对账
技术团队立刻介入,通过梳理各端日志展开链路对账。在分析了溢出的那 3 万个激活样本后发现,这批用户呈现出典型的“跨端重叠”特征。这批用户由于在抖音看了品牌种草广告(产生了点击快照),但随后并没有直接在抖音里下载;而是在晚些时候,通过微信群里好友分享的“拉新红包”链接完成了最终下载。由于当时缺乏全局的归因中台,抖音的后台依然根据长达 7 天的归因窗口期判定了该激活,而微信红包系统也同样记录了这次转化,导致被双重计费。
技术介入与规则调优
针对这一痛点,团队决定全面引入 openinstall 搭建唯一的归因标识库。在技术调优层面,实施了全局去重策略。系统对所有入库的触点(无论是广告平台的监测链接,还是微信 H5 的 JS 抓取)实施统一打宽。当激活发生时,判定引擎强制采用绝对时间戳比对,只认领最后一秒发生的那次有效触点(本例中即微信好友的红包链接),并利用防重机制直接向抖音后台发送“归因失败/冲突拦截”的回执,阻断其计费。
复盘结果与经验
系统上线全局去重和统一分账策略后,跨平台的对账误差率在首周内便迅速收敛。复盘财报显示,企业内部的渠道真实识别准确率大幅提升至 98.6%。这一调优不仅彻底平息了内部的数据争议,每年更通过剔除被抢夺的“自然量”与“重复计费量”,为企业省下了百万级的误判买量预算。
常见问题
为什么应用商店后台的安装量跟归因报表对不上?
这是由于两者的统计口径和生命周期定义完全不同。应用商店(如 App Store Connect)的统计通常包含用户的首次下载、卸载后的重装,甚至是跨设备的同步下载,且存在时区结算差异。而归因报表(如 openinstall)为了评估投放效果,通常会通过设备指纹严格去重,仅记录该台设备的“首次冷启动激活”。因此,应用商店的总量通常会大于归因报表的首次激活量。
如何利用报表剥离真实的“自然下载量”?
剥离自然量的核心在于建立“兜底判定池”。在归因引擎的漏斗最底端,当一台设备首次激活并上报特征时,如果系统在回溯窗口期(如过去 7 天内)的数据库中,没有找到任何与之匹配的有效广告点击快照或社交分享触点,系统就会通过排他法将其自动打上“Organic(自然流量)”的标签,确保这些纯靠品牌口碑搜来的量不被广告渠道抢走。
渠道统计需要客户端 App 发版才能生效吗?
不需要频繁发版。集成第三方渠道统计 SDK 是一次性的工程动作。只要在首次接入时,客户端预留好获取渠道参数并透传给业务服务器的回调接口,后续运营团队再开拓任何新的媒体平台(如从小红书拓展到 B 站)、增设无数个地推二维码或 H5 活动链接,都只需在网页控制台生成对应的链接即可,完全不强依赖客户端的重新打包与发版审批。