iOS渠道统计有哪些限制?ATT框架下的安装归因补偿与风控思路
 openinstall运营团队|
openinstall运营团队| 2026-03-19|
2026-03-19| 405
405
iOS渠道统计有哪些限制?在移动增长和 App 开发领域,行业里越来越把“在隐私合规前提下尽可能还原 iOS 渠道真实表现”视为买量决策与风控审计的生命线。ATT 框架正式落地之后,iOS 渠道统计被硬生生拆成了两套逻辑:一套面向同意授权的用户,可以依托 IDFA 做设备级、事件级的精细归因;另一套面向拒绝授权的用户,只能依赖 SKAdNetwork 提供的匿名、聚合、延迟回传的粗粒度数据。前者维度丰富但覆盖有限,后者覆盖广但信号粗糙,由此带来的数据撕裂和口径差异,几乎让所有 iOS 增长团队都经历过“报表永远对不上”的折磨。在这种大前提下,openinstall 这类第三方归因中台能做的,并不是回到“全量设备追踪”的旧时代,而是在苹果允许的规则空间内,通过授权率提升、SKAN 配置优化和多源对账,为团队构建一套可落地的补偿与风控思路。
物理断层与制度限制(概念定位)
iOS 沙盒与 App Store 分发导致的“黑盒渠道”
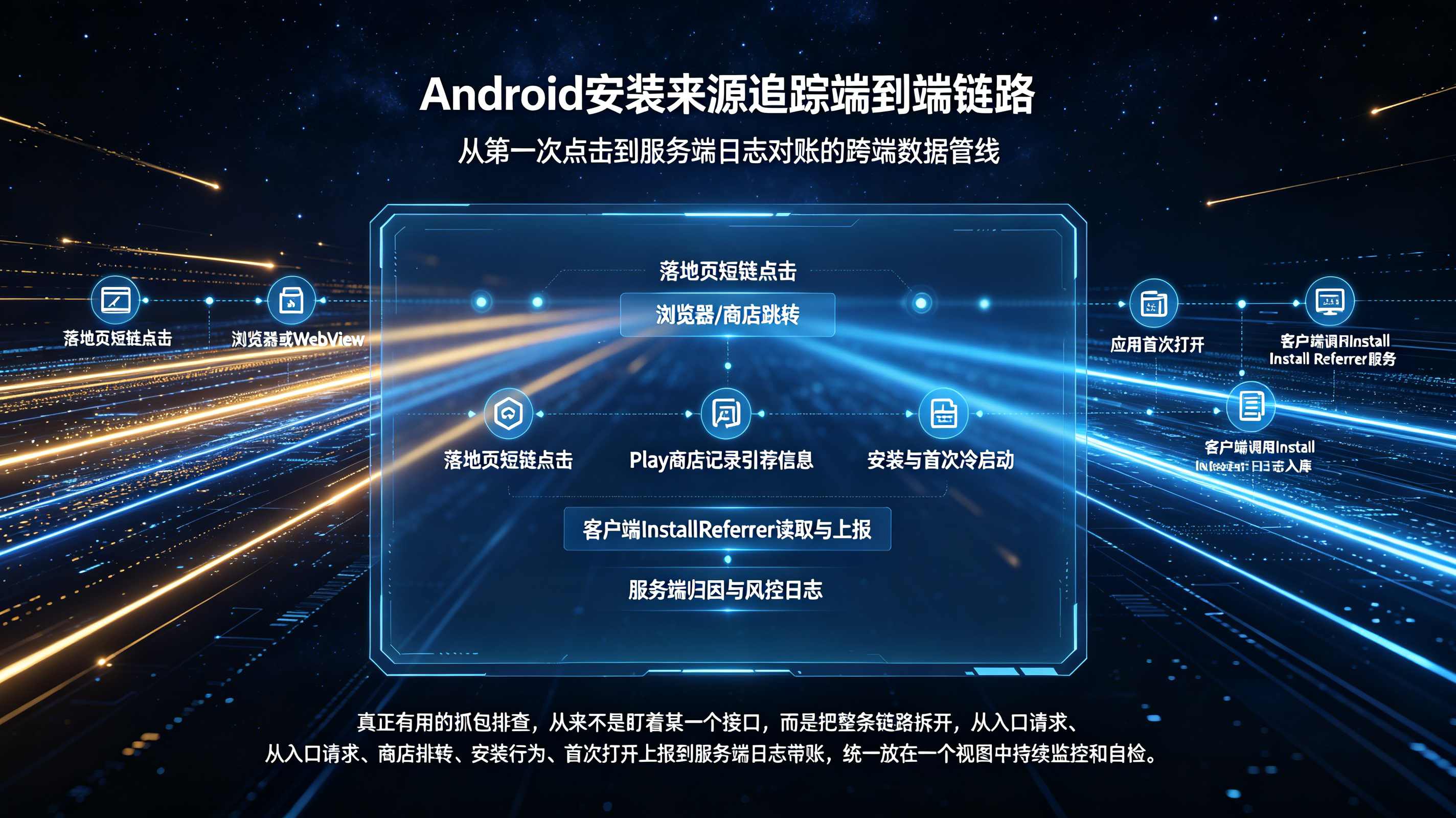
在讨论 ATT、SKAN 之前,必须先接受一个经常被忽视的前提:iOS 在“安装来源可见性”这一点上,天然就是一个比 Android 更黑盒的生态。对于 Android 而言,开发者可以通过渠道包、INSTALL_REFERRER 或各家商店的扩展字段,携带一定程度的来源信息到安装阶段;而在 iOS 世界里,整个下载安装过程完全由 App Store 一家托管,开发者既拿不到类似 INSTALL_REFERRER 的字段,也无法在安装包级别埋下任何渠道标记。用户在 Safari、微信内置浏览器或某个媒体 App 中点击推广链接,URL 尾部也许挂满了 utm_source、campaign_id 甚至用户 ID 等参数;但一旦系统将用户跳转到 App Store,对这些参数会采取“洗白”策略,只保留目标应用的页面信息和基础元数据,所有自定义参数全部丢失。等到用户数分钟后下载完应用并首次冷启动时,应用以一个“白纸状态”被唤起,既不能向系统 API 询问“我从哪来”,也无法逆向追溯那次点击链路,这就是 iOS 渠道统计的第一道物理级断层。

这种沙盒和分发机制带来的现实效果,是服务器侧根本看不到“从哪个广告、哪个页面直接引发了这次安装”的系统信号。能够依赖的只有在广告展示、点击时由媒体或第三方 SDK 主动上报的日志,以及 App 首启时 SDK 自行上报的激活事件。换句话说,iOS 上的“安装来源”从来就不是一个像 URL Referrer 那样由系统自动提供的字段,而是要靠广告链路两端的埋点,用各自掌握的时间戳和设备标识,事后在云端进行匹配,这也为后面引入 ATT、SKAN 等隐私政策后产生的各种错配埋下了伏笔。
ATT 弹窗与 IDFA 授权率带来的数据撕裂
在 iOS 14.5 引入 ATT 框架之前,行业惯常的做法是将 IDFA 视为 iOS 端最稳健的设备级标识:媒体端在展示和点击时记录设备的 IDFA 和广告信息,App 侧在首启时上报自己的 IDFA,第三方归因中台通过“IDFA 精确匹配 + 时间窗口校验”即可完成确定性归因。ATT 上线之后,这条链路被强制插入了一道“用户授权闸门”。每当 App 第一次尝试访问 IDFA,系统会弹出“是否允许此 App 跟踪你的活动”的弹窗;如果用户选择允许,App 得到的是一个可用的 IDFA,可以继续走原有的确定性归因路径;一旦用户选择拒绝,系统会返回一串全零 IDFA 或干脆屏蔽访问,从此这台设备就从“可精确追踪”的世界中消失。
更现实的问题在于,用户的选择并不会如广告主所愿那样一边倒地“允许”,而是呈现出明显的两极分化和分组差异。部分垂直品类、强品牌或高信任度产品,在精心设计弹窗时机和说明文案的前提下,ATT 授权率可以达到远高于行业平均的水平;而大多数普通 App,特别是对用户而言“不授权也能正常使用”的泛娱乐、工具类应用,其 ATT 授权率长期徘徊在二三成的水平。结果就是,同一条 iOS 渠道,在媒体后台看的是“靠曝光和点击日志估算出来的全量安装”,在第三方归因里看到的是“只覆盖那 20%–30% 授权用户的精确 install 样本”,在内部 BI 看到的则可能是“通过了风控、完成注册的真实用户”,三套报表天然脱节,数据撕裂也就难以避免。
底层原理与数据管线拆解(核心重头戏)
授权场景:基于 IDFA 的确定性多节点归因链路
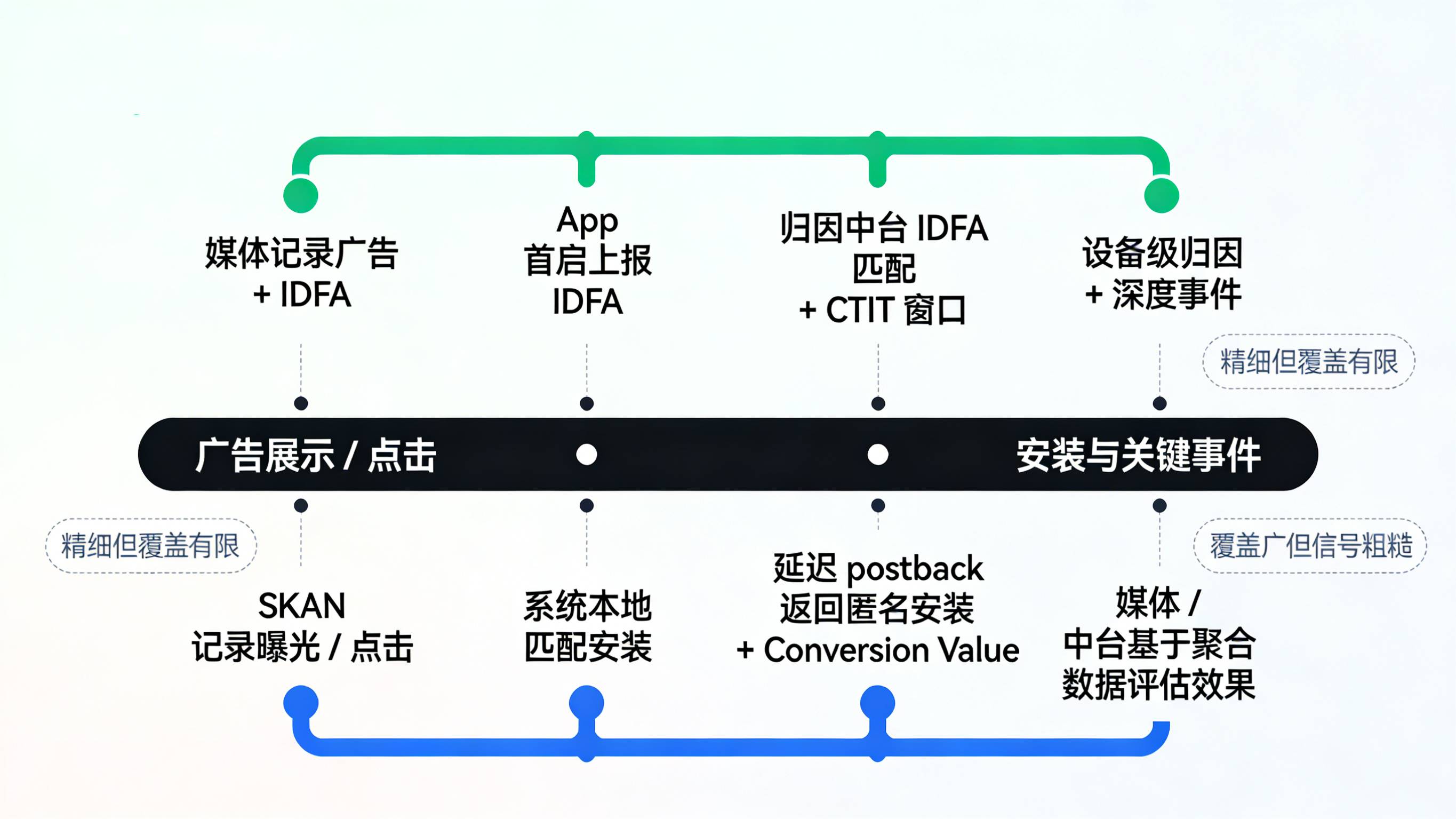
在用户同意 ATT 授权的前提下,iOS 渠道统计依然可以沿用经典的“展示/点击 → 安装 → 深度事件”的确定性归因链路,只不过需要更精细地管控时间窗口和口径。以一次标准的 iOS 买量为例,链路大致可以拆解为几个关键步骤。步骤一:媒体侧埋点。在信息流或插屏广告展示时,媒体 SDK 会记录当前广告展示所关联的 Campaign、Adset、Creative 等元信息,以及当前设备的 IDFA、系统版本号、设备型号等参数,并在本地或服务端持久化。步骤二:点击与上报。当用户点击该广告时,媒体 SDK 会立即将点击事件打点上报给媒体服务器,日志中包含前述广告元数据和设备 IDFA、UA、IP 等环境特征;如接入了第三方归因中台,媒体也会按统一协议将同样的点击事件推送给中台。
步骤三:App 首启与激活上报。当用户在 App Store 中下载完目标 App 并首次打开时,集成了归因 SDK 的 App 会在 application:didFinishLaunchingWithOptions:、scene:willConnectToSession: 等生命周期回调中,由 SDK 侧主动读取当前设备的 IDFA(前提是已获 ATT 授权),同时采集操作系统微版本号、设备型号、语言时区等补充特征,并构造一条“激活上报”请求发送到归因中台。步骤四:服务端归因匹配。归因中台在高并发内存数据库中搜索与该 IDFA 对应的最近一次有效点击记录,并结合“点击到安装时间差”(CTIT)是否处于预设窗口、是否存在其他更近的竞争点击等规则,计算出最终归因对象,通常采用“最后一次有效点击”作为安装的归属方。完成匹配后,中台会分别向媒体和广告主侧回传结果,媒体用来结算,广告主持久化到内部 BI 进行后续留存与 LTV 分析。从这条链路可以看到,在授权用户群体内,iOS 渠道统计在原理上与 Android 差别并不大,核心问题并不在于“做不到”,而是这一套精细统计默认只能覆盖授权那一小撮用户。
未授权场景:基于 SKAdNetwork 的聚合归因与报表限制
当用户拒绝 ATT 授权时,IDFA 这条确定性归因通路被彻底关死,苹果提供的唯一“合法”替代方案就是 SKAdNetwork。与依赖 IDFA 的链路截然不同,SKAN 完全由 Apple 作为“中间裁判”负责连接媒体和目标 App,且默认以匿名、聚合、延迟回传的方式输出效果数据。其大致的数据流转可理解为这样一条时序链路:步骤一,在媒体 App 中展示或点击广告时,媒体 SDK 向 Apple 的 SKAN 服务登记一次广告曝光或点击,记录广告标识和目标 App 信息,但不会将设备 ID、IP 或 UA 等可识别信息暴露给外部。步骤二,用户在归因窗口内前往 App Store 下载并安装目标 App,在安装或首次启动时,系统会在本地对这次安装是否与此前登记过的 SKAN 广告记录匹配进行评估。步骤三,在经过一定随机延迟(出于隐私原因避免精确时间对齐)之后,Apple 服务器会向媒体或配置好的第三方归因方发送一条 postback,告知“某个广告系列在某个时间段贡献了 N 次安装,同时携带一个受限的转化值(Conversion Value)”。整个过程不涉及 IDFA,也不对广告主暴露设备级明细。
这一机制带来几项关键限制。首先是延迟:SKAN 并非实时归因,安装到 postback 的间隔可能在数十小时到数天不等,这意味着 iOS 渠道报表天然缺乏秒级、分级的实时性,优化师无法像在 Android 那样“看着实时激活曲线即时调价”。其次是维度粗糙:出于隐私保护考虑,SKAN 的回传字段极为有限,媒体方和第三方只能在 Campaign 或 Source Identifier 等有限维度上拆解数据,很难对长尾子渠道、创意级别做精细评估。再次是匿名阈值:当某个广告系列在统计周期内的安装量过少时,为避免“单个 postback 就暴露了用户行为”,苹果会直接屏蔽对应转化值或回传,使得小体量投放往往“打了也看不太清楚效果”。对于这些机制的更多技术细节与版本演进,可以参考如《》等业界深度文章的系统解读,它们对多窗口回传、隐私阈值和 Conversion Value 策略提供了大量实践经验。
补偿思路:第一方数据 + 建模归因 + 级联策略
在无法也不应该绕过 ATT 和 SKAN 的前提下,真正成熟的团队会把重心转向“合规空间内的补偿和重构”。第一条路是夯实第一方数据基础,把内部的帐号体系、手机号、会员ID、订单号等企业自有 ID 当作增长分析的基石,而不是一味执着于设备 ID。即便在未授权用户人群中,业务侧依然可以基于帐号登录、注册时间、付费记录、功能使用轨迹等维度,对“来自某个渠道的人群在长期 LTV 上是否优于另一渠道”做出相对可信的判断,而不必非要知道每一台设备究竟是通过哪一次点击转化的。第二条路是采用“样本建模”的思路,将那部分授权且可用 IDFA 的用户当作完整链路样本,先在这一群体内完成“渠道 → 行为 → LTV”关系的建模,再结合 SKAN 的聚合数据,把这种关系外推到更大范围的人群上;虽然这不是精确的 1:1 归因,但在统计意义上可以极大缓解“看不清”的焦虑。第三条路则是通过第三方归因中台做多源数据的汇聚与级联:一端接入媒体侧的日志与 SKAN 回传,一端结合 App 内部 SDK 埋点和服务器事件,再将结果整合输出给内部数据仓库与 BI 系统,帮业务方把“ATT + SKAN + ASA + 内部事件”的复杂组合,抽象成一套统一的指标与视图。以 openinstall 为例,其在公开案例《》中,就展示了在 ATT 时代如何通过中台接入多端事件、统一归因视角,并在此基础上叠加跨端唤起与传参能力,形成完整的 iOS 增长数据底座。
指标体系与技术评估框架
iOS 渠道统计三层指标:授权率 / SKAN 覆盖 / 业务闭环
在 Android 时代,很多团队习惯于围绕“曝光 → 点击 → 激活 → 注册/付费”搭建统一的转化漏斗,而在 iOS 世界里,如果依然沿用完全相同的一套指标体系,很容易忽略 ATT 和 SKAN 带来的结构性断层。更合理的做法是先从“信号可见性”出发,将 iOS 渠道统计拆成三层。顶层是 ATT 授权率,它决定了你能在多大程度上使用 IDFA 做传统意义上的设备级归因;这一指标不仅要看整体值,还要按渠道、广告形式、素材类型做拆解,因为不同渠道和素材在用户眼中的“信任感”和“被打扰感”截然不同。中层是 SKAN 安装覆盖率与转化值填充率,这反映了匿名归因链路是否稳定可用:如果某些媒体或 Campaign 的 SKAN 回传长期缺失、转化值大量为 null,说明这条路实际上是“断的”,再怎么看媒体自家报表也很难还原真实效果。底层则是围绕注册、激活、关键业务事件(如绑卡、首充、首单)的业务闭环指标,这一层需要分别在“授权 cohort”和“未授权 cohort”上计算,并对比它们的行为分布是否存在本质差异,以便评估基于样本建模的可行性。

报表拆解维度:媒体 vs 归因中台 vs 内部 BI
理解 iOS 渠道统计的限制,另一个关键是建立一套标准化的“多口径对账维度”。很多团队在实际排查中,只是笼统地说“媒体多、MMP 少、内部 BI 更少”,却没有进一步拆解这三者到底是在哪些维度上发生了分歧。要做到可重复的诊断,至少需要从以下几方面着手:其一是归因窗口的配置差异,媒体往往以 7 天或更短的点击归因窗口计算 install,而归因中台和内部 BI 可能采用 30 天甚至更长的观察期;其二是去重策略的不同,媒体通常按设备或 IDFA 维度去重,而内部 BI 可能按帐号或手机号维度去重,一台设备上的多个帐号可能在媒体眼里只有一次 install,却在 BI 中被拆成多个新客;其三是延迟补录逻辑,部分深度事件(如大额付费、实名审批)会在 install 数日后才产生,对它们的归因和入账时机,三方系统可能有完全不同的口径,需要明确“按发生日还是按 install 日记账”;其四是 SKAN 聚合数据在媒体和 MMP 之间的还原方式,即便收到了同一批 postback,不同平台在拆分 Source Identifier、映射 Campaign 时的策略也可能不同。只有把这些维度逐一对齐,才能在“看起来差很多”的表象背后,找出差异真正来自哪一层。
技术诊断案例(四步法):iOS 渠道数据对不上该如何拆解
异常现象与排查背景
某工具类 App 在完成 Android 端的归因体系建设后,开始加大 iOS 买量投入,并在多个信息流平台和搜索广告上同步开跑。上线一周后,运营团队拿到的三份报表呈现出典型的“倒三角”形态:媒体后台显示某渠道带来了 1 万次激活,第三方归因中台报表显示只有约 6000 次 iOS install,而内部 BI 统计的 iOS 新增注册用户数则只有 4000 多。业务方一眼看去觉得“都对不上”,而且这种对不上的情况几乎发生在所有 iOS 渠道上,而 Android 部分却基本一致。财务部门因此难以确定结算依据,技术团队也很难判断是埋点丢数、网络抖动,还是苹果隐私框架造成的数据撕裂。
日志与链路对账:从 ATT 授权率到 SKAN 回传
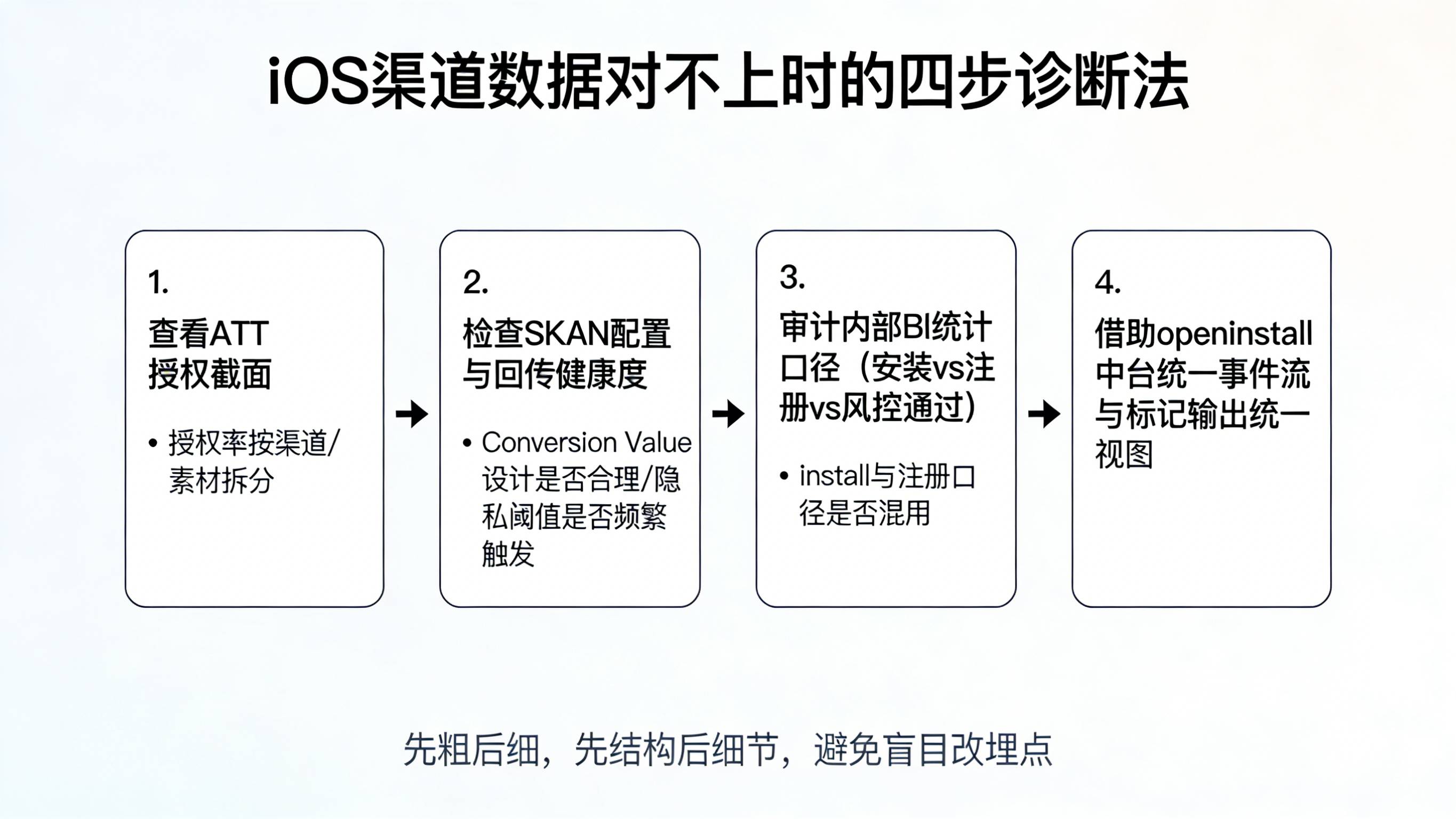
数据架构师介入后,并没有立刻钻进 SDK 日志和网络抓包,而是先从宏观结构入手,按“先粗后细”的原则逐层拆解。第一步是拉取 iOS 端的 ATT 授权情况,结果发现整体授权率只有大约三成,而第三方归因中台的 install 统计恰好主要建立在 IDFA 精确匹配基础之上,这意味着中台看到的只是那 30% 左右授权用户中的安装子集,天然会低于媒体基于全量点击的估算。第二步是检查 SKAN 的配置与回传质量,发现部分媒体虽然宣称已支持 SKAN 4.0,但实际上广告主在配置 Conversion Value 时过于保守,导致大量 install 虽然发生了,但回传中要么缺失转化值,要么被隐私阈值吞掉,第三方归因端能用的数据远少于媒体后台自家能看到的聚合指标;这一点在参考了《iOS SKAN 4.0 时代的广告追踪优化:掌握隐私友好的营销策略》等实践文章后,得到了更加系统的印证。第三步则是对内部 BI 的统计口径进行审计,确认 BI 在 iOS 新增中默认只统计“完成注册且通过了风控”的用户,将未完成注册或被风控拦截的帐号排除在外,而第三方归因中台的 install 口径则更偏向于“首启”,不关心用户是否注册成功,这自然会让 BI 的数字再次低于中台。
技术调优介入:重构 iOS 统计与风控联动
在定位出问题主要集中在“ATT 授权结构不清晰 + SKAN 配置不合理 + 内外口径未统一”之后,团队开始分三个方向做技术调优。首先,与产品和设计配合,优化 iOS 端 ATT 授权弹窗的出现时机和说明文案,避免在用户首次打开 App、尚未建立信任感时就硬弹授权提示,而是选择在用户完成首次关键操作(如浏览完新手引导、同意隐私协议)后,再解释授权的价值与用途,从而温和地提升授权率。其次,统一由归因中台负责管理各媒体的 SKAN 配置,将 Conversion Value 从“只标记 install”升级为“标记早期关键行为组合”,同时避免过细的拆分导致样本被稀释到隐私阈值之下;在这一步,团队参考了前述 SKAN 4.0 相关实践文章,对 CV 的窗口划分和事件映射做了系统梳理,并将经验固化到统一配置模板中。最后,在内部 BI 层面,将原本混在一起的 iOS install 指标拆分为三条曲线:基于 IDFA 的授权 cohort、基于 SKAN 的未授权 cohort,以及最终通过风控的注册 cohort,并由 openinstall 这类中台提供统一的事件流和标记,让业务方在一个看板上就能同时看到三类数据的结构关系,而不再是“只看一条线然后困惑它为何总比另一条小”。
在这一过程中,团队还直接参考了 openinstall 公布的实践案例《》,学习如何在 ATT 与 SKAN 约束下,通过 openinstall 这样的归因中台,将“跨端唤起 + 传参安装 + 渠道统计”整合成统一的能力栈,并在此基础上叠加风控规则,既保证数据可用,又不触碰苹果的隐私红线。
复盘结果与经验沉淀
经过两轮迭代之后,新的 iOS 统计体系开始稳定运行。随着 ATT 授权率的温和提升与 SKAN 配置的统一,媒体后台与第三方归因之间的差异从最初动辄 40% 以上的巨大落差,逐渐收敛到一个可解释的、与授权结构和口径差异相匹配的区间;内部 BI 在拆分出注册口径之后,也能够清楚地向业务说明“为什么 install 比注册多”、“哪些渠道带来的 install 虽多但注册转化很差”,从而把“对不上”变成一个可讨论、可优化的分析话题,而不是无穷无尽的扯皮。项目组最终沉淀出一套固定 SOP:任何 iOS 渠道复盘一旦发现数据异常,先看 ATT 授权截面,再看 SKAN 回传健康度,最后再检查内部 BI 的统计口径,逐层排除可能原因。这套 SOP 也成为后续新成员快速理解 iOS 统计限制与补偿空间的入门教材。
常见问题
为什么 iOS 渠道统计总是和广告平台 / 归因中台 / 内部 BI 对不上?
根本原因不在于哪一方“算错了”,而在于三方统计的“对象”和“口径”天然不同。媒体后台的 install 数往往基于曝光和点击日志,按自家预设的归因窗口和模型对全量流量做估算;归因中台在 ATT 框架下,能对授权用户做精确的 IDFA 设备级归因,对未授权用户则需要依赖 SKAN 的聚合数据,两部分合在一起才构成“归因 install”;内部 BI 则通常只统计那些完成注册、通过风控、甚至发生了交易或付费的用户,天然是一个更窄、更靠后漏斗的口径。如果不先从 ATT 授权率、SKAN 覆盖率和业务闭环这三个层面拆开看,而是一上来就把三套数字放在一起比大小,只会感觉“谁都不准”,却很难看到它们各自在链路上的意义与边界。
在 ATT 框架下还能不能用设备指纹做 iOS 渠道统计?
从合规和审核的角度出发,答案必须非常谨慎。苹果在隐私政策和审核规范中明确反对跨 App 的“指纹追踪”,即禁止开发者通过 IP 地址、User-Agent、操作系统微版本、设备分辨率等一系列表面上看似“匿名”的环境特征,在多个应用之间拼接用户路径。如果这种做法被判定为规避 ATT 的“暗度陈仓”,极有可能导致应用被拒审乃至下架。因此,在 iOS 端做渠道统计时,应该将此类环境特征更多用于安全风控(例如识别明显异常的作弊模式),而不是当作规避 ATT 的归因主轴。真正合规的做法是:在用户同意授权的范围内用好 IDFA,在未授权范围内尊重 SKAN 的匿名与聚合特性,并在第一方数据和统计建模层面寻求“可用、但不越界”的补偿方案。
iOS 投放体量不大,还有必要接入 SKAdNetwork 吗?
即便整体投放体量不算庞大,只要你的 iOS 流量中存在大比例的未授权 ATT 用户,SKAdNetwork 依然是唯一被苹果官方认可的归因机制。对于小体量广告主来说,接入 SKAN 的确需要投入一定的产品和技术成本,理解窗口期、Conversion Value 映射、隐私阈值等概念也有学习门槛,但这套机制至少能在“匿名但可用”的前提下,给出一个相对可信的效果轮廓。相比完全依赖媒体自家报表、或仅凭内部 install 走势“凭感觉”调整预算,基于 SKAN 的统计虽然不完美,却能够帮你掌握“哪个 Campaign 在粗粒度层面更有潜力”、“哪些素材在早期互动和留存上明显偏强”这类关键信息,为后续是否进一步扩大投放、是否需要更细粒度拆组提供依据。