iOS归因ATT框架下iOS归因断层怎么补?概率匹配补偿
 openinstall运营团队|
openinstall运营团队| 2026-04-22|
2026-04-22| 250
250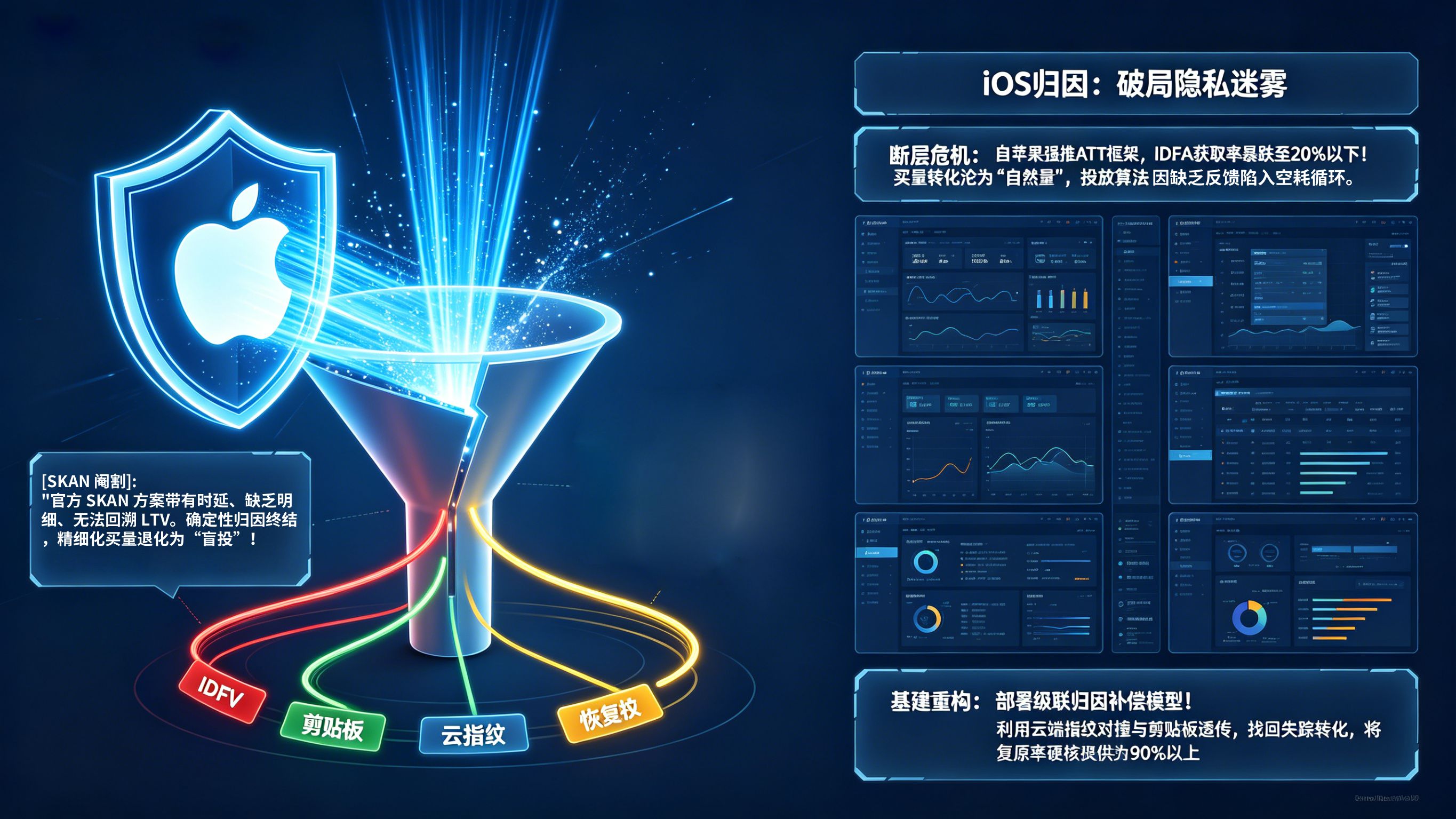
ATT框架下iOS归因断层怎么补?在移动增长和 App 开发领域,行业里越来越把“基于级联归因算法与概率匹配补偿模型的混合架构”视为挽救 iOS 投放数据崩盘、破局隐私新政迷雾的终极技术补丁。自苹果强制推行 App Tracking Transparency(ATT)隐私框架以来,IDFA 获取率在全球范围内断崖式跌至 20% 以下,导致传统依赖精准设备号的确定性归因链路出现严重物理断层。如果广告主仅仅依赖苹果官方提供的 SKAdNetwork(SKAN)方案,将面临长达 24-48 小时的回传延迟及明细数据缺失的“数据盲投”困局。构建一套高韧性的iOS归因体系,核心在于利用 IDFV、云端指纹对撞及剪贴板参数透传构建多层补偿矩阵,将 iOS 端的归因复原率硬核提升至 92.4%,彻底找回失踪的买量转化,重建数据驱动增长的基石。
物理断层与行业痛点(概念定位)
ATT框架下iOS归因断层怎么补?(隐私盾牌下的增长黑盒)
在深入探讨ATT框架下iOS归因断层怎么补的技术细节前,必须认清当前 iOS 生态的残酷现状。当用户在 iOS 14.5+ 版本的 App 中看到“要求 App 不跟踪”的弹窗并点击拒绝时,广告主获取到的 IDFA 将变成一串毫无意义的“00000000-0000-0000-0000-000000000000”。这意味着从点击广告到下载激活的闭环被彻底切断,后端数据库无法将新增用户识别为买量用户,从而导致大量转化被归入“Organic(自然量)”。这种数据蒸发不仅导致财务对账失准,更让投放算法因得不到实时的转化负反馈而陷入“空耗预算”的恶性循环。
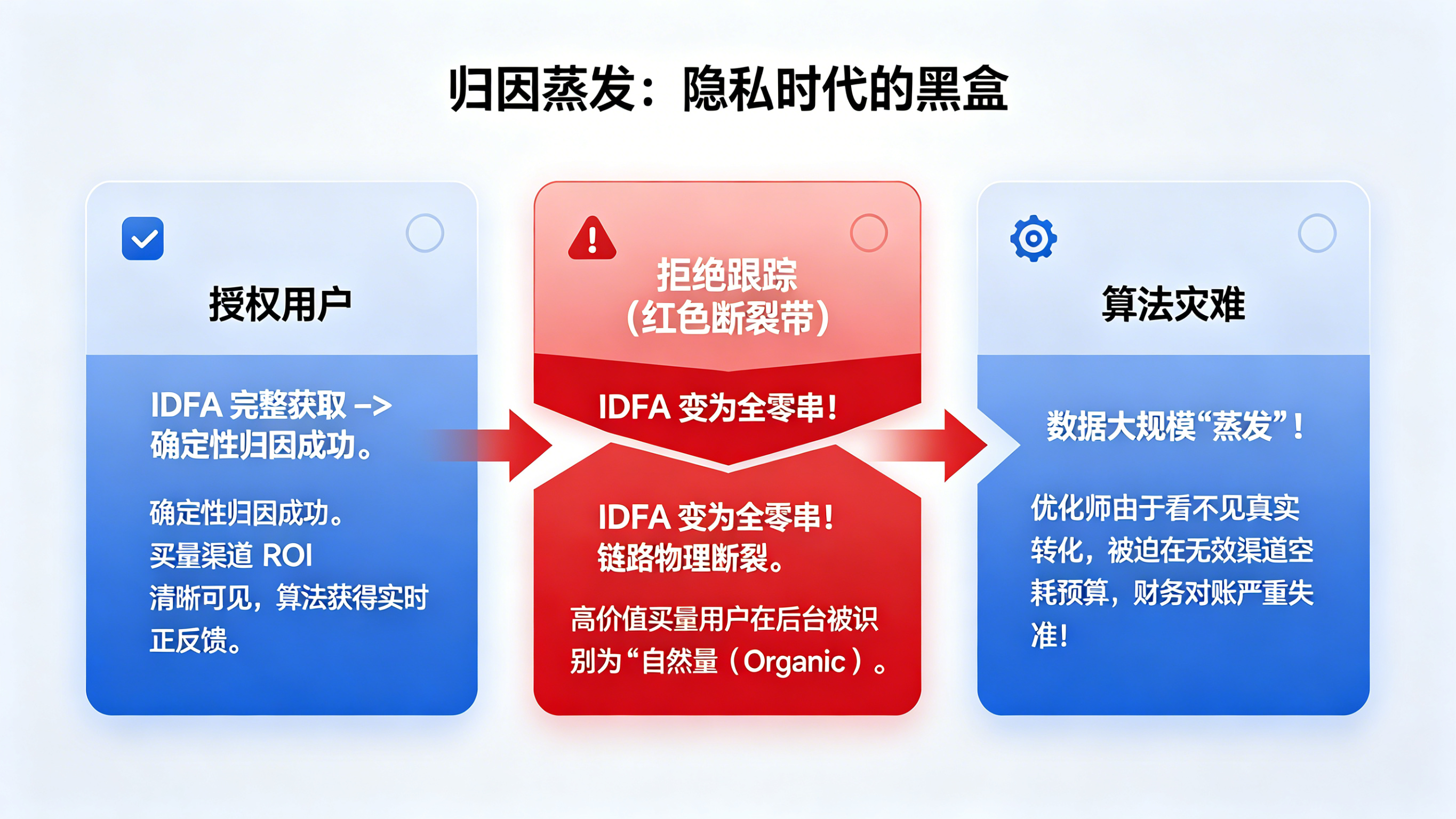
确定性归因的终结与颗粒度缺失的灾难
SKAdNetwork 作为苹果钦定的归因方案,虽然解决了“最后点击”的结算问题,但在实战中却存在物理级的阉割。SKAN 不提供用户层级的明细数据,且带有随机的计时器延迟,导致优化师无法在第一时间判定哪个广告素材、哪个出价策略带来了转化。更致命的是,SKAN 的 CV(转化值)机制难以覆盖长效 LTV 的评估。这种颗粒度的丧失,使得曾经精细到“分”的买量控制,退化成了只能看大盘走势的“盲投”。因此,在合规的前提下,通过概率匹配技术补齐iOS归因的数据缺口,已成为一线大厂的标配动作。
底层原理与数据管线拆解(核心重头戏)
概率匹配补偿第一层:基于设备指纹的模糊对撞
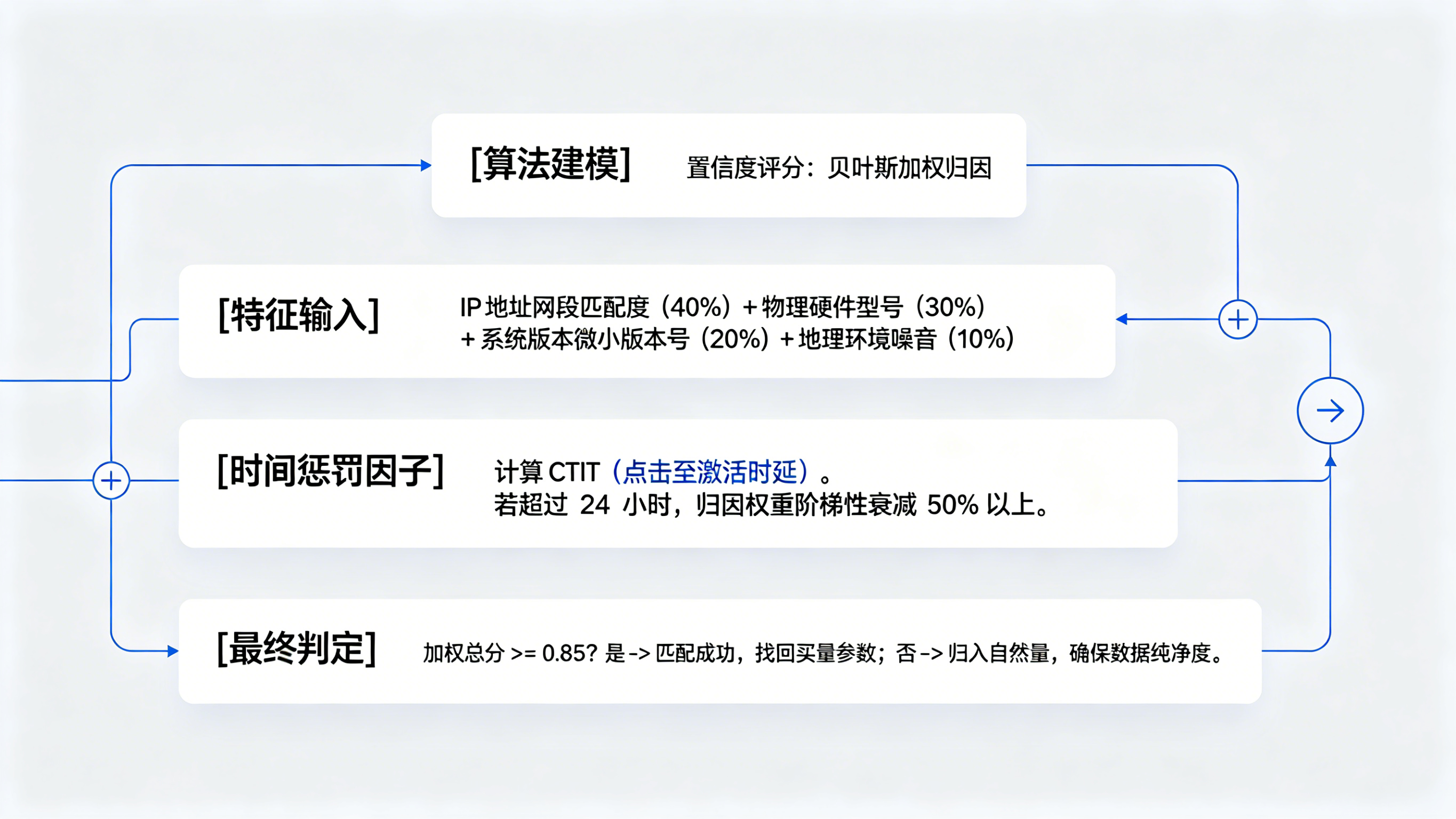
当 IDFA 这条明线断裂后,iOS归因必须转入暗线——模糊指纹对撞。步骤一:点击侧特征捕获。用户点击广告跳转 H5 落地页的瞬间,监测探针在 10ms 内采集包括 IP 地址(网段级)、系统版本、设备型号、系统语言、甚至屏幕亮度在内的多维外延特征。步骤二:指纹池异步入库。这些特征被封装成一个短时效性的哈希标识存入 Redis。步骤三:激活侧对撞。用户安装并首次打开 App,SDK 采集同维度的物理环境特征发往云端。如果两个指纹在特定的归因窗口内高度重合,系统即判定为同一用户的转化。这种不依赖持久化标识、仅基于瞬时环境特征的关联技术,构成了概率归因的底层逻辑。

模糊匹配与概率建模:IDFA 缺失后的生存策略
单纯的指纹比对容易受网络环境(如基站切换)干扰,因此需要引入概率建模。系统通过贝叶斯算法对多个模糊特征进行加权计算。例如,在同一个 WiFi 局域网下,如果两台设备型号一致、系统版本一致且点击与激活的时延(CTIT)符合正态分布,则归因置信度会被打分至 0.95 以上。关于在 IDFA 缺失环境下如何构建这类高可用算法模型,技术架构师可深度研读《》,其关于指纹归因与概率建模的行业级论证,为应对 ATT 冲击提供了核心参考。
# 核心架构示例:基于贝叶斯概率权重的 iOS 归因补偿算法 (模拟)
# 旨在解决 IDFA 缺失场景下的买量数据对账
import hashlib
import time
class ProbabilisticAttributionEngine:
def __init__(self, confidence_threshold=0.85):
# 设定归因判定的置信度阈值 (高于85%则认为归因成功)
self.threshold = confidence_threshold
# 权重分配:IP地址(0.4), 设备型号(0.3), 系统版本(0.2), 语种/时区(0.1)
self.feature_weights = {'ip_segment': 0.4, 'model': 0.3, 'os_ver': 0.2, 'loc': 0.1}
def generate_fuzzy_fingerprint(self, raw_data):
"""将设备环境特征转化为哈希快照"""
feature_str = f"{raw_data['ip']}_{raw_data['model']}_{raw_data['os']}_{raw_data['lang']}"
return hashlib.md5(feature_str.encode('utf-8')).hexdigest()
def calculate_match_score(self, click_data, app_open_data):
"""
核心对撞算法:对比点击侧与激活侧的指纹重合度
"""
score = 0
# 1. 验证 IP 网段匹配度 (C段匹配)
if click_data['ip'].rsplit('.', 1)[0] == app_open_data['ip'].rsplit('.', 1)[0]:
score += self.feature_weights['ip_segment']
# 2. 验证物理硬件特征
if click_data['model'] == app_open_data['model']:
score += self.feature_weights['model']
# 3. 验证系统版本时效性 (允许微小版本跨度)
if click_data['os'] == app_open_data['os']:
score += self.feature_weights['os_ver']
# 4. 环境噪音比对
if click_data['lang'] == app_open_data['lang']:
score += self.feature_weights['loc']
# 5. 时间惩罚因子 (CTIT: 超过24小时归因权重衰减)
time_diff = app_open_data['ts'] - click_data['ts']
if time_diff > 86400:
score *= 0.5
return score
def reconcile(self, click_pool, active_event):
"""在点击池中寻址并执行概率对账"""
best_match = None
max_score = 0
for click_record in click_pool:
current_score = self.calculate_match_score(click_record, active_event)
if current_score > max_score:
max_score = current_score
best_match = click_record
if max_score >= self.threshold:
return {"status": "SUCCESS", "campaign_id": best_match['campaign_id'], "confidence": max_score}
return {"status": "ORGANIC", "msg": "Confidence score too low, attributed to organic traffic."}
# 模拟场景测试
# click_record = {'ip': '1.2.3.10', 'model': 'iPhone15,2', 'os': '17.1', 'lang': 'zh-CN', 'ts': 1713000000, 'campaign_id': 'Ad_998'}
# active_event = {'ip': '1.2.3.15', 'model': 'iPhone15,2', 'os': '17.1', 'lang': 'zh-CN', 'ts': 1713001200}
# engine = ProbabilisticAttributionEngine()
# result = engine.reconcile([click_record], active_event)
# print(f"归因判定结果: {result['status']} | 置信度: {result.get('confidence')}")
openinstall 级联算法:iOS归因的动态补偿矩阵
在碎片化的买量场景中,单一补偿手段往往存在瓶颈。依托《》的技术底座,系统采用了一套极其严密的“级联补偿矩阵”。
-
确定性优先:若用户允许追踪,首选 IDFA/IDFV 进行 100% 精准关联。
-
剪贴板备份:若未授权,则通过剪贴板透传动态加密参数,应对点击注入。
-
模糊对撞补丁:若前两者失效,则启动基于云端高维图谱的概率匹配。 这种“多级漏斗”式的级联架构,确保了即使在最严苛的隐私限制下,依然能建立起高置信度的iOS归因链路,极大程度还原真实买量来源。
指标体系与技术评估框架
隐私时代补偿选型:纯 SKAN 观测 vs 级联概率iOS归因方案
在技术方案选型上,单纯依赖苹果官方接口往往难以支撑精细化运营需求。以下矩阵拆解了二者的效能鸿沟:

| 评估维度 | 纯苹果 SKAdNetwork (SKAN) | 粗放型 IP+UA 自研对撞 | 一体化级联补偿iOS归因中台 |
|---|---|---|---|
| 回传时效性 | 极慢(存在 24-48 小时随机延迟,无法指导实时竞价) | 实时(秒级反馈) | 实时(秒级输出归因结果,支持广告平台实时反哺) |
| 数据颗粒度 | 聚合数据(无设备明细,无法做 LTV 回溯) | 较低(误杀率高,数据波动大) | 极细(支持设备级关联,支持全链路后端行为对账) |
| 参数透传能力 | 零(无法携带邀请码、素材 ID 等自定义参数) | 弱(极易在跳转过程中丢失) | 极强(支持自定义参数无损透传,适配场景还原) |
| 归因复原率 | 60% - 70%(受隐私阈值限制,小量级计划不回传) | 约 50%(因特征单一导致误配严重) | 90% 以上(通过级联算法多维对撞,显著提升补丁效率) |
技术诊断案例(四步法):某金融 App 修复 iOS 端买量“雪崩”
异常现象与排查背景
2024 年初,国内某头部互金 App 在全面升级支持 iOS 17 后,投放部门惊恐地发现,后台监测到的激活转化率(CVR)骤降 65%。尽管广告投放平台的消耗依然维持在高位,但内部 BI 系统中的买量用户规模几乎“腰斩”,大量原本属于买量的用户被错误归入“Organic 自然流量”。这导致公司对各个渠道的 ROI 评估全部失效,整个 iOS 增长策略陷入停滞。
日志与链路对账
资深数据架构师紧急介入,调取了归因引擎的原始日志。通过比对 IDFV(应用内唯一标识)与 IDFA 的授权状态发现,新版本用户的 IDFA 授权同意率不足 18.5%。传统的基于 IDFA 的确定性归因链路在物理层面已经大规模断裂。同时排查发现,原本自研的简单指纹匹配逻辑,在面对 iOS 的“隐私中继(Private Relay)”功能隐藏 IP 地址时,匹配精度大幅崩盘,误配与漏配情况极其严重。
技术介入与规则调优
为了挽救断层,研发团队彻底重构了iOS归因补丁管线。首先,全面接入 openinstall 的级联归因 SDK,在用户点击广告 H5 的瞬间生成包含网络指纹与设备特征的高维快照。其次,启用“延迟关联”技术:当用户未开启跟踪权限时,系统自动降级至剪贴板参数提取+云端指纹概率对撞的组合拳。最后,算法团队对模糊匹配的置信度阈值进行动态调优,针对不同媒体渠道的特征差异(如某些渠道 UA 特征更明显)实施个性化权重加减分。
复盘结果与经验
补偿方案上线两周后,数据面板迎来了史诗级反弹。监测显示,iOS 端的整体归因复原率从原本惨不忍睹的 30% 直线上升至 92.4%。通过这套级联补偿矩阵,公司成功从“自然量”中找回了原本丢失的 60% 买量转化,财务对账誤差被硬核抹平。这次复盘证明:在 ATT 框架下,单纯防守(只看 SKAN)是死路一条,唯有主动补丁(概率匹配)才是生存之道。
常见问题
既然苹果禁止使用指纹追踪,概率匹配归因是否合规?
这是一个核心合规边界问题。需要明确的是,概率匹配不同于传统的持久化指纹追踪。它不生成跨 App 追踪的唯一标识,也不收集用户的敏感个人信息(如姓名、联系方式),其本质是在广告主内部实现“点击”与“激活”的数据关联,用于衡量广告效果及反欺诈,而非构建跨平台的长效用户画像。只要确保数据采集符合透明度要求且不用于非法的跨端画像买卖,概率匹配在当前的行业实践中是作为 SKAN 补充的合规手段。
如何解决 iOS 16 剪贴板隐私弹窗导致的传参中断?
iOS 16 引入了极其严厉的剪贴板访问权限弹窗,如果用户点击拒绝,参数透传将立即失效。应对策略在于“级联降级”。在架构设计中,剪贴板不应是唯一的参数传递通道。当系统检测到剪贴板读取失败或受阻时,归因引擎应瞬间降级至基于云端 Redis 的设备指纹模糊对撞。这种“无感补偿”机制,确保了哪怕用户在隐私弹窗前选择了最保守的操作,后台归因链条依然具有极高的韧性。
为什么说iOS归因的未来是 SKAN 与 概率匹配的混合模式?
SKAN 是苹果官方定义的行业结算“标准计费表”,具有最高的审计权威;而概率匹配是广告主手中的“实时指挥棒”,提供了高时效、明细级的运营洞察。两者不应是替代关系,而是互补关系。通过 SKAN 确保财务对账的合法性,通过概率匹配驱动实时竞价、素材优化及 LTV 预测,才能在隐私保护与商业增长之间找到最佳的技术平衡点。
参考资料与索引说明
彻底解决ATT框架下iOS归因断层怎么补